
{kind=link}
Editor’s notice: This put up is a part of the AI Decoded collection, which demystifies AI by making the expertise extra accessible, and showcases new {hardware}, software program, instruments and accelerations for GeForce RTX PC and NVIDIA RTX workstation customers.
From video games and content material creation apps to software program improvement and productiveness instruments, AI is more and more being built-in into functions to boost consumer experiences and increase effectivity.
These effectivity boosts lengthen to on a regular basis duties, like net searching. Courageous, a privacy-focused net browser, lately launched a sensible AI assistant known as Leo AI that, along with offering search outcomes, helps customers summarize articles and movies, floor insights from paperwork, reply questions and extra.
The expertise behind Courageous and different AI-powered instruments is a mix of {hardware}, libraries and ecosystem software program that’s optimized for the distinctive wants of AI.
Why Software program Issues
NVIDIA GPUs energy the world’s AI, whether or not operating within the knowledge heart or on an area PC. They comprise Tensor Cores, that are particularly designed to speed up AI functions like Leo AI by means of massively parallel quantity crunching — quickly processing the large variety of calculations wanted for AI concurrently, relatively than doing them separately.
However nice {hardware} solely issues if functions could make environment friendly use of it. The software program operating on high of GPUs is simply as vital for delivering the quickest, most responsive AI expertise.
The primary layer is the AI inference library, which acts like a translator that takes requests for frequent AI duties and converts them to particular directions for the {hardware} to run. In style inference libraries embody NVIDIA TensorRT, Microsoft’s DirectML and the one utilized by Courageous and Leo AI through Ollama, known as llama.cpp.
Llama.cpp is an open-source library and framework. By CUDA — the NVIDIA software program utility programming interface that allows builders to optimize for GeForce RTX and NVIDIA RTX GPUs — gives Tensor Core acceleration for a whole bunch of fashions, together with widespread giant language fashions (LLMs) like Gemma, Llama 3, Mistral and Phi.
On high of the inference library, functions usually use an area inference server to simplify integration. The inference server handles duties like downloading and configuring particular AI fashions in order that the appliance doesn’t need to.
Ollama is an open-source venture that sits on high of llama.cpp and gives entry to the library’s options. It helps an ecosystem of functions that ship native AI capabilities. Throughout the complete expertise stack, NVIDIA works to optimize instruments like Ollama for NVIDIA {hardware} to ship quicker, extra responsive AI experiences on RTX.
NVIDIA’s give attention to optimization spans the complete expertise stack — from {hardware} to system software program to the inference libraries and instruments that allow functions to ship quicker, extra responsive AI experiences on RTX.
Native vs. Cloud
Courageous’s Leo AI can run within the cloud or domestically on a PC by means of Ollama.
There are various advantages to processing inference utilizing an area mannequin. By not sending prompts to an outdoor server for processing, the expertise is personal and all the time out there. As an illustration, Courageous customers can get assist with their funds or medical questions with out sending something to the cloud. Operating domestically additionally eliminates the necessity to pay for unrestricted cloud entry. With Ollama, customers can make the most of a greater diversity of open-source fashions than most hosted companies, which regularly assist just one or two sorts of the identical AI mannequin.
Customers can even work together with fashions which have completely different specializations, resembling bilingual fashions, compact-sized fashions, code technology fashions and extra.
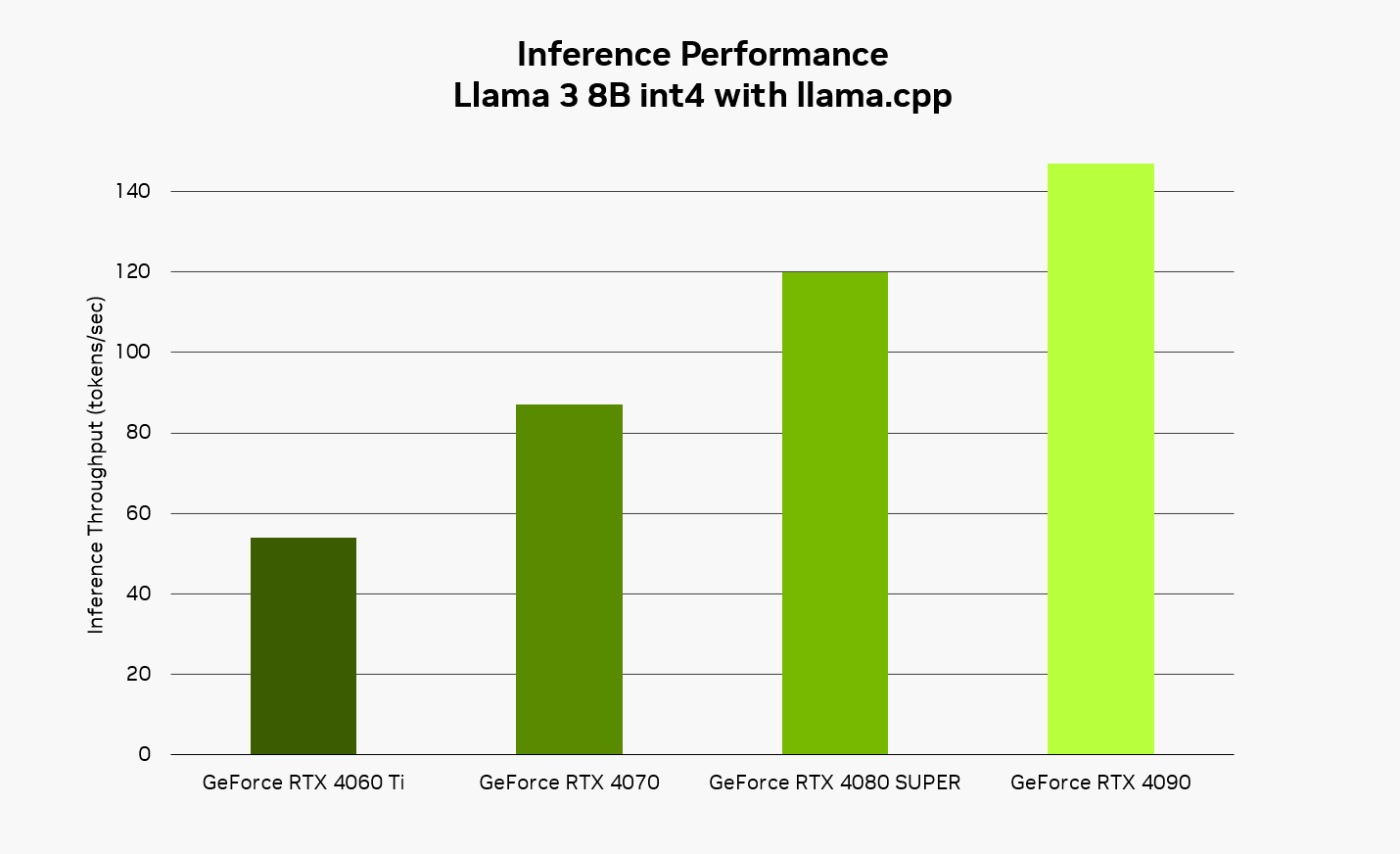
RTX permits a quick, responsive expertise when operating AI domestically. Utilizing the Llama 3 8B mannequin with llama.cpp, customers can anticipate responses as much as 149 tokens per second — or roughly 110 phrases per second. When utilizing Courageous with Leo AI and Ollama, this implies snappier responses to questions, requests for content material summaries and extra.
Get Began With Courageous With Leo AI and Ollama
Putting in Ollama is simple — obtain the installer from the venture’s web site and let it run within the background. From a command immediate, customers can obtain and set up all kinds of supported fashions, then work together with the native mannequin from the command line.
For easy directions on the best way to add native LLM assist through Ollama, learn the firm’s weblog. As soon as configured to level to Ollama, Leo AI will use the domestically hosted LLM for prompts and queries. Customers can even swap between cloud and native fashions at any time.
Builders can study extra about the best way to use Ollama and llama.cpp within the NVIDIA Technical Weblog.
Generative AI is reworking gaming, videoconferencing and interactive experiences of all types. Make sense of what’s new and what’s subsequent by subscribing to the AI Decoded e-newsletter.