
{kind=link}
Introduction
Retrieval Augmented Era (RAG) pipelines are bettering how AI programs work together with customized knowledge, however two crucial elements we are going to concentrate on right here: reminiscence and hybrid search. On this article, we are going to discover how integrating these highly effective options can remodel your RAG system from a easy question-answering device right into a context-aware, clever conversational agent.
Reminiscence in RAG permits your system to take care of and leverage dialog historical past, creating extra coherent and contextually related interactions. In the meantime, hybrid search combines the semantic understanding of vector search with the precision of keyword-based approaches, considerably enhancing the retrieval accuracy of your RAG pipeline.
On this article, we might be utilizing LlamaIndex to implement each reminiscence and hybrid search utilizing Qdrant because the vector retailer and Google’s Gemini as our Massive Language mannequin.
Studying Targets
- Acquire an implementation understanding of the position of reminiscence in RAG programs and its impression on producing contextually correct responses.
- Study to combine Google’s Gemini LLM and Qdrant Quick Embeddings inside the LlamaIndex framework, that is helpful as OpenAI is the default LLM and Embed mannequin utilized in LlamaIndex.
- Develop the implementation of hybrid search strategies utilizing Qdrant Vector retailer, combining vector and key phrase search to reinforce retrieval precision in RAG purposes.
- Discover the capabilities of Qdrant as a vector retailer, specializing in its built-in hybrid search performance and quick embedding options.
This text was printed as part of the Information Science Blogathon.
Hybrid Search in Qdrant
Think about you’re constructing a chatbot for an enormous e-commerce web site. A consumer asks, “Present me the newest iPhone mannequin.” With conventional vector search, you would possibly get semantically related outcomes, however you could possibly miss the precise match. Key phrase search, then again, is perhaps too inflexible. Hybrid search provides you the very best of each worlds:
- Vector search captures semantic that means and context
- Key phrase search ensures precision for particular phrases
Qdrant is our vector retailer of selection for this text, and good cause:
- Qdrant makes implementing hybrid search simple by simply enabling hybrid parameters when outlined.
- It comes with optimized embedding fashions utilizing Fastembed the place the mannequin is loaded in onnx format.
- Qdrant implementation prioritizes defending delicate info, affords versatile deployment choices, minimizes response instances, and reduces operational bills.
Reminiscence and Hybrid Search utilizing LlamaIndex
We’ll dive into the sensible implementation of reminiscence and hybrid search inside the LlamaIndex framework, showcasing how these options improve the capabilities of Retrieval Augmented Era (RAG) programs. By integrating these elements, we are able to create a extra clever and context-aware conversational agent that successfully makes use of each historic knowledge and superior search strategies.
Step 1: Set up Necessities
Alright, let’s break this down step-by-step. We’ll be utilizing LlamaIndex, Qdrant vector retailer, Fastembed from Qdrant, and the Gemini mannequin from Google. Ensure you have these libraries put in:
!pip set up llama-index llama-index-llms-gemini llama-index-vector-stores-qdrant fastembed
!pip set up llama-index-embeddings-fastembedStep 2: Outline LLM and Embedding Mannequin
First, let’s import our dependencies and arrange our API key:
import os
from getpass import getpass
from llama_index.llms.gemini import Gemini
from llama_index.embeddings.fastembed import FastEmbedEmbedding
GOOGLE_API_KEY = getpass("Enter your Gemini API:")
os.environ["GOOGLE_API_KEY"] = GOOGLE_API_KEY
llm = Gemini() # gemini 1.5 flash
embed_model = FastEmbedEmbedding() Now let’s take a look at if the API is presently outlined by operating that LLM on a pattern consumer question.
llm_response = llm.full("when was One Piece began?").textual content
print(llm_response)In LlamaIndex, OpenAI is the default LLM and Embedding mannequin, to override that we have to outline Settings from LlamaIndex Core. Right here we have to override each LLM and Embed mannequin.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model Step 3: Loading Your Information
For this instance, let’s assume we’ve a PDF in a knowledge folder, we are able to load the information folder utilizing SimpleDirectory Reader in LlamaIndex.
from llama_index.core import SimpleDirectoryReader
paperwork = SimpleDirectoryReader("./knowledge/").load_data()Step 4: Setting Up Qdrant with Hybrid Search
We have to outline a QdrantVectorStore occasion and set it up in reminiscence for this instance. We are able to additionally outline the qdrant shopper with its cloud service or localhost, however in our article in reminiscence, a definition with a group title ought to do.
Make certain the enable_hybrid=True as this enables us to make use of Qdrant’s hybrid search capabilities. Our assortment title is `paper`, as the information folder comprises a PDF on a Analysis paper on Brokers.
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
shopper = qdrant_client.QdrantClient(
location=":reminiscence:",
)
vector_store = QdrantVectorStore(
collection_name = "paper",
shopper=shopper,
enable_hybrid=True, # Hybrid Search will happen
batch_size=20,
)Step 5: Indexing your doc
By implementing reminiscence and hybrid search in our RAG system, we’ve created a extra clever and context-a
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
paperwork,
storage_context=storage_context,
)
Step 6: Querying the Index Question Engine
Indexing is the half the place we’re defining the retriever and generator chain in LlamaIndex. It processes every doc in our doc assortment and generates embeddings for the content material of every doc. Then It shops these embeddings in our Qdrant vector retailer. It creates an index construction that enables for environment friendly retrieval. Whereas defining the question engine, be sure to question mode in hybrid.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid"
)
response1 = query_engine.question("what's the that means of life?")
print(response1)
response2 = query_engine.question("give the summary inside 2 sentence")
print(response2)Within the above question engine, we run two queries one that’s inside the context and the opposite exterior the context. Right here is the output we acquired:
Output
#response-1
The supplied textual content focuses on the usage of Massive Language Fashions (LLMs) for planning in autonomous brokers.
It doesn't focus on the that means of life.
#response-2
This doc explores the usage of giant language fashions (LLMs) as brokers for fixing complicated duties.
It focuses on two principal approaches:
decomposition-first strategies,
the place the duty is damaged down into sub-tasks earlier than execution, and
interleaved decomposition strategies, which dynamically modify the decomposition based mostly on suggestions. Step 7: Outline Reminiscence
Whereas our chatbot is performing properly and offering improved responses, it nonetheless lacks contextual consciousness throughout a number of interactions. That is the place reminiscence comes into the image.
from llama_index.core.reminiscence import ChatMemoryBuffer
reminiscence = ChatMemoryBuffer.from_defaults(token_limit=3000)Step 8: Making a Chat Engine with Reminiscence
We’ll create a chat engine that makes use of each hybrid search and reminiscence. In LlamaIndex for rag-based purposes when we’ve exterior or exterior knowledge be sure the chat mode is context.
chat_engine = index.as_chat_engine(
chat_mode="context",
reminiscence=reminiscence,
system_prompt=(
"You're an AI assistant who solutions the consumer questions"
),
)Step 9: Testing Reminiscence
Let’s run few queries and verify if the reminiscence is working as anticipated or not.
from IPython.show import Markdown, show
check1 = chat_engine.chat("give the summary inside 2 sentence")
check2 = chat_engine.chat("proceed the summary, add yet another sentence to the earlier two sentence")
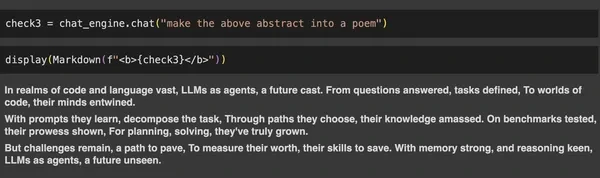
check3 = chat_engine.chat("make the above summary right into a poem")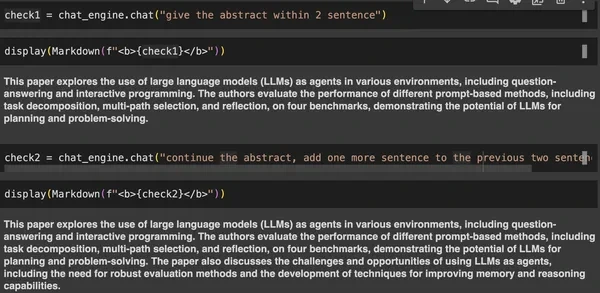
Conclusion
We explored how integrating reminiscence and hybrid search into Retrieval Augmented Era (RAG) programs considerably enhances their capabilities. By utilizing LlamaIndex with Qdrant because the vector retailer and Google’s Gemini because the Massive Language Mannequin, we demonstrated how hybrid search can mix the strengths of vector and keyword-based retrieval to ship extra exact outcomes. The addition of reminiscence additional improved contextual understanding, permitting the chatbot to supply coherent responses throughout a number of interactions. Collectively, these options create a extra clever and context-aware system, making RAG pipelines simpler for complicated AI purposes.
Key Takeaways
- Implementation of a reminiscence element within the RAG pipeline considerably enhances the chatbot’s contextual consciousness and talent to take care of coherent conversations throughout a number of interactions.
- Integration of hybrid search utilizing Qdrant because the vector retailer, combining the strengths of each vector and key phrase search to enhance retrieval accuracy and relevance within the RAG system that minimizes the danger of Hallucination. Disclaimer, it doesn’t fully take away the Hallucination fairly reduces the danger.
- Utilization of LlamaIndex’s ChatMemoryBuffer for environment friendly administration of dialog historical past, with configurable token limits to stability context retention and computational assets.
- Incorporation of Google’s Gemini mannequin because the LLM and embedding supplier inside the LlamaIndex framework showcases the pliability of LlamaIndex in accommodating completely different AI fashions and embedding strategies.
Continuously Requested Questions
A. Hybrid search combines vector seek for semantic understanding and key phrase seek for precision. It improves the accuracy of outcomes by permitting the system to think about each context and precise phrases, main to higher retrieval outcomes, particularly in complicated datasets.
A. Qdrant helps hybrid get hold of of the field, is optimized for quick embeddings, and is scalable. This makes it a dependable selection for implementing each vector and keyword-based search in RAG programs, making certain efficiency at scale.
A. Reminiscence in RAG programs allows the retention of dialog historical past, permitting the chatbot to supply extra coherent and contextually correct responses throughout interactions, considerably enhancing the consumer expertise.
A. Sure, you possibly can run an area LLM (corresponding to Ollama or HuggingFace) as an alternative of utilizing cloud-based APIs like OpenAI. This lets you preserve full management of your knowledge with out importing it to exterior servers, which is a typical concern for privacy-sensitive purposes.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.
Information Scientist at AI Planet || YouTube- AIWithTarun || Google Developer Professional in ML || Received 5 AI hackathons || Co-organizer of TensorFlow Person Group Bangalore || Pie & AI Ambassador at DeepLearningAI