
{kind=link}
Introduction
Managing a knowledge pipeline, corresponding to transferring knowledge from CSV to PostgreSQL, is like orchestrating a well-timed course of the place every step depends on the earlier one. Apache Airflow streamlines this course of by automating the workflow, making it straightforward to handle complicated knowledge duties.
On this article, we’ll construct a sturdy knowledge pipeline utilizing Apache Airflow, Docker, and PostgreSQL PostgreSQL to automate studying knowledge from CSV recordsdata and inserting it right into a database. We’ll cowl key Airflow ideas corresponding to Directed Acyclic Graphs (DAGs), duties, and operators, which is able to allow you to effectively handle workflows.
The purpose of this mission is to show create a dependable knowledge pipeline with Apache Airflow that reads knowledge from CSV recordsdata and writes it right into a PostgreSQL database. We’ll discover the mixing of varied Airflow elements to make sure efficient knowledge dealing with and preserve knowledge integrity.
Studying Outcomes
- Perceive the core ideas of Apache Airflow, together with DAGs, duties, and operators.
- Learn to arrange and configure Apache Airflow with Docker for workflow automation.
- Achieve sensible information on integrating PostgreSQL for knowledge administration inside Airflow pipelines.
- Grasp the method of studying CSV recordsdata and automating knowledge insertion right into a PostgreSQL database.
- Construct and deploy scalable, environment friendly knowledge pipelines utilizing Airflow and Docker.
Stipulations
- Docker Desktop, VS Code, Docker compose
- Primary understanding of Docker containers
- Primary Docker instructions
- Primary Linux Instructions
- Primary Python Data
- Constructing Picture from Dockerfile, Docker-compose
This text was printed as part of the Knowledge Science Blogathon.
What’s Apache Airflow?
Apache Airflow (or just Airflow) is a platform to programmatically writer, schedule, and monitor workflows. When workflows are outlined as code, they grow to be extra maintainable, versionable, testable, and collaborative. The wealthy consumer interface makes it straightforward to visualise pipelines operating in manufacturing, monitor progress, and troubleshoot points when wanted.

Understanding Airflow Terminologies
Allow us to perceive the airflow terminologies beneath:
Workflow
- Consider a workflow as a step-by-step course of to attain a objective. It may be a sequence of actions that must be carried out in a particular order to perform one thing.
- Instance: If you wish to bake a cake, the workflow might embody steps like: collect components → combine components → bake cake → beautify cake.
DAG (Directed Acyclic Graph)
- A DAG is a blueprint or map of your workflow. It defines what must be carried out and in what order, however it doesn’t truly carry out the duties. It reveals the dependencies between totally different steps.
- “Directed” signifies that the steps observe a particular order, whereas “Acyclic” signifies that the method can not loop again to a earlier step.
- Instance: Within the cake instance, the DAG can be a chart that claims it is advisable collect components earlier than mixing them and blend the components earlier than baking the cake.
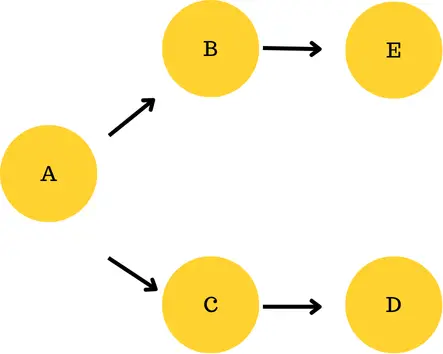
On this DAG, A will run first, then break up into two branches: one goes to B after which to D, and the opposite goes to C after which to E. Each branches can run independently after A finishes.
Job
- A job is a single motion or step inside the workflow. Every job represents a particular job that must be carried out.
- Instance: Within the cake workflow, duties can be: collect components (one job), combine components (one other job), bake cake (one more job), and so forth.
Operators in Airflow
- Operators are the constructing blocks of duties in Airflow. They inform Airflow what motion to carry out for a job.
- Every operator defines a particular motion, like operating a Python script, transferring knowledge, or triggering one other course of.
Distinguished Operators
- PythonOperator: Runs a Python perform.
- Instance: Executes a Python perform to scrub knowledge.
- DummyOperator: Does nothing, used for testing or as a placeholder.
- Instance: Marks the completion of part of a DAG with out doing something.
- PostgresOperator : The PostgresOperator is an Airflow operator designed to run SQL instructions in a PostgreSQL database.
XComs (Cross-Communications)
- XComs are a manner for duties to speak with one another in Airflow.
- They permit one job to ship knowledge to a different job.
- Instance: Job A processes some knowledge, shops the end result utilizing XCom, and Job B can retrieve that end result and proceed processing.
In easy phrases: Operators outline what your job will do, and XComs let duties cross info to one another.
Connections
In Airflow, you utilize connections to handle and retailer the credentials and particulars required for connecting to exterior techniques and companies. They permit Airflow to work together with numerous knowledge sources, APIs, and companies securely and persistently. For instance, while you create a Spark or AWS S3 connection in Airflow, you allow Airflow to work together with Spark clusters or AWS S3 buckets, respectively, by duties outlined in your DAGs.
Now that we’re clear with the fundamental terminologies of airflow, lets begin constructing our mission !!
Putting in Apache Airflow on Docker Utilizing Dockerfile
Utilizing Docker with Apache Airflow ensures a straightforward and reproducible surroundings setup.
Writing a Dockerfile
A Dockerfile is a script that incorporates a collection of directions to construct a Docker picture.Kindly copy these directions right into a file with the title Dockerfile.
Essential : Don’t save the file as Dockerfile.txt or every other extension. Merely save as Dockerfile.
FROM apache/airflow:2.9.1-python3.9
USER root
# Set up Python dependencies
COPY necessities.txt /necessities.txt
RUN pip3 set up --upgrade pip
RUN pip3 set up --no-cache-dir -r /necessities.txt
# Set up Airflow suppliers
RUN pip3 set up apache-airflow-providers-apache-spark apache-airflow-providers-amazon n
# Set up system dependencies
RUN apt-get replace &&
apt-get set up -y gcc python3-dev openjdk-17-jdk &&
apt-get clearWe begin with a base picture from the official Apache Airflow repository. This ensures that now we have a secure and dependable basis for our software:
- FROM apache/airflow:2.9.1-python3.9
- The picture apache/airflow:2.9.1-python3.9 consists of Airflow model 2.9.1 and Python 3.9, which offers the important instruments and libraries to run Apache Airflow.
- USER root
- By switching to the foundation consumer, we achieve the required permissions to put in packages and modify the file system inside the container.
- Putting in Python Dependencies
- We’ll copy a necessities file containing the required Python packages into the picture and set up them.
- Putting in Airflow Suppliers
- We set up particular Airflow suppliers required for our workflows.Right here for tutorial functions, now we have put in Supplier for Apache Spark and Supplier for AWS companies.You’ll be able to set up numerous different suppliers. Distinguished suppliers embody Spark, AWS, Google, Postgres.
- Putting in System Dependencies
- Lastly, we set up system-level dependencies which may be required by sure libraries or functionalities.
RUN apt-get replace &&
apt-get set up -y gcc python3-dev openjdk-17-jdk &&
apt-get clear
- apt-get replace: Updates the package deal lists for the most recent model of packages.
- apt-get set up -y gcc python3-dev openjdk-17-jdk: Installs the GCC compiler, Python growth headers, and OpenJDK 17, which can be required for constructing sure packages.
- apt-get clear: Cleans up the package deal cache to scale back the picture dimension.
Now that we’re carried out with establishing the Dockerfile, let’s transfer forward!!
Configuring Docker Compose for Apache Airflow
Along with making a customized Docker picture with a Dockerfile, you possibly can simply handle and orchestrate your Docker containers utilizing Docker Compose. The docker-compose.yml file defines the companies, networks, and volumes that make up your software. We join the Dockerfile to the Compose file in order that we will construct a customized picture for our software and simply handle all of the companies it must run collectively. Let’s see specify our customized Dockerfile within the Docker Compose setup :
x-airflow-common
This part defines widespread settings for all Airflow companies.
- Units up the surroundings variables wanted for the Airflow software to run.
- Specifies connections to a PostgreSQL database to retailer Airflow knowledge.
- Defines paths for storing DAGs (Directed Acyclic Graphs), logs, and configurations.
model: '1.0'
x-airflow-common: &airflow-common
construct:
context: .
dockerfile: Dockerfile
surroundings:
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__CORE__FERNET_KEY: ""
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: "true"
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CORE__LOAD_EXAMPLES: "false"
AIRFLOW__API__AUTH_BACKENDS: airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: "true"
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/choose/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/choose/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/choose/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/choose/airflow/plugins
- ${AIRFLOW_PROJ_DIR:-.}/necessities.txt:/choose/airflow/necessities.txt
- ${AIRFLOW_PROJ_DIR:-.}/sample_files:/choose/airflow/sample_files
- ./spark_jobs:/choose/bitnami/spark_jobs
consumer: ${AIRFLOW_UID:-50000}:0
depends_on:
postgres:
situation: service_healthy
networks:
- confluentAfter establishing the x-airflow-common, we have to outline the companies which will probably be required.
airflow-webserver
This service runs the net interface for Airflow, the place customers can handle and monitor workflows.
- Exposes port 8080 to entry the net UI.
- Makes use of well being checks to make sure that the net server is operating correctly.
- Relies on the database service to be wholesome earlier than beginning.
companies:
airflow-webserver:
<<: *airflow-common
ports:
- "8080:8080"
depends_on:
postgres:
situation: service_healthy
healthcheck:
take a look at: ["CMD-SHELL", "curl -f http://localhost:8080/health || exit 1"]
interval: 30s
timeout: 10s
retries: 3airflow-scheduler
The scheduler is chargeable for triggering duties primarily based on the outlined workflows.
airflow-scheduler:
<<: *airflow-common
networks :
- confluent
depends_on:
postgres:
situation: service_healthy
airflow-webserver:
situation: service_healthy
healthcheck:
take a look at: ["CMD-SHELL", "curl -f http://localhost:8080/health || exit 1"]
interval: 30s
timeout: 10s
retries: 3airflow-triggerer
This service triggers duties that require exterior occasions or circumstances to start out. It runs in the same method to the scheduler and connects to the identical PostgreSQL database.
airflow-triggerer:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
airflow-init:
situation: service_completed_successfully
networks:
- confluent
command: bash -c "airflow triggerer"
healthcheck:
take a look at:
- CMD-SHELL
- airflow jobs test --job-type TriggererJob --hostname "${HOSTNAME}"
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: all the timeairflow-cli
This service permits command-line interface (CLI) operations on the Airflow surroundings. It could possibly run numerous Airflow instructions for debugging or administration.
airflow-cli:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
networks:
- confluent
profiles:
- debug
command:
- bash
- -c
- airflowairflow-init
This service initializes the database and creates the default admin consumer.
airflow-init:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
command: >
bash -c "
airflow db init &&
airflow customers create
--username admin
--firstname admin
--lastname admin
--role Admin
--email [email protected]
--password admin
"
networks:
- confluentpostgres
This service hosts the PostgreSQL database utilized by Airflow to retailer its metadata. We’ve set the username and password to hook up with postgres as airflow.
postgres:
picture: postgres:16.0
surroundings:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
logging:
choices:
max-size: 10m
max-file: "3"
healthcheck:
take a look at:
- CMD
- pg_isready
- -U
- airflow
interval: 10s
retries: 5
start_period: 5s
restart: all the time
networks:
- confluentnetworks
Defines a community for all companies to speak with one another.
All companies are linked to the identical confluent community, permitting them to work together seamlessly.
networks:
confluent:Full docker-compose.yml
x-airflow-common: &airflow-common
construct:
context: .
dockerfile: Dockerfile
surroundings:
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__CORE__FERNET_KEY: ""
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: "true"
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CORE__LOAD_EXAMPLES: "false"
AIRFLOW__API__AUTH_BACKENDS: airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: "true"
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/choose/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/dags/sql:/choose/airflow/dags/sql
- ${AIRFLOW_PROJ_DIR:-.}/logs:/choose/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/choose/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/choose/airflow/plugins
- ${AIRFLOW_PROJ_DIR:-.}/necessities.txt:/choose/airflow/necessities.txt
- ${AIRFLOW_PROJ_DIR:-.}/sample_files:/choose/airflow/sample_files
- ./spark_jobs:/choose/bitnami/spark_jobs
consumer: ${AIRFLOW_UID:-50000}:0
depends_on:
postgres:
situation: service_healthy
networks:
- confluent
companies:
airflow-webserver:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
airflow-init:
situation: service_completed_successfully
networks:
- confluent
command: bash -c "airflow webserver"
ports:
- 8080:8080
healthcheck:
take a look at:
- CMD
- curl
- --fail
- http://localhost:8080/well being
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: all the time
airflow-scheduler:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
airflow-init:
situation: service_completed_successfully
networks:
- confluent
command: bash -c "airflow scheduler"
healthcheck:
take a look at:
- CMD
- curl
- --fail
- http://localhost:8974/well being
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: all the time
airflow-triggerer:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
airflow-init:
situation: service_completed_successfully
networks:
- confluent
command: bash -c "airflow triggerer"
healthcheck:
take a look at:
- CMD-SHELL
- airflow jobs test --job-type TriggererJob --hostname "${HOSTNAME}"
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: all the time
airflow-init:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
command: >
bash -c "
airflow db init &&
airflow customers create
--username admin
--firstname admin
--lastname admin
--role Admin
--email [email protected]
--password admin
"
networks:
- confluent
airflow-cli:
<<: *airflow-common
depends_on:
postgres:
situation: service_healthy
networks:
- confluent
profiles:
- debug
command:
- bash
- -c
- airflow
postgres:
picture: postgres:1.0
surroundings:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
logging:
choices:
max-size: 10m
max-file: "3"
healthcheck:
take a look at:
- CMD
- pg_isready
- -U
- airflow
interval: 10s
retries: 5
start_period: 5s
restart: all the time
networks:
- confluent
networks:
confluent:Information to Undertaking Setup and Execution
We’ll now look into the steps for establishing our mission and execution.
Step 1: Making a Folder
First step is to create a folder after which paste the above Dockerfile and docker-compose.yml recordsdata inside this folder.
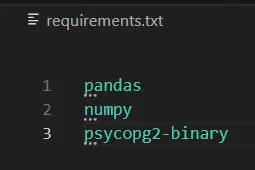
Step 2: Creating Requirement
Create a necessities.txt file and write obligatory python libraries. It could possibly embody pandas, numpy and so forth.
Step 3: Docker Desktop
Begin your Docker desktop. Then, open your terminal and write ” docker-compose up -d “.
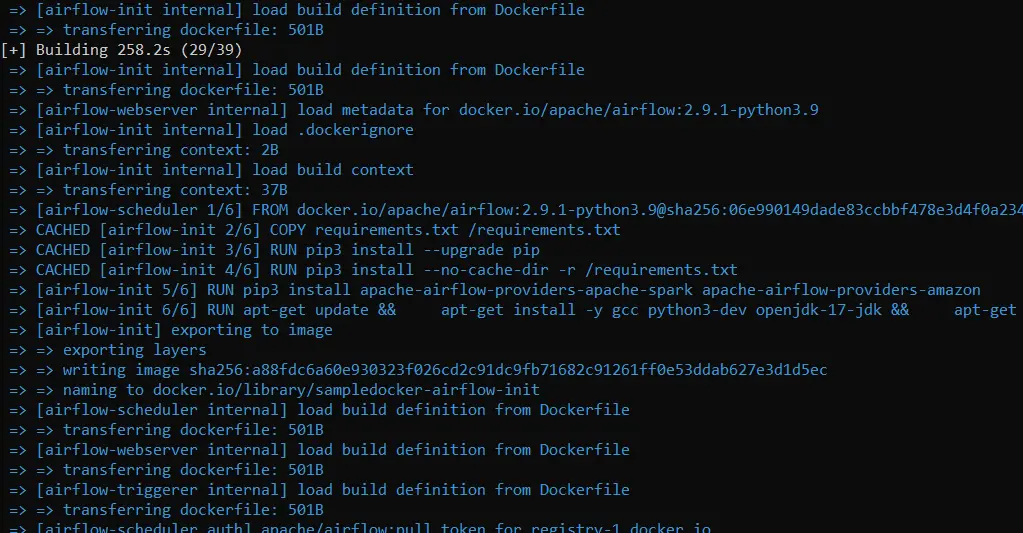
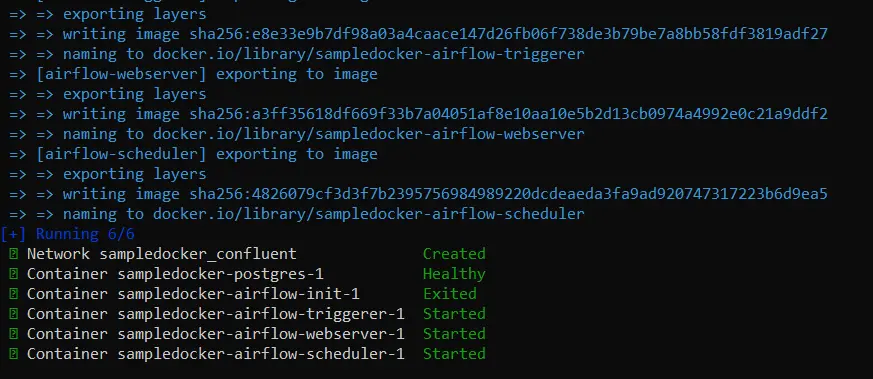
You must see one thing just like the above photographs. After the command is executed efficiently, you must be capable of see these recordsdata :
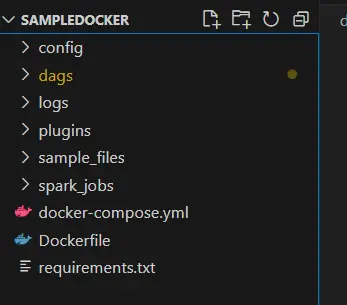
Step 4: Confirm Airflow Set up
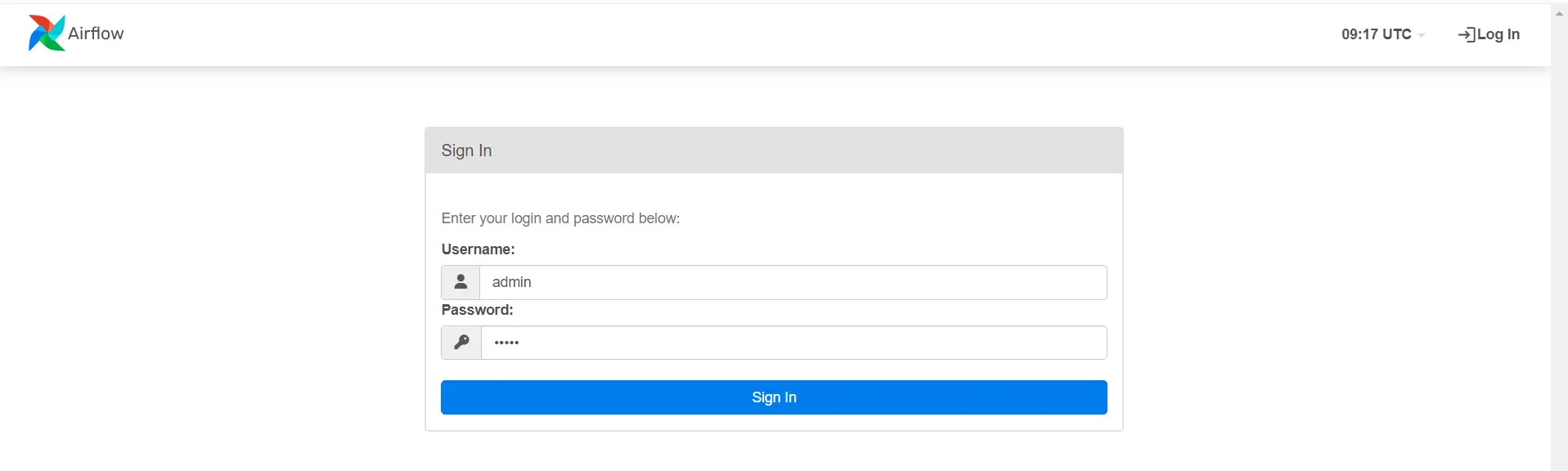
In your browser, enter this URL : http://localhost:8080. In case your set up was profitable, you must see:
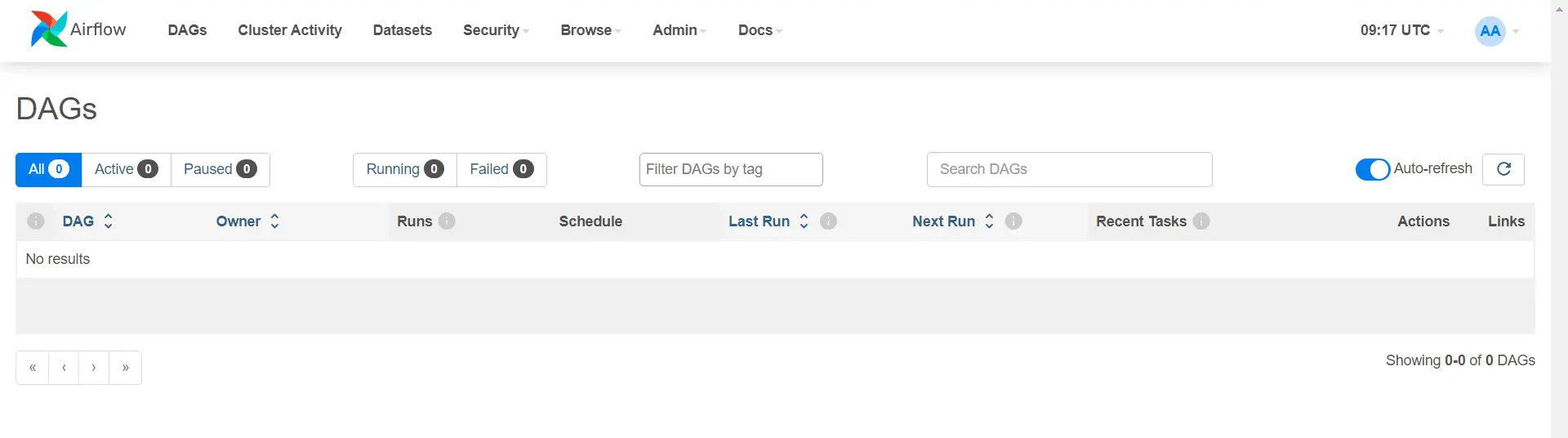
Enter your username and password as admin. After logging in, you must see :
Step 5: Connecting Postgres to Airflow
We use postgres_conn_id to specify the connection to the PostgreSQL database inside Airflow. You outline this connection ID within the Airflow UI, the place you configure database credentials such because the host, port, username, and password.
By utilizing postgres_conn_id, Airflow is aware of which database to hook up with when executing SQL instructions. It abstracts away the necessity to hard-code connection particulars instantly within the DAG code, enhancing safety and adaptability.
Step 5.1: On the Airflow UI, navigate to Admin>Connections

Step 5.2: Click on on ‘Add a brand new document’
Step 5.3: Add the next parameters fastidiously.
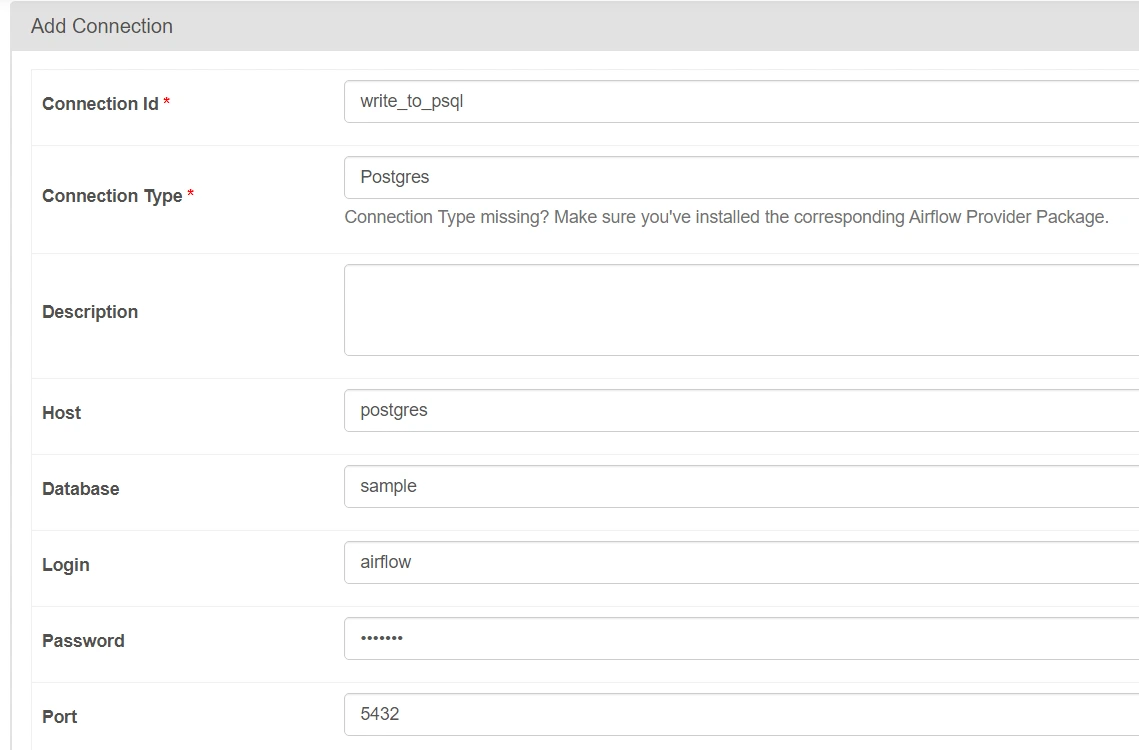
Right here, now we have given the fundamental connection parameters which is able to permit Airflow to hook up with our postgres server configured on Docker.
NOTE : Write connection_id as ‘write_to_psql‘ correctly as it is going to be used later. The login and password to hook up with PostgreSQL are each set to airflow
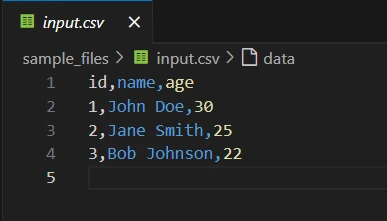
Step 5.4: Getting ready dummy enter.csv file
Put together a dummy enter.csv file for the mission. Retailer the file inside sample_files folder which was created.
Understanding the DAG Setup in Airflow
First, we import the required elements: DAG (to create the workflow), PythonOperator (to run Python capabilities), and PostgresOperator (to work together with a PostgreSQL database). We additionally outline default arguments just like the proprietor of the workflow (airflow) and the beginning date of the duties, guaranteeing the workflow begins on January 1, 2024. Lastly, we import Pandas to deal with knowledge, enabling us to learn CSV recordsdata effectively.
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.suppliers.postgres.operators.postgres import PostgresOperator
from datetime import datetime
import pandas as pd
# Outline default arguments
default_args = {
'proprietor': 'airflow',
'start_date': datetime(2024, 1, 1),
}Understanding generate_insert_queries() Perform
This perform is chargeable for studying a CSV file utilizing Pandas, then creating SQL insert queries to insert knowledge right into a PostgreSQL desk. It loops by every row of the CSV, producing an SQL assertion that inserts the id, title, and age values right into a desk. Lastly, you save these queries to a file named insert_queries.sql contained in the dags/sql folder, permitting Airflow to execute them later utilizing a PostgresOperator.
# Perform to learn the CSV and generate insert queries
def generate_insert_queries():
# Learn the CSV file
df = pd.read_csv(CSV_FILE_PATH)
CSV_FILE_PATH = 'sample_files/enter.csv'
# Create a listing of SQL insert queries
insert_queries = []
for index, row in df.iterrows():
insert_query = f"INSERT INTO sample_table (id, title, age) VALUES ({row['id']}, '{row['name']}', {row['age']});"
insert_queries.append(insert_query)
# Save queries to a file for the PostgresOperator to execute
with open('./dags/sql/insert_queries.sql', 'w') as f:
for question in insert_queries:
f.write(f"{question}n")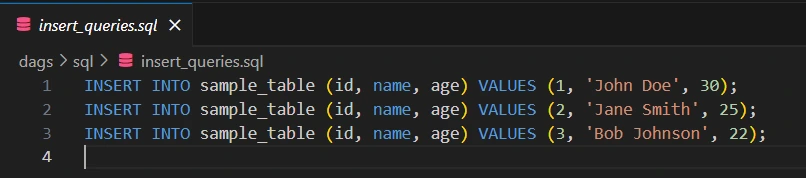
DAG Definition
This block defines the DAG (Directed Acyclic Graph), which represents your complete workflow. The parameters embody:
- schedule_interval=’@as soon as’: This specifies that the DAG ought to run solely as soon as.
- catchup=False: Prevents backfilling of DAG runs for missed schedules.
- default_args=default_args: Reuses default arguments like the beginning date for the DAG.
with DAG('csv_to_postgres_dag',
default_args=default_args,
schedule_interval="@as soon as",
catchup=False) as dag:
Job ID
Every Airflow job receives a singular task_id, which serves as its figuring out title inside the DAG.
For instance:
task_id='create_table'PostgresOperator
The PostgresOperator permits you to run SQL instructions in a PostgreSQL database utilizing Airflow.
- task_id=’create_table’: This units the distinctive identifier for the duty inside the DAG.
- postgres_conn_id=’write_to_psql’: Refers back to the Airflow connection ID used to hook up with the PostgreSQL database
- sql: Accommodates the SQL question that drops the desk if it exists after which creates a brand new sample_table with id, title, and age columns.
create_table = PostgresOperator(
task_id='create_table',
postgres_conn_id='write_to_psql', # Change together with your connection ID
sql="""
DROP TABLE IF EXISTS sample_table;
CREATE TABLE sample_table (
id SERIAL PRIMARY KEY,
title VARCHAR(50),
age INT
);
"""
)PythonOperator
The PythonOperator permits you to run Python capabilities as duties. Right here, it calls the generate_insert_queries perform, which generates SQL queries from a CSV file.
generate_queries = PythonOperator(
task_id='generate_insert_queries',
python_callable=generate_insert_queries
)PostgresOperator
- task_id=’run_insert_queries’ : A novel identifier for the duty that runs the SQL insert queries.
- postgres_conn_id=’write_to_psql’: Connection ID utilized by Airflow to hook up with the PostgreSQL database, which is pre-configured within the Airflow UI.
- sql=’sql/insert_queries.sql’: The trail to the file containing SQL queries that will probably be executed in PostgreSQL.
run_insert_queries = PostgresOperator(
task_id='run_insert_queries',
postgres_conn_id='write_to_psql', # Outline this connection in Airflow UI
sql="sql/insert_queries.sql"
)create_table>>generate_queries>>run_insert_queriesThe road create_table >> generate_queries >> run_insert_queries establishes a sequence of job execution in Apache Airflow. It signifies that:
- create_table job should be accomplished efficiently earlier than the following job can start.
- As soon as create_table is completed, the generate_queries job will run.
- After generate_queries has completed executing, the run_insert_queries job will then execute.
Briefly, it defines a linear workflow the place every job is dependent upon the profitable completion of the earlier one.
Creating Python File
In your VS Code, create a Python file named pattern.py contained in the routinely created dags folder.
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.suppliers.postgres.operators.postgres import PostgresOperator
from datetime import datetime
import pandas as pd
# Outline default arguments
default_args = {
'proprietor': 'airflow',
'start_date': datetime(2024, 1, 1),
}
# Perform to learn the CSV and generate insert queries
def generate_insert_queries():
CSV_FILE_PATH = 'sample_files/enter.csv'
# Learn the CSV file
df = pd.read_csv(CSV_FILE_PATH)
# Create a listing of SQL insert queries
insert_queries = []
for index, row in df.iterrows():
insert_query = f"INSERT INTO sample_table (id, title, age) VALUES ({row['id']}, '{row['name']}', {row['age']});"
insert_queries.append(insert_query)
# Save queries to a file for the PostgresOperator to execute
with open('./dags/sql/insert_queries.sql', 'w') as f:
for question in insert_queries:
f.write(f"{question}n")
# Outline the DAG
with DAG('csv_to_postgres_dag',
default_args=default_args,
schedule_interval="@as soon as",
catchup=False) as dag:
# Job to create a PostgreSQL desk
create_table = PostgresOperator(
task_id='create_table',
postgres_conn_id='write_to_psql', # Change together with your connection ID
sql="""
DROP TABLE IF EXISTS sample_table;
CREATE TABLE sample_table (
id SERIAL PRIMARY KEY,
title VARCHAR(50),
age INT
);
"""
)
generate_queries = PythonOperator(
task_id='generate_insert_queries',
python_callable=generate_insert_queries
)
# Job to run the generated SQL queries utilizing PostgresOperator
run_insert_queries = PostgresOperator(
task_id='run_insert_queries',
postgres_conn_id='write_to_psql', # Outline this connection in Airflow UI
sql="sql/insert_queries.sql"
)
create_table>>generate_queries>>run_insert_queries
# Different duties can observe right hereNOTE: Please put the pattern.py contained in the dags folder solely. It is because by default, airflow seems to be for the recordsdata contained in the dags folder.
Configuring Postgres
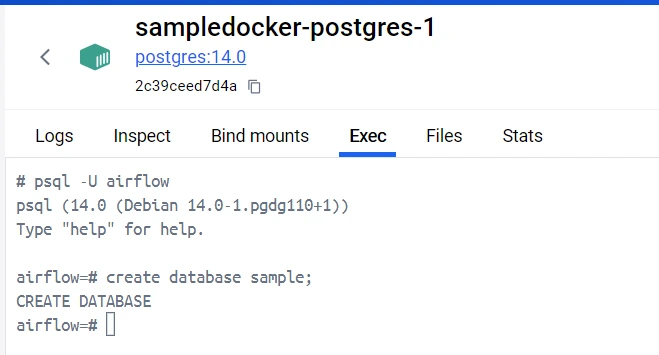
Earlier than operating our code, we have to create a pattern database inside our PostgreSQL container to put in writing our CSV knowledge.
In your Docker Desktop, navigate to the postgres container and go to the EXEC part. Write the next instructions which is able to create a database referred to as pattern inside our Postgres database.
Run Your Code
Now that you just’ve constructed the muse of your Airflow mission, it’s time to see your laborious work come to fruition! Operating your code is the place the magic occurs; you’ll witness your CSV knowledge being reworked and seamlessly inserted into your PostgreSQL database.
- In your terminal, once more write docker compose up -d. It will load up our pattern.py code inside airflow.
- Go to the Airflow Dwelling Web page and click on on the dag.
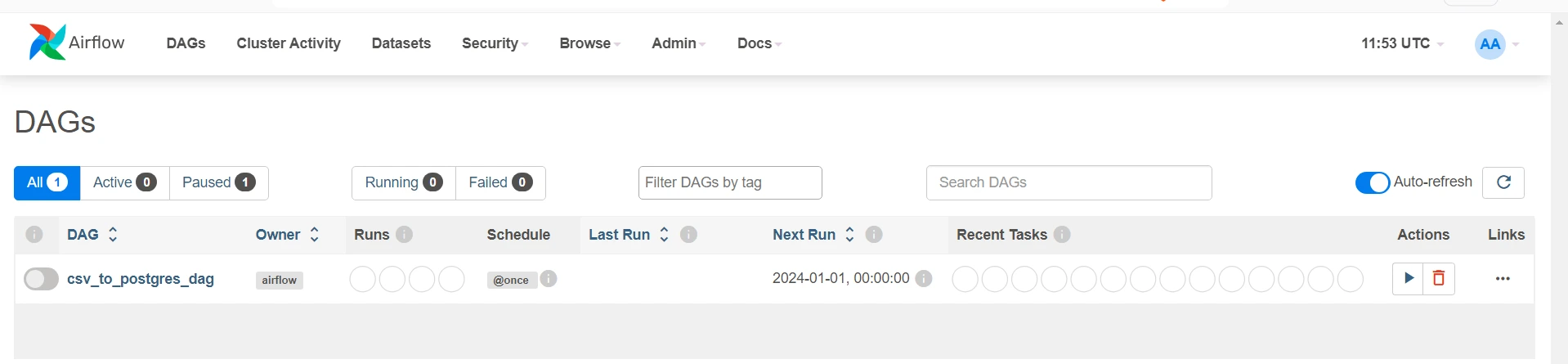
Upon clicking Graph, you possibly can visualize your pipeline. The code part will present your newest code written within the file.
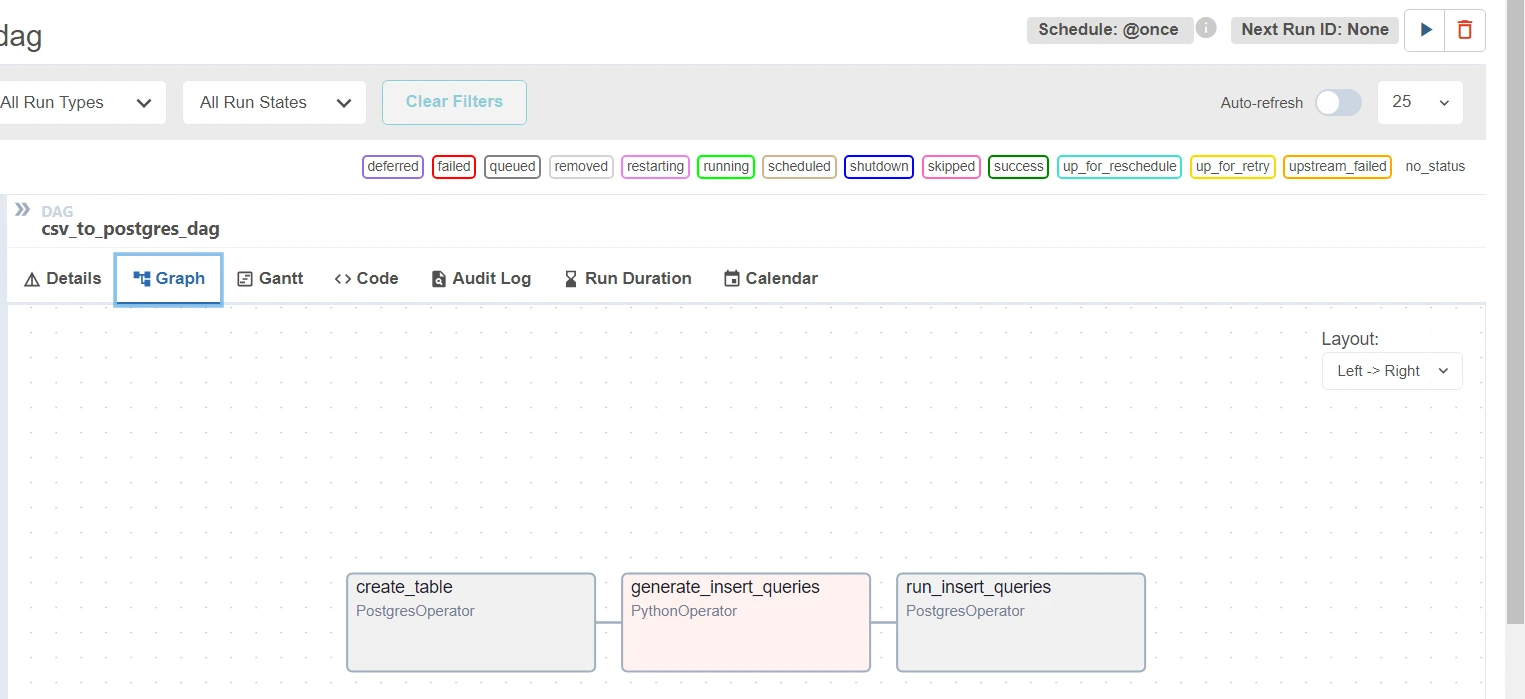
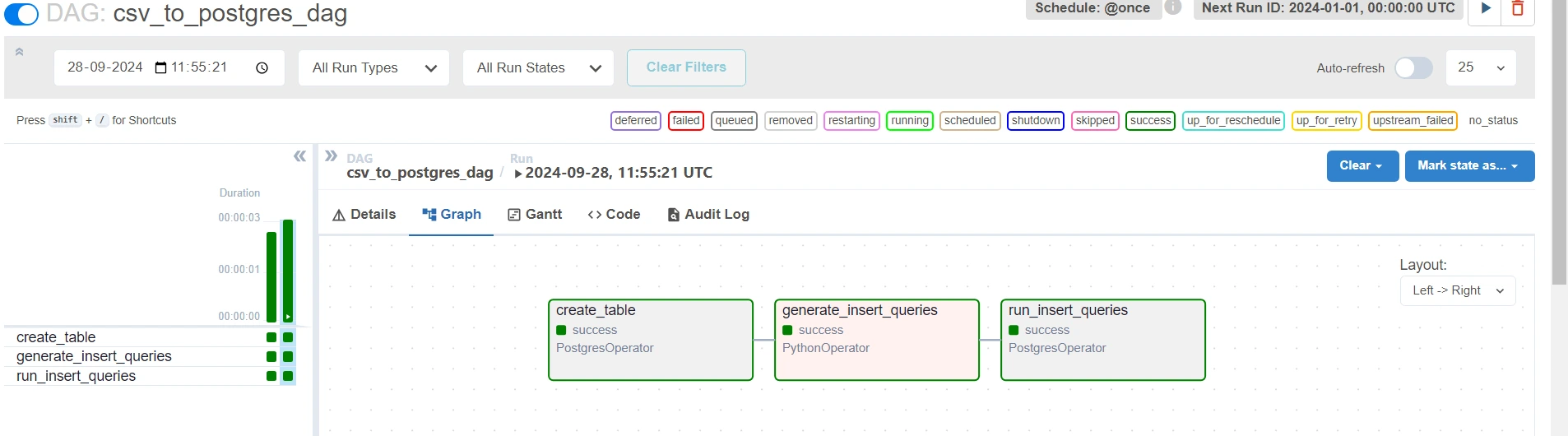
Upon clicking the play button on the upper-right nook (subsequent to “Subsequent Run ID: None” marker), you possibly can run the dag. After operating the dag, click on on any job within the graph part to see its particulars. Discover to seek out out extra.
If there have been no errors, then you must see a Inexperienced coloration bar on the left aspect.
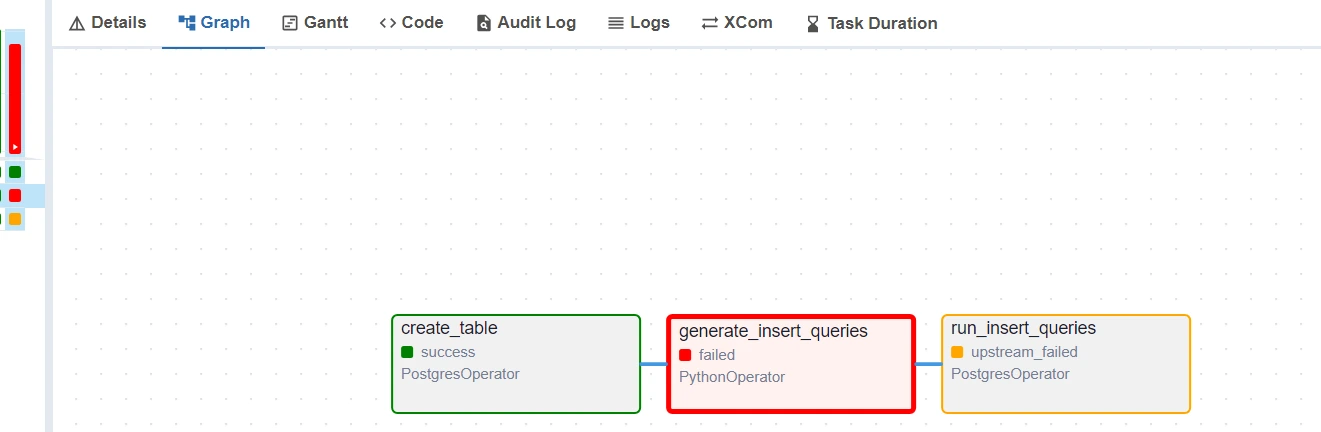
Nonetheless if there are any errors, click on on the duty which failed after which click on on the Logs to grasp the error :
Conclusion
This mission efficiently demonstrated the mixing of Airflow with PostgreSQL to automate the method of studying knowledge from a CSV file and inserting it right into a database. All through the mission, numerous operators have been explored and applied for environment friendly knowledge dealing with strategies. This mission showcases the ability of Airflow in automating knowledge workflows and lays the groundwork for additional exploration in knowledge engineering.
Github Repo : Undertaking File
Key Takeaways
- Using Airflow to automate knowledge workflows considerably enhances effectivity and reduces handbook intervention in knowledge processing duties
- The PostgresOperator simplifies executing SQL instructions, making database operations seamless inside Airflow DAGs.
- Docker helps package deal the Airflow setup right into a container, making it straightforward to run the identical software wherever with out worrying about totally different environments.
Often Requested Questions
A. Apache Airflow permits you to programmatically writer, schedule, and monitor workflows as an open-source platform. It helps automate complicated knowledge pipelines by organizing duties into directed acyclic graphs (DAGs).
A. Docker simplifies the setup and deployment of Apache Airflow by creating remoted, reproducible environments. It ensures seamless configuration and operation of all obligatory dependencies and companies, corresponding to PostgreSQL, inside containers.
A. Airflow can hook up with PostgreSQL utilizing its built-in database operators. You should utilize these operators to execute SQL queries, handle database operations, and automate knowledge pipelines that contain studying from or writing to PostgreSQL databases.
A. You should utilize Python scripts in Airflow duties to learn CSV recordsdata. The duty can extract knowledge from the CSV and, by a database operator, insert the information into PostgreSQL, automating your complete workflow.
A. Sure, Apache Airflow can scale simply. With Docker, you possibly can run a number of employee nodes, and Airflow can distribute duties throughout them. Moreover, integrating a database like PostgreSQL helps environment friendly dealing with of large-scale knowledge.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.