
{kind=link}
Introduction
When attending a job interview or hiring for a big firm, reviewing each CV intimately is commonly impractical as a result of excessive quantity of candidates. As an alternative, leveraging CV knowledge extraction to give attention to how effectively key job necessities align with a candidate’s CV can result in a profitable match for each the employer and the candidate.
Think about having your profile label checked—no want to fret! It’s now straightforward to evaluate your match for a place and establish any gaps in your {qualifications} relative to job necessities.
For instance, if a job posting highlights expertise in undertaking administration and proficiency in a selected software program, the candidate ought to guarantee these abilities are clearly seen on their CV. This focused method helps hiring managers rapidly establish certified candidates and ensures the candidate is taken into account for positions the place they will thrive.
By emphasizing probably the most related {qualifications}, the hiring course of turns into extra environment friendly, and each events can profit from a very good match. The corporate finds the correct expertise extra rapidly, and the candidate is extra prone to land a job that matches their abilities and expertise.
Studying Outcomes
- Perceive the significance of information extraction from CVs for automation and evaluation.
- Achieve proficiency in utilizing Python libraries for textual content extraction from numerous file codecs.
- Learn to preprocess pictures to reinforce textual content extraction accuracy.
- Discover strategies for dealing with case sensitivity and normalizing tokens in extracted textual content.
- Determine key instruments and libraries important for efficient CV knowledge extraction.
- Develop sensible abilities in extracting textual content from each pictures and PDF information.
- Acknowledge the challenges concerned in CV knowledge extraction and efficient options.
This text was printed as part of the Knowledge Science Blogathon.
To successfully extract knowledge from resumes and CVs, leveraging the correct instruments is important for streamlining the method and guaranteeing accuracy. This part will spotlight key libraries and applied sciences that improve the effectivity of CV knowledge extraction, enabling higher evaluation and insights from candidate profiles.
Python
It has a library or technique that may cut up sentences or paragraph into phrases. In Python, you possibly can obtain phrase tokenization utilizing completely different libraries and strategies, resembling cut up() (primary tokenization) or the Pure Language Toolkit (NLTK) and spaCy libraries for extra superior tokenization.
Easy tokenization( cut up of sentences) don’t acknowledge punctuations and different particular characters.
sentences="In the present day is a ravishing day!."
sentences.cut up()
['Today', 'is', 'a', 'beautiful', 'day!.']Libraries: NLTK and SpaCy
Python has extra highly effective device for tokenization (Pure Language Toolkit (NLTK).
In NLTK (Pure Language Toolkit), the punkt tokenizer actively tokenizes textual content through the use of a pre-trained mannequin for unsupervised sentence splitting and phrase tokenization.
import nltk
nltk.obtain('punkt')
from nltk import word_tokenize
sentences="In the present day is a ravishing day!."
sentences.cut up()
print(sentences)
phrases= word_tokenize(sentences)
print(phrases)
[nltk_data] Downloading bundle punkt to
[nltk_data] C:Usersss529AppDataRoamingnltk_data...
In the present day is a ravishing day!.
['Today', 'is', 'a', 'beautiful', 'day', '!', '.']
[nltk_data] Bundle punkt is already up-to-date!Key Options of punkt:
- It might tokenize a given textual content into sentences and phrases without having any prior details about the language’s grammar or syntax.
- It makes use of machine studying fashions to detect sentence boundaries, which is helpful in languages the place punctuation doesn’t strictly separate sentences.
SpaCy is superior NLP library that provides correct tokenization and different language processing options.
Common Expressions: Customized tokenization primarily based on patterns, however requires handbook set.
import re
common= "[A-za-z]+[W]?"
re.findall(common, sentences)
['Today ', 'is ', 'a ', 'beautiful ', 'day!']Pytesseract
It’s a python primarily based optical character recognition device used for studying textual content in pictures.
Pillow Library
An open-source library for dealing with numerous picture codecs, helpful for picture manipulation.
Photos or PDF Recordsdata
Resumes could also be in PDF or picture codecs.
PDFPlumber or PyPDF2
To extract textual content from a PDF and tokenize it into phrases, you possibly can observe these steps in Python:
- Extract textual content from a PDF utilizing a library like PyPDF2 or pdfplumber.
- Tokenize the extracted textual content utilizing any tokenization technique, resembling cut up(), NLTK, or spaCy.
Getting Phrases from PDF Recordsdata or Photos
For pdf information we are going to want Pdf Plumber and for pictures OCR.
If you wish to extract textual content from a picture (as a substitute of a PDF) after which tokenize and rating primarily based on predefined phrases for various fields, you possibly can obtain this by following these steps:
Set up pytesseract OCR Machine.
It’s going to assist to extract textual content from pictures
pip set up pytesseract Pillow nltkSet up library Pillow
It’s going to assist to deal with numerous pictures.
Relating to picture processing and manipulation in Python—resembling resizing, cropping, or changing between completely different codecs—the open-source library that usually involves thoughts is Pillow.
Let’s see how the pillow works, to see the picture in Jupyter Pocket book I’ve to make use of the show and inside brackets need to retailer the variable holding the picture.
from PIL import Picture
picture = Picture.open('artwork.jfif')
show(picture)
To resize and save the picture, the resize and saved technique is used, the width is about to 400 and the peak to 450.
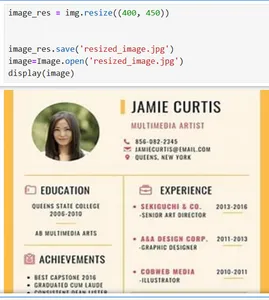
Key Options of Pillow:
- Picture Codecs- Assist completely different codecs
- Picture Manipulation Features – One can resize, crop pictures, convert shade pictures to grey, and so on.
Set up nltk for tokenization (or spaCy)
Uncover methods to improve your textual content processing capabilities by putting in NLTK or spaCy, two highly effective libraries for tokenization in pure language processing.
Obtain Tesseract and Configure Path
Learn to obtain Tesseract from GitHub and seamlessly combine it into your script by including the required path for optimized OCR performance.
pytesseract.pytesseract.tesseract_cmd = 'C:Program FilesTesseract-OCRtesseract.exe''- macOS: brew set up tesseract
- Linux: Set up through bundle supervisor (e.g., sudo apt set up tesseract-ocr).
- pip set up pytesseract Pillow
There are a number of instruments amongst them one is the Google-developed, open-source library Tesseract which has supported many languages and OCR.
Pytesseract is used for Python-based initiatives, that act as a wrapper for Tesseract OCR engine.
Picture and PDF Textual content Extraction Methods
Within the digital age, extracting textual content from pictures and PDF information has grow to be important for numerous purposes, together with knowledge evaluation and doc processing. This text explores efficient strategies for preprocessing pictures and leveraging highly effective libraries to reinforce optical character recognition (OCR) and streamline textual content extraction from various file codecs.
Preprocessing Photos for Enhanced OCR Efficiency
Preprocessing pictures can enhance the OCR efficiency by following the steps talked about beneath.
- Photos to Grayscale: Photos are transformed into grayscale to cut back noisy background and have a agency give attention to the textual content itself, and is helpful for pictures with various lighting circumstances.
- from PIL import ImageOps
- picture = ImageOps.grayscale(picture)
- Thresholding : Apply binary thresholding to make the textual content stand out by changing the picture right into a black-and-white format.
- Resizing : Upscale smaller pictures for higher textual content recognition.
- Noise Removing : Take away noise or artifacts within the picture utilizing filters (e.g., Gaussian blur).
import nltk
import pytesseract
from PIL import Picture
import cv2
from nltk.tokenize import word_tokenize
nltk.obtain('punkt')
pytesseract.pytesseract.tesseract_cmd = r'C:Usersss529anaconda3Tesseract-OCRtesseract.exe'
picture = enter("Identify of the file: ")
imag=cv2.imread(picture)
#convert to grayscale picture
grey=cv2.cvtColor(pictures, cv2.COLOR_BGR2GRAY)
from nltk.tokenize import word_tokenize
def text_from_image(picture):
img = Picture.open(imag)
textual content = pytesseract.image_to_string(img)
return textual content
picture="CV1.png"
text1 = text_from_image(picture)
# Tokenize the extracted textual content
tokens = word_tokenize(text1)
print(tokens)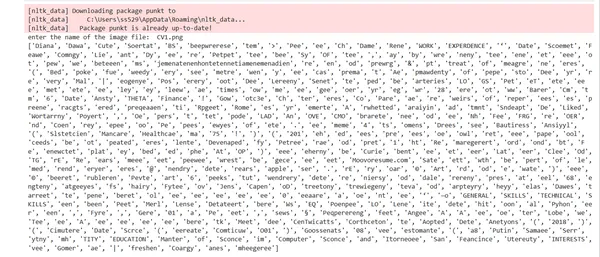
To know what number of phrases match the necessities we are going to evaluate and provides factors to each matching phrase as 10.
# Evaluating tokens with particular phrases, ignore duplicates, and calculate rating
def compare_tokens_and_score(tokens, specific_words, score_per_match=10):
match_words = set(phrase.decrease() for phrase in tokens if phrase.decrease() in specific_words)
total_score = len(fields_keywords) * score_per_match
return total_score
# Fields with differents abilities
fields_keywords = {
"Data_Science_Carrier": { 'supervised machine studying', 'Unsupervised machine studying', 'knowledge','evaluation', 'statistics','Python'},
}
# Rating primarily based on particular phrases for that area
def process_image_for_field(picture, area):
if area not in fields_keywords:
print(f"Area '{area}' just isn't outlined.")
return
# Extract textual content from the picture
textual content = text_from_image(picture)
# Tokenize the extracted textual content
tokens = tokenize_text(textual content)
# Evaluate tokens with particular phrases for the chosen area
specific_words = fields_keywords[field]
total_score = compare_tokens_and_score(tokens, specific_words)
print(f"Area: {area}")
print("Whole Rating:", total_score)
picture="CV1.png"
area = 'Data_Science_Carrier' To deal with case sensitivity e.g., “Knowledge Science” vs. “knowledge science”, we will convert all tokens and key phrases to lowercase.
tokens = word_tokenize(extracted_text.decrease())With the usage of lemmatization with NLP libraries like NLTK or stemming with spaCy to cut back phrases (e.g., “operating” to “run”)
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def normalize_tokens(tokens):
return [lemmatizer.lemmatize(token.lower()) for token in tokens]
Getting Textual content from PDF Recordsdata
Allow us to now discover the actions required to get textual content from pdf information.
Set up Required Libraries
You will want the next libraries:
- PyPDF2
- pdfplumber
- spacy
- nltk
Utilizing pip
pip set up PyPDF2 pdfplumber nltk spacy
python -m spacy obtain en_core_web_smimport PyPDF2
def text_from_pdf(pdf_file):
with open(pdf_file, 'rb') as file:
reader = PyPDF2.PdfReader(file)
textual content = ""
for page_num in vary(len(reader.pages)):
web page = reader.pages[page_num]
textual content += web page.extract_text() + "n"
return textual contentimport pdfplumber
def text_from_pdf(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
textual content = ""
for web page in pdf.pages:
textual content += web page.extract_text() + "n"
return textual content
pdf_file="SoniaSingla-DataScience-Bio.pdf"
# Extract textual content from the PDF
textual content = text_from_pdf(pdf_file)
# Tokenize the extracted textual content
tokens = word_tokenize(textual content)
print(tokens) Normalizing Tokens for Consistency
To deal with the PDF file as a substitute of a picture and be certain that repeated phrases don’t obtain a number of scores, modify the earlier code. We are going to extract textual content from the PDF file, tokenize it, and evaluate the tokens towards particular phrases from completely different fields. The code will calculate the rating primarily based on distinctive matched phrases.
import pdfplumber
import nltk
from nltk.tokenize import word_tokenize
nltk.obtain('punkt')
def extract_text_from_pdf(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
textual content = ""
for web page in pdf.pages:
textual content += web page.extract_text() + "n"
return textual content
def tokenize_text(textual content):
tokens = word_tokenize(textual content)
return tokens
def compare_tokens_and_score(tokens, specific_words, score_per_match=10):
# Use a set to retailer distinctive matched phrases to forestall duplicates
unique_matched_words = set(phrase.decrease() for phrase in tokens if phrase.decrease() in specific_words)
# Calculate complete rating primarily based on distinctive matches
total_score = len(unique_matched_words) * score_per_match
return unique_matched_words, total_score
# Outline units of particular phrases for various fields
fields_keywords = {
"Data_Science_Carrier": { 'supervised machine studying', 'Unsupervised machine studying', 'knowledge','evaluation', 'statistics','Python'},
# Add extra fields and key phrases right here
}
# Step 4: Choose the sector and calculate the rating primarily based on particular phrases for that area
def process_pdf_for_field(pdf_file, area):
if area not in fields_keywords:
print(f"Area '{area}' just isn't outlined.")
return
textual content = extract_text_from_pdf(pdf_file)
tokens = tokenize_text(textual content)
specific_words = fields_keywords[field]
unique_matched_words, total_score = compare_tokens_and_score(tokens, specific_words)
print(f"Area: {area}")
print("Distinctive matched phrases:", unique_matched_words)
print("Whole Rating:", total_score)
pdf_file="SoniaSingla-DataScience-Bio.pdf"
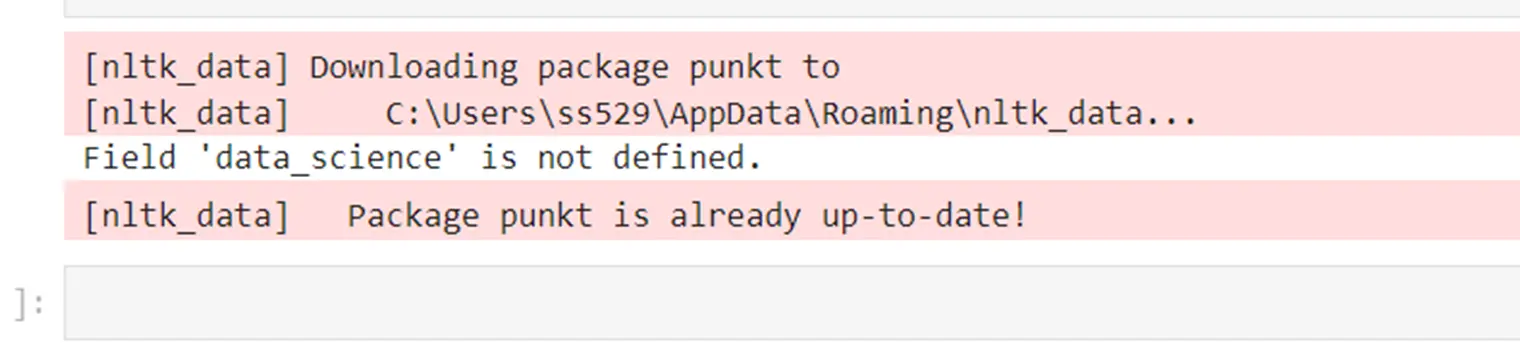
area = 'data_science'
process_pdf_for_field(pdf_file, fieIt’s going to produce an error message as data_science area just isn’t outlined.
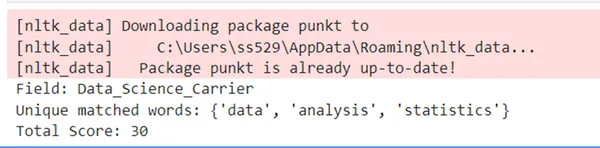
When the error is eliminated, it really works superb.
To deal with case sensitivity correctly and be certain that phrases like “knowledge” and “Knowledge” are thought of the identical phrase whereas nonetheless scoring it solely as soon as (even when it seems a number of occasions with completely different circumstances), you possibly can normalize the case of each the tokens and the particular phrases. We are able to do that by changing each the tokens and the particular phrases to lowercase in the course of the comparability however nonetheless protect the unique casing for the ultimate output of matched phrases.
- Utilizing pdfplumber to extract the textual content from the pdf file.
- Utilizing OCR to transform picture into machine code.
- Utilizing pytesseract for changing python wrap codes into textual content.
Conclusion
We explored the essential technique of extracting and analyzing knowledge from CVs, specializing in automation strategies utilizing Python. We realized methods to make the most of important libraries like NLTK, SpaCy, Pytesseract, and Pillow for efficient textual content extraction from numerous file codecs, together with PDFs and pictures. By making use of strategies for tokenization, textual content normalization, and scoring, we gained insights into methods to align candidates’ {qualifications} with job necessities effectively. This systematic method not solely streamlines the hiring course of for employers but additionally enhances candidates’ possibilities of securing positions that match their abilities.
Key Takeaways
- Environment friendly knowledge extraction from CVs is important for automating the hiring course of.
- Instruments like NLTK, SpaCy, Pytesseract, and Pillow are important for textual content extraction and processing.
- Correct tokenization strategies assist in precisely analyzing the content material of CVs.
- Implementing a scoring mechanism primarily based on key phrases enhances the matching course of between candidates and job necessities.
- Normalizing tokens by way of strategies like lemmatization improves textual content evaluation accuracy.
Incessantly Requested Questions
A. PyPDF2 or pdfplumber libraries to extract textual content from pdf.
A. If the CV is in picture format (scanned doc or picture), you need to use OCR (Optical Character Recognition) to extract textual content from the picture. Probably the most generally used device for this in Python is pytesseract, which is a wrapper for Tesseract OCR.
A. Enhancing the standard of pictures earlier than feeding them into OCR can considerably improve textual content extraction accuracy. Methods like grayscale conversion, thresholding, and noise discount utilizing instruments like OpenCV can assist.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.
I’ve finished my Grasp Of Science in Biotechnology and Grasp of Science in Bioinformatics from reputed Universities. I’ve written just a few analysis papers, reviewed them, and am presently an Advisory Editorial Board Member at IJPBS.
I Stay up for the alternatives in IT to make the most of my abilities gained throughout work and Internship.
https://aster28.github.io/SoniaSinglaBio/website/