
{kind=link}
On this tutorial, we’ll discover the best way to analyze massive textual content datasets with LangChain and Python to seek out fascinating information in something from books to Wikipedia pages.
AI is such an enormous subject these days that OpenAI and libraries like LangChain barely want any introduction. However, in case you’ve been misplaced in an alternate dimension for the previous 12 months or so, LangChain, in a nutshell, is a framework for creating functions powered by language fashions, permitting builders to make use of the ability of LLMs and AI to research information and construct their very own AI apps.
Use Circumstances
Earlier than moving into all of the technicalities, I feel it’s good to take a look at some use instances of textual content dataset evaluation utilizing LangChain. Listed here are some examples:
- Systematically extracting helpful information from lengthy paperwork.
- Visualizing traits inside a textual content or textual content dataset.
- Making summaries for lengthy and uninteresting texts.
Conditions
To comply with together with this text, create a brand new folder and set up LangChain and OpenAI utilizing pip:
pip3 set up langchain openai
File Studying, Textual content Splitting and Information Extraction
To research massive texts, similar to books, you should cut up the texts into smaller chunks. It is because massive texts, similar to books, include a whole lot of 1000’s to hundreds of thousands of tokens, and contemplating that no LLM can course of that many tokens at a time, there’s no method to analyze such texts as a complete with out splitting.
Additionally, as a substitute of saving particular person immediate outputs for every chunk of a textual content, it’s extra environment friendly to make use of a template for extracting information and placing it right into a format like JSON or CSV.
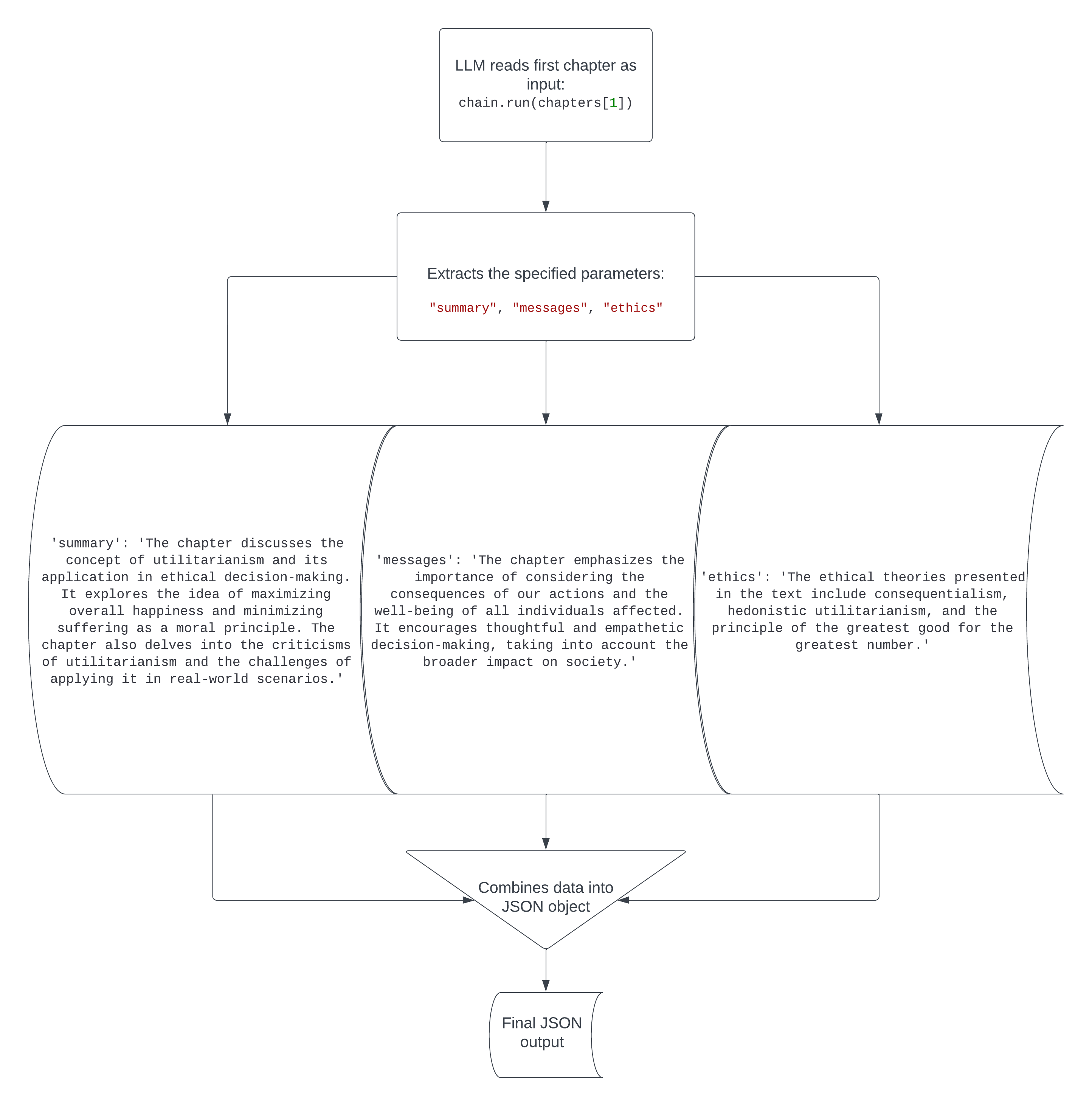
On this tutorial, I’ll be utilizing JSON. Right here is the e book that I’m utilizing for this instance, which I downloaded totally free from Undertaking Gutenberg. This code reads the e book Past Good and Evil by Friedrich Nietzsche, splits it into chapters, makes a abstract of the primary chapter, extracts the philosophical messages, moral theories and ethical ideas introduced within the textual content, and places all of it into JSON format.
As you’ll be able to see, I used the “gpt-3.5-turbo-1106” mannequin to work with bigger contexts of as much as 16000 tokens and a 0.3 temperature to provide it a little bit of creativity. You’ll be able to experiment with the temperature and see what works greatest together with your use case.
Word: the temperature parameter determines the liberty of an LLM to make inventive and typically random solutions. The decrease the temperature, the extra factual the LLM output, and the upper the temperature, the extra inventive and random the LLM output.
The extracted information will get put into JSON format utilizing create_structured_output_chain and the offered JSON schema:
json_schema = {
"sort": "object",
"properties": {
"abstract": {"title": "Abstract", "description": "The chapter abstract", "sort": "string"},
"messages": {"title": "Messages", "description": "Philosophical messages", "sort": "string"},
"ethics": {"title": "Ethics", "description": "Moral theories and ethical ideas introduced within the textual content", "sort": "string"}
},
"required": ["summary", "messages", "ethics"],
}
chain = create_structured_output_chain(json_schema, llm, immediate, verbose=False)
The code then reads the textual content file containing the e book and splits it by chapter. The chain is then given the primary chapter of the e book as textual content enter:
f = open("texts/Past Good and Evil.txt", "r")
phi_text = str(f.learn())
chapters = phi_text.cut up("CHAPTER")
print(chain.run(chapters[1]))
Right here’s the output of the code:
{'abstract': 'The chapter discusses the idea of utilitarianism and its utility in moral decision-making. It explores the thought of maximizing total happiness and minimizing struggling as an ethical precept. The chapter additionally delves into the criticisms of utilitarianism and the challenges of making use of it in real-world eventualities.', 'messages': 'The chapter emphasizes the significance of contemplating the results of our actions and the well-being of all people affected. It encourages considerate and empathetic decision-making, considering the broader influence on society.', 'ethics': 'The moral theories introduced within the textual content embody consequentialism, hedonistic utilitarianism, and the precept of the best good for the best quantity.'}
Fairly cool. Philosophical texts written 150 years in the past are fairly arduous to learn and perceive, however this code immediately translated the details from the primary chapter into an easy-to-understand report of the chapter’s abstract, message and moral theories/ethical ideas. The flowchart under will provide you with a visible illustration of what occurs on this code.
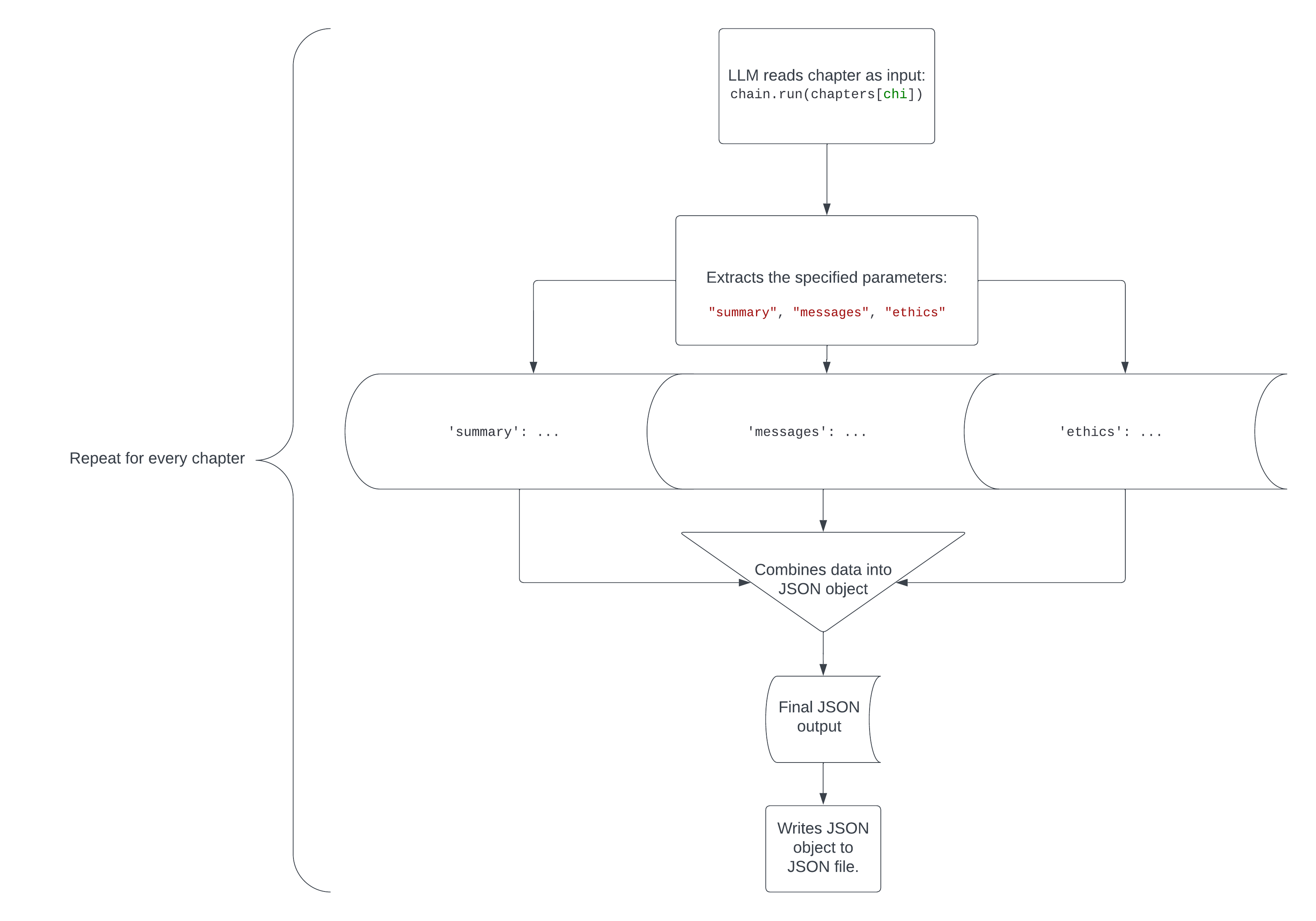
Now you are able to do the identical for all of the chapters and put all the things right into a JSON file utilizing this code.
I added time.sleep(20) as feedback, because it’s attainable that you just’ll hit charge limits when working with massive texts, more than likely when you have the free tier of the OpenAI API. Since I feel it’s helpful to know what number of tokens and credit you’re utilizing together with your requests in order to not unintentionally drain your account, I additionally used with get_openai_callback() as cb: to see what number of tokens and credit are used for every chapter.
That is the a part of the code that analyzes each chapter and places the extracted information for every in a shared JSON file:
for chi in vary(1, len(chapters), 1):
with get_openai_callback() as cb:
ch = chain.run(chapters[chi])
print(cb)
print("n")
print(ch)
print("nn")
json_object = json.dumps(ch, indent=4)
if chi == 1:
with open("Past Good and Evil.json", "w") as outfile:
outfile.write("[n"+json_object+",")
elif chi < len(chapters)-1:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+",")
else:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+"n]")
The chi index begins at 1, as a result of there’s no chapter 0 earlier than chapter 1. If the chi index is 1 (on the primary chapter), the code writes (overwrites any current content material) the JSON information to the file whereas additionally including a gap sq. bracket and new line in the beginning, and a comma on the finish to comply with JSON syntax. If chi shouldn’t be the minimal worth (1) or most worth (len(chapters)-1), the JSON information simply will get added to the file together with a comma on the finish. Lastly, if chi is at its most worth, the JSON will get added to the JSON file with a brand new line and shutting sq. bracket.
After the code finishes operating, you’ll see that Past Good and Evil.json is stuffed with the extracted information from all of the chapters.
Right here’s a visible illustration of how this code works.
Working With A number of Recordsdata
You probably have dozens of separate information that you just’d like to research one after the other, you should use a script just like the one you’ve simply seen, however as a substitute of iterating by means of chapters, it’s going to iterate by means of information in a folder.
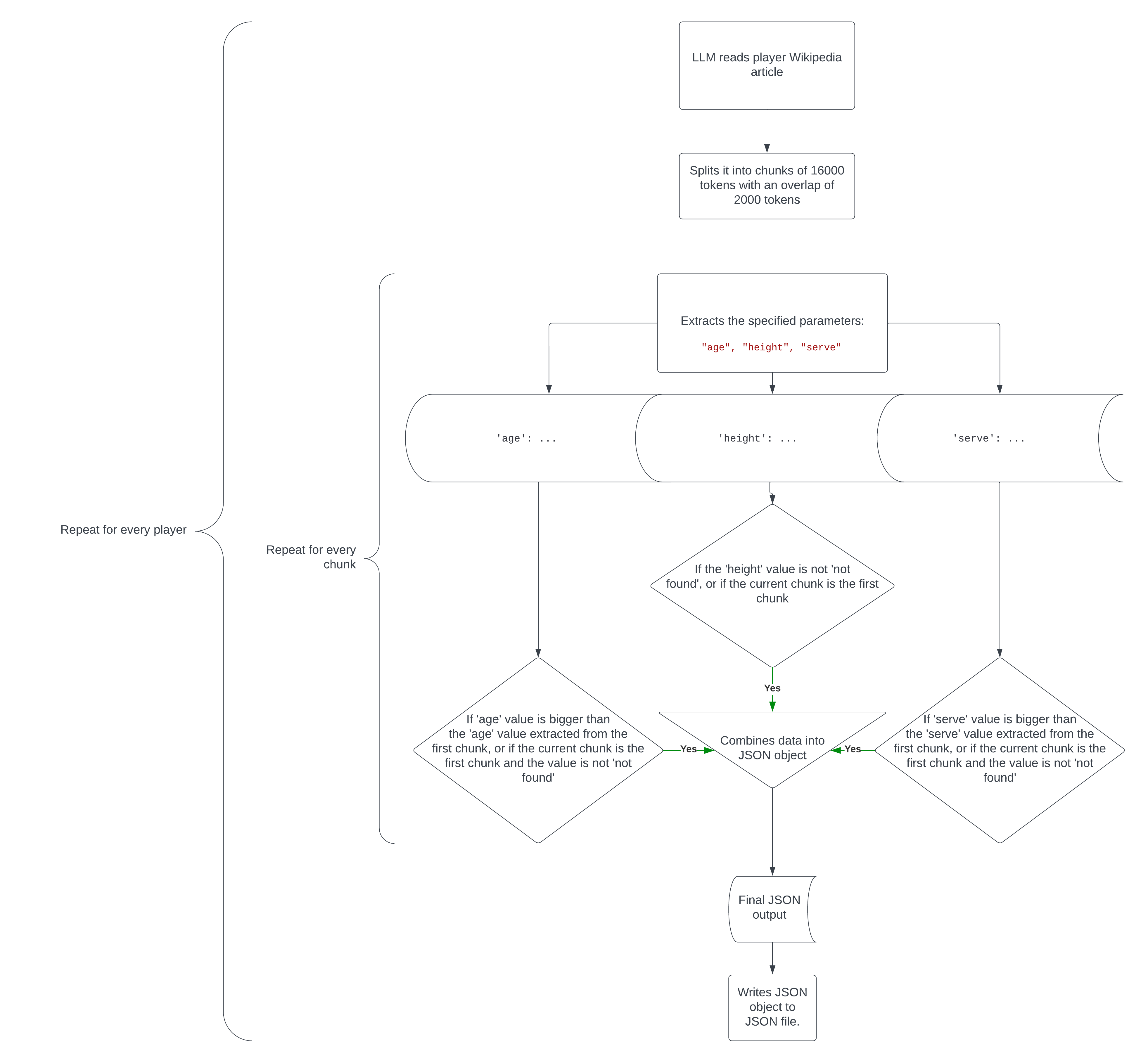
I’ll use the instance of a folder stuffed with Wikipedia articles on the highest 10 ranked tennis gamers (as of December 3 2023) referred to as top_10_tennis_players. You’ll be able to obtain the folder right here. This code will learn every Wikipedia article, extract every participant’s age, peak and quickest serve in km/h and put the extracted information right into a JSON file in a separate folder referred to as player_data.
Right here’s an instance of an extracted participant information file.

Nevertheless, this code isn’t that straightforward (I want it was). To effectively and reliably extract essentially the most correct information from texts which can be typically too massive to research with out chunk splitting, I used this code:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=16000,
chunk_overlap=2000,
length_function=len,
add_start_index=True,
)
sub_texts = text_splitter.create_documents([player_text])
ch = []
for ti in vary(len(sub_texts)):
with get_openai_callback() as cb:
ch.append(chain.run(sub_texts[ti]))
print(ch[-1])
print(cb)
print("n")
for chi in vary(1, len(ch), 1):
if (ch[chi]["age"] > ch[0]["age"]) or (ch[0]["age"] == "not discovered" and ch[chi]["age"] != "not discovered"):
ch[0]["age"] = ch[chi]["age"]
break
if (ch[chi]["serve"] > ch[0]["serve"]) or (ch[0]["serve"] == "not discovered" and ch[chi]["serve"] != "not discovered"):
ch[0]["serve"] = ch[chi]["serve"]
break
if (ch[0]["height"] == "not discovered") and (ch[chi]["height"] != "not discovered"):
ch[0]["height"] = ch[chi]["height"]
break
else:
proceed
In essence, this code does the next:
- It splits the textual content into chunks 16000 tokens in measurement, with a piece overlap of 2000 to maintain a little bit of context.
- it extracts the required information from every chunk.
- If the info extracted from the most recent chunk is extra related or correct than that of the primary chunk (or the worth isn’t discovered within the first chunk however is discovered within the newest chunk), it adjusts the values of the primary chunk. For instance, if chunk 1 says
'age': 26and chunk 2 says'age': 27, theageworth will get up to date to 27 since we’d like the participant’s newest age, or if chunk 1 says'serve': 231and chunk 2 says'serve': 232, theserveworth will get up to date to 232 since we’re in search of the quickest serve velocity.
Right here’s how the entire code works in a flowchart.
Textual content to Embeddings
Embeddings are vector lists which can be used to affiliate items of textual content with one another.
A giant side of textual content evaluation in LangChain is looking massive texts for particular chunks which can be related to a sure enter or query.
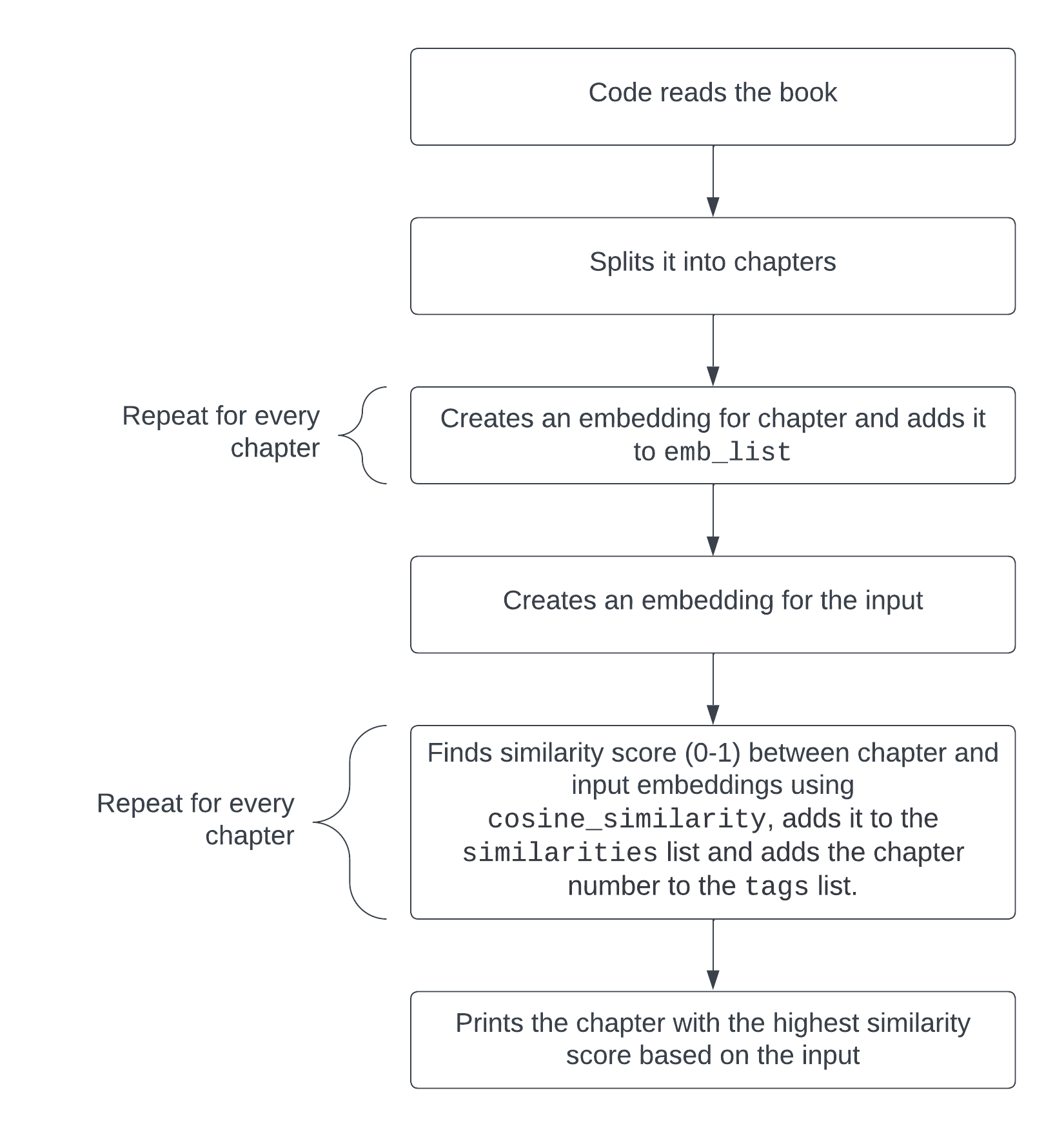
We are able to return to the instance with the Past Good and Evil e book by Friedrich Nietzsche and make a easy script that takes a query on the textual content like “What are the failings of philosophers?”, turns it into an embedding, splits the e book into chapters, turns the totally different chapters into embeddings and finds the chapter most related to the inquiry, suggesting which chapter one ought to learn to seek out a solution to this query as written by the writer. You’ll find the code to do that right here. This code specifically is what searches for essentially the most related chapter for a given enter or query:
embedded_question = embeddings_model.embed_query("What are the failings of philosophers?")
similarities = []
tags = []
for i2 in vary(len(emb_list)):
similarities.append(cosine_similarity(emb_list[i2], embedded_question))
tags.append(f"CHAPTER {i2}")
print(tags[similarities.index(max(similarities))])
The embeddings similarities between every chapter and the enter get put into a listing (similarities) and the variety of every chapter will get put into the tags listing. Probably the most related chapter is then printed utilizing print(tags[similarities.index(max(similarities))]), which will get the chapter quantity from the tags listing that corresponds to the utmost worth from the similarities listing.
Output:
CHAPTER 1
Right here’s how this code works visually.
Different Utility Concepts
There are numerous different analytical makes use of for big texts with LangChain and LLMs, and although they’re too advanced to cowl on this article of their entirety, I’ll listing a few of them and description how they are often achieved on this part.
Visualizing matters
You’ll be able to, for instance, take transcripts of YouTube movies associated to AI, like those in this dataset, extract the AI associated instruments talked about in every video (LangChain, OpenAI, TensorFlow, and so forth), compile them into a listing, and discover the general most talked about AI instruments, or use a bar graph to visualise the recognition of every one.
Analyzing podcast transcripts
You’ll be able to take podcast transcripts and, for instance, discover similarities and variations between the totally different company by way of their opinions and sentiment on a given subject. You may also make an embeddings script (just like the one on this article) that searches the podcast transcripts for essentially the most related conversations primarily based on an enter or query.
Analyzing evolutions of stories articles
There are many massive information article datasets on the market, like this one on BBC information headlines and descriptions and this one on monetary information headlines and descriptions. Utilizing such datasets, you’ll be able to analyze issues like sentiment, matters and key phrases for every information article. You’ll be able to then visualize how these features of the information articles evolve over time.
Conclusion
I hope you discovered this beneficial and that you just now have an concept of the best way to analyze massive textual content datasets with LangChain in Python utilizing totally different strategies like embeddings and information extraction. Better of luck in your LangChain tasks!