
{kind=link}
Introduction
With the development of AI, scientific analysis has seen a large transformation. Tens of millions of papers are printed yearly on completely different applied sciences and sectors. However, navigating this ocean of knowledge to retrieve correct and related content material is a herculean job. Enter PaperQA, a Retrieval-Augmented Generative (RAG) Agent designed to deal with this precise downside. It’s researched and developed by Jakub Lala ´, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G Rodriques, and Andrew D White.
This progressive device is particularly engineered to help researchers by retrieving data from full-text scientific papers, synthesizing that information, and producing correct solutions with dependable citations. This text explores PaperQA’s advantages, workings, implementation, and limitations.
Overview
- PaperQA is a Retrieval-Augmented Generative (RAG) device designed to help researchers in navigating and extracting data from full-text scientific papers.
- By leveraging Giant Language Fashions (LLMs) and RAG methods, PaperQA gives correct, context-rich responses with dependable citations.
- The Agentic RAG Mannequin in PaperQA autonomously retrieves, processes, and synthesizes data, optimizing solutions based mostly on advanced scientific queries.
- PaperQA performs on par with human specialists, reaching comparable accuracy charges whereas being sooner and extra environment friendly.
- Regardless of its strengths, PaperQA depends on the accuracy of retrieved papers and might battle with ambiguous queries or up-to-date numerical information.
- PaperQA represents a major step ahead in automating scientific analysis, remodeling how researchers retrieve and synthesize advanced data.
PaperQA: A Retrieval-Augmented Generative Agent for Scientific Analysis

As scientific papers proceed to multiply exponentially, it’s turning into more durable for researchers to sift via the ever-expanding physique of literature. In 2022 alone, over 5 million educational papers had been printed, including to the greater than 200 million articles presently obtainable. This large physique of analysis typically ends in important findings going unnoticed or taking years to be acknowledged. Conventional strategies, together with key phrase searches and vector similarity embeddings, solely scratch the floor of what’s potential for retrieving pertinent data. These strategies are sometimes extremely handbook, sluggish, and go away room for oversight.
PaperQA gives a strong answer to this downside by leveraging the potential of Giant Language Fashions (LLMs), mixed with Retrieval-Augmented Technology (RAG) methods. Not like typical LLMs, which might hallucinate or depend on outdated data, PaperQA makes use of a dynamic method to data retrieval, combining the strengths of engines like google, proof gathering, and clever answering, all whereas minimizing errors and bettering effectivity. By breaking the usual RAG into modular parts, PaperQA adapts to particular analysis questions and ensures the solutions offered are rooted in factual, up-to-date sources.
Additionally learn: A Complete Information to Constructing Multimodal RAG Techniques
What’s Agentic RAG?
The Agentic RAG Mannequin refers to a sort of Retrieval-Augmented Technology (RAG) mannequin designed to combine an agentic method. On this context, “agentic” implies the mannequin’s functionality to behave autonomously and determine the way to retrieve, course of, and generate data. It refers to a system the place the mannequin not solely retrieves and augments data but in addition actively manages varied duties or subtasks to optimize for a particular objective.
Break-up of Agentic RAG
- Retrieval-Augmented Technology (RAG): RAG fashions are designed to mix giant language fashions (LLMs) with a retrieval mechanism. These fashions generate responses by utilizing inside data (pre-trained information) and dynamically retrieving related exterior paperwork or data. This improves the mannequin’s skill to reply to queries that require up-to-date or domain-specific data.
- Retrieval: The mannequin retrieves probably the most related paperwork from a big dataset (reminiscent of a corpus of scientific papers).
- Augmented: The era course of is “augmented” by the retrieval step. The retrieval system finds related information, which is then used to enhance the standard, relevance, and factual accuracy of the generated textual content. Basically, exterior data enhances the mannequin, making it extra able to answering queries past its pre-trained data.
- Technology: It generates coherent and contextually related solutions or textual content by leveraging each the retrieved paperwork and its pre-trained data base.
- Agentic: When one thing is described as “agentic,” it implies that it might probably autonomously make selections and carry out actions. Within the context of an RAG mannequin, an agentic RAG system would have the potential to:
- Autonomously determine which paperwork or sources to question.
- Prioritize sure paperwork over others based mostly on the context or consumer question.
- Break down advanced queries into sub-queries and deal with them independently.
- Use a strategic method to pick out data that finest meets the objective of the duty at hand.
Additionally learn: Unveiling Retrieval Augmented Technology (RAG)| The place AI Meets Human Information
PaperQA as an Agentic RAG Mannequin
PaperQA is engineered particularly to be an agentic RAG mannequin designed for working with scientific papers. This implies it’s notably optimized for duties like:
- Retrieving particular, extremely related educational papers or sections of papers.
- Answering detailed scientific queries by parsing and synthesizing data from a number of paperwork.
- Breaking down advanced scientific questions into manageable items and autonomously deciding the very best retrieval and era technique.
Why is PaperQA very best for working with scientific papers?
- Advanced data retrieval: Scientific papers typically include dense, technical data. PaperQA2 can navigate via this complexity by autonomously discovering probably the most related sections of a paper or a bunch of papers.
- Multi-document synthesis: Somewhat than counting on a single supply, it might probably pull in a number of papers, mix insights, and synthesize a extra complete reply.
- Specialization: PaperQA2 is probably going skilled or optimized for scientific language and contexts, permitting it to excel on this particular area.
In abstract, the Agentic RAG Mannequin is a classy system that retrieves related data and generates responses, and autonomously manages duties to make sure effectivity and relevance. PaperQA2 applies this mannequin to the area of scientific papers, making it extremely efficient for educational and analysis functions.
Additionally learn: Enhancing RAG with Retrieval Augmented Effective-tuning
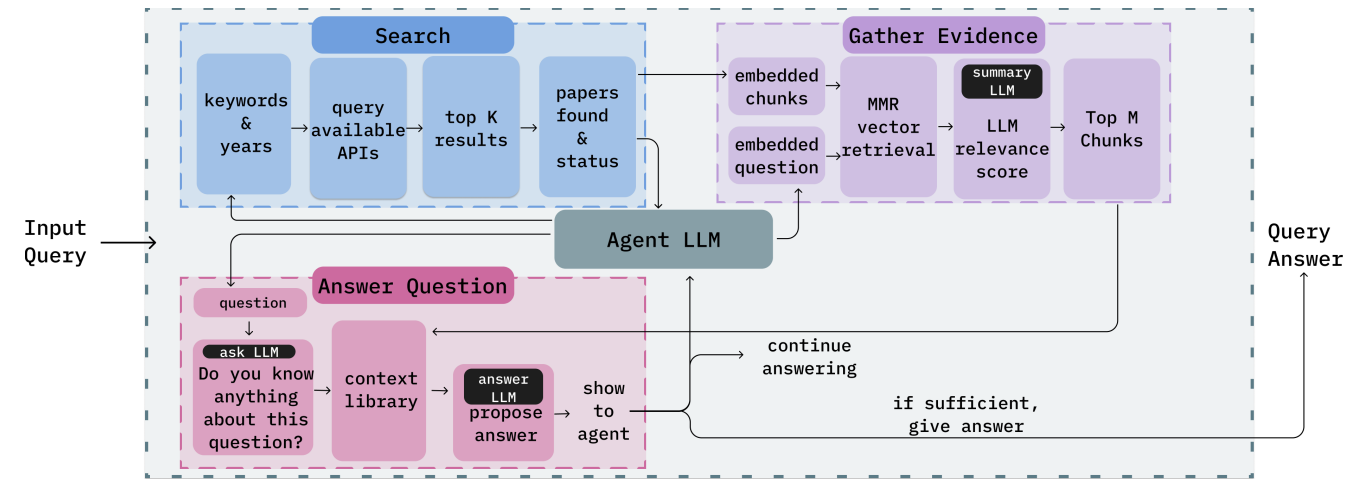
The PaperQA system consists of:

Enter Question
The method begins with an enter question that the consumer enters. This could possibly be a query or a search subject that requires a solution based mostly on scientific papers.
Search Stage
- Key phrases & Years: The enter question is processed, and key phrases or related years are extracted.
- Question Out there APIs: The system queries varied obtainable APIs for scientific papers, probably from databases like arXiv, PubMed, or different repositories.
- High Ok Outcomes: The highest Ok outcomes are retrieved based mostly on the relevance and standing of the papers (whether or not they’re accessible, peer-reviewed, and so forth.).
Collect Proof Stage
- Embedded Chunks: The system breaks down the related papers into embedded chunks, smaller, manageable textual content segments.
- MMR Vector Retrieval: The Most Marginal Relevance (MMR) approach is used to retrieve probably the most related proof from the papers.
- Abstract LLM: A language mannequin (LLM) summarizes the proof extracted from the chunks.
- LLM Relevance Rating: The LLM scores the relevance of the summarized data to evaluate its alignment with the enter question.
- High M Chunks: The highest M most related chunks are chosen for additional processing.
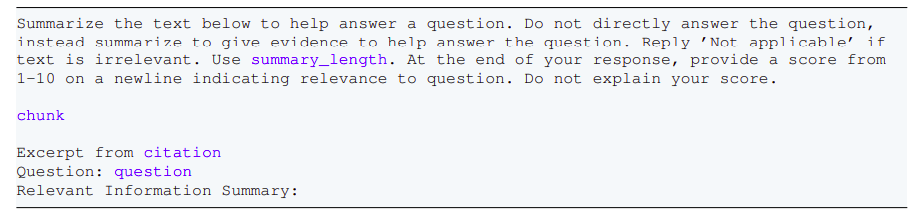
Reply Query Stage
- Query & Context Library: The enter question is analyzed, and the system checks its inside context library to see if it has prior data or solutions associated to the query.
- Ask LLM (Are you aware something about this query?): The system asks the LLM if it has any prior understanding or context to reply the question straight.
- Reply LLM Proposes Reply: The LLM proposes a solution based mostly on the proof gathered and the context of the query.
- Present to Agent: The proposed reply is proven to an agent (which could possibly be a human reviewer or a higher-level LLM for ultimate verification).
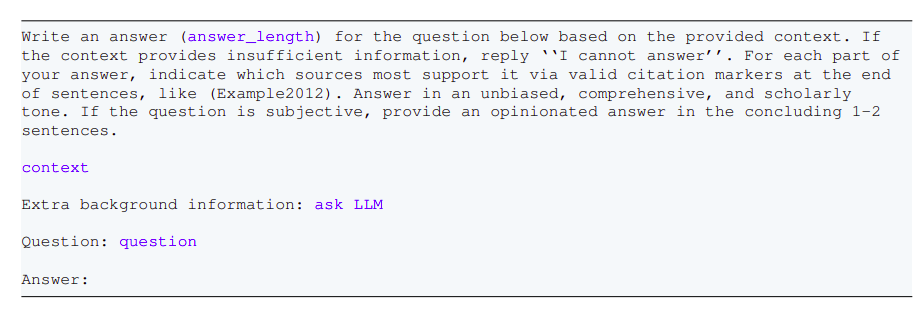
Completion of Answering
- The method is accomplished if the reply is ample and the ultimate Question Reply is offered to the consumer.
- If the reply is inadequate, the method loops again, and the LLM continues gathering proof or rephrasing the enter question to fetch higher outcomes.
This general construction ensures that PaperQA can successfully search, retrieve, summarize, and synthesize data from giant collections of scientific papers to supply a radical and related reply to a consumer’s question. The important thing benefit is its skill to interrupt down advanced scientific content material, apply clever retrieval strategies, and supply evidence-based solutions.
These instruments work in concord, permitting PaperQA to gather a number of items of proof from varied sources, making certain a radical, evidence-based reply is generated. All the course of is managed by a central LLM agent, which dynamically adjusts its technique based mostly on the question’s complexity.
The LitQA Dataset
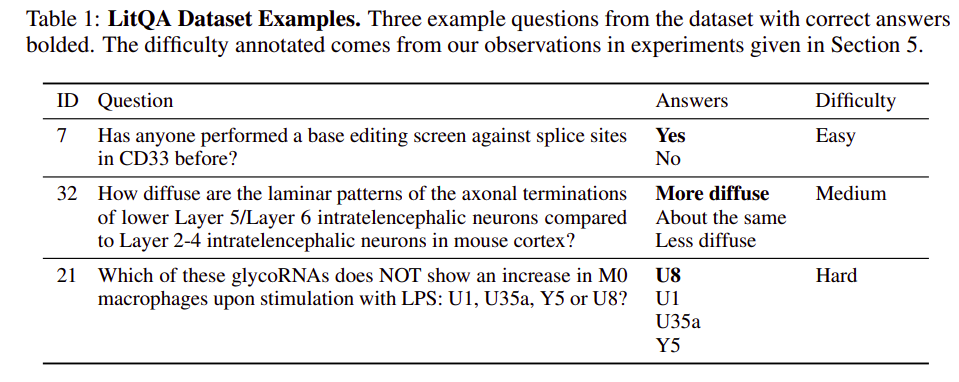
The LitQA dataset was developed to measure PaperQA’s efficiency. This dataset consists of fifty multiple-choice questions derived from latest scientific literature (post-September 2021). The questions span varied domains in biomedical analysis, requiring PaperQA to retrieve data and synthesize it throughout a number of paperwork. LitQA gives a rigorous benchmark that goes past typical multiple-choice science QA datasets, requiring PaperQA to interact in full-text retrieval and synthesis, duties nearer to these carried out by human researchers.
How Does PaperQA Evaluate to Professional People?
In evaluating PaperQA’s efficiency on LitQA, the system was discovered to be extremely aggressive with knowledgeable human researchers. When researchers and PaperQA got the identical set of questions, PaperQA carried out on par with people, exhibiting an identical accuracy charge (69.5% versus 66.8% for people). Furthermore, PaperQA was sooner and cheaper, answering all questions in 2.4 hours in comparison with 2.5 hours for human specialists. One notable power of PaperQA is its decrease charge of answering incorrectly, as it’s calibrated to acknowledge uncertainty when proof is missing, additional decreasing the danger of incorrect conclusions.
PaperQA Implementation
The PaperQA system is constructed on the LangChain agent framework and makes use of a number of LLMs, together with GPT-3.5 and GPT-4, every assigned to completely different duties (e.g., summarizing and answering). The system pulls papers from varied databases, makes use of a map-reduce method to assemble and summarize proof, and generates ultimate solutions in a scholarly tone with full citations. Importantly, PaperQA’s modular design permits it to rephrase questions, regulate search phrases, and retry steps, making certain accuracy and relevance.
Find out how to Use PaperQA by way of Command Line?
Step 1: Set up the required library
Run the next command to put in paper-qa:
pip set up paper-qaStep 2: Arrange your analysis folder
Create a folder and place your analysis paper(s) in it. For instance, I’ve added the paper titled “Consideration is All You Want.”
Step 3: Navigate to your folder
Use the next command to navigate to the folder:
cd folder-nameStep 4: Ask your query
Run the next command to ask a couple of subject:
pqa ask "What's transformers?"Consequence:

Supply and Citations within the Output
- CrossRef: CrossRef is an official database that gives Digital Object Identifiers (DOIs) for educational papers. Nonetheless, it appears just like the search was not in a position to join efficiently to CrossRef, possible as a result of the required setting variables weren’t set (
CROSSREF_API_KEYis lacking). This implies CrossRef couldn’t be used as an information supply for this search. - Semantic Scholar: Equally, it tried to question Semantic Scholar, a preferred educational search engine, however the connection failed on account of lacking an API key (
SEMANTIC_SCHOLAR_API_KEYjust isn’t set). This resulted in a timeout, and no metadata was retrieved. - The system factors to particular pages of the paper (e.g., Vaswani2023 pages 2-3) to make sure that the reader can confirm or additional discover the supply materials. This could possibly be notably helpful in educational or analysis settings.
Accessing utilizing Python
Importing Libraries
import os
from dotenv import load_dotenv
from paperqa import Settings, agent_query, QueryRequest- os: A module offering capabilities to work together with the working system, reminiscent of working with file paths and setting variables.
- dotenv: A module used to load setting variables from a .env file into the setting.
- paperqa: A module from the paperqa library that enables querying scientific papers. It gives courses and capabilities like Settings, agent_query, and QueryRequest for configuring and working queries.
Loading API Keys
load_dotenv()- This operate masses the setting variables from a .env file, usually used to retailer delicate data like API keys, file paths, or different configurations.
- Calling load_dotenv() ensures that the setting variables can be found for the script to entry.
Querying the PaperQA System
reply = await agent_query(
QueryRequest(
question="What's transformers? ",
settings=Settings(temperature=0.5, paper_directory="/house/badrinarayan/paper-qa"),
)
)Right here’s an evidence of the code, damaged down right into a structured and clear format:
Code Breakdown and Rationalization
1. Importing Libraries
pip set up paper-qaimport os
from dotenv import load_dotenv
from paperqa import Settings, agent_query, QueryRequest
- os: A module offering capabilities to work together with the working system, reminiscent of working with file paths and setting variables.
- dotenv: A module used to load setting variables from a
.envfile into the setting. - paperqa: A module from the
paperqalibrary that enables querying scientific papers. It gives courses and capabilities likeSettings,agent_query, andQueryRequestfor configuring and working queries.
2. Loading Setting Variables
load_dotenv()- This operate masses the setting variables from a
.envfile, usually used to retailer delicate data like API keys, file paths, or different configurations. - By calling
load_dotenv(), it ensures that the setting variables can be found to be accessed within the script.
3. Querying the PaperQA System
reply = await agent_query(
QueryRequest(
question="What's transformers? ",
settings=Settings(temperature=0.5, paper_directory="/house/badrinarayan/paper-qa"),
)
)This a part of the code queries the PaperQA system utilizing an agent and structured request. It performs the next steps:
agent_query(): That is an asynchronous operate used to ship a question to the PaperQA system.- It’s anticipated to be known as with the
awaitkey phrase since it’s anasyncoperate, which means it runs concurrently with different code whereas awaiting the outcome.
- It’s anticipated to be known as with the
QueryRequest: This defines the construction of the question request. It takes the question and settings as parameters. On this case:- question:
"What's transformers?"is the analysis query being requested of the system. It expects a solution drawn from the papers within the specified listing. - settings: This passes an occasion of
Settingsto configure the question, which incorporates:- temperature: Controls the “creativity” of the reply generated. Decrease values like
0.5make the response extra deterministic (factual), whereas greater values generate extra diversified solutions. - paper_directory: Specifies the listing the place PaperQA ought to search for analysis papers to question, on this case,
"/house/badrinarayan/paper-qa".
- temperature: Controls the “creativity” of the reply generated. Decrease values like
- question:
OUTPUT
Query: What's transformers?The Transformer is a neural community structure designed for sequence
transduction duties, reminiscent of machine translation, that depends solely on
consideration mechanisms, eliminating the necessity for recurrence and convolutions.
It options an encoder-decoder construction, the place each the encoder and decoder
include a stack of six equivalent layers. Every encoder layer features a
multi-head self-attention mechanism and a position-wise totally linked
feed-forward community, using residual connections and layer
normalization. The decoder incorporates an extra sub-layer for multi-
head consideration over the encoder's output and makes use of masking to make sure auto-
regressive era (Vaswani2023 pages 2-3).The Transformer improves parallelization and reduces coaching time in contrast
to recurrent fashions, reaching state-of-the-art ends in translation
duties. It set a BLEU rating of 28.4 on the WMT 2014 English-to-German job
and 41.8 on the English-to-French job after coaching for 3.5 days on eight
GPUs (Vaswani2023 pages 1-2). The mannequin's effectivity is additional enhanced by
decreasing the variety of operations wanted to narrate indicators from completely different
positions to a continuing, leveraging Multi-Head Consideration to keep up
efficient decision (Vaswani2023 pages 2-2).Along with translation, the Transformer has demonstrated robust
efficiency in duties like English constituency parsing, reaching excessive F1
scores in each supervised and semi-supervised settings (Vaswani2023 pages 9-
10).References
1. (Vaswani2023 pages 2-3): Vaswani, Ashish, et al. "Consideration Is All You
Want." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.2. (Vaswani2023 pages 1-2): Vaswani, Ashish, et al. "Consideration Is All You
Want." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.3. (Vaswani2023 pages 9-10): Vaswani, Ashish, et al. "Consideration Is All You
Want." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.4. (Vaswani2023 pages 2-2): Vaswani, Ashish, et al. "Consideration Is All You
Want." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.
Supply and Citations within the Output
The system seems to depend on exterior databases, reminiscent of educational databases or repositories, to reply the query. Based mostly on the references, it’s extremely possible that this specific system is querying sources like:
- arXiv.org: A well known open-access repository for analysis papers, notably centered on laptop science, synthetic intelligence, and machine studying fields. The references to “arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7” level on to the seminal paper “Consideration is All You Want” by Ashish Vaswani et al. (2017), which launched the Transformer mannequin.
- Different potential sources that could possibly be queried embody educational repositories like Semantic Scholar, Google Scholar, or PubMed, relying on the subject. Nonetheless, for this particular job, it looks as if the system primarily relied on arXiv because of the nature of the paper cited.
- The system factors to particular pages of the paper (e.g., Vaswani2023 pages 2-3) to make sure that the reader can confirm or additional discover the supply materials. This could possibly be notably helpful in educational or analysis settings.
Limitations of PaperQA
Regardless of its strengths, PaperQA just isn’t with out limitations. First, its reliance on present analysis papers means it assumes that the data within the sources is correct. If defective papers are retrieved, PaperQA’s solutions could possibly be flawed. Furthermore, the system can battle with ambiguous or imprecise queries that don’t align with the obtainable literature. Lastly, whereas the system successfully synthesizes data from full-text papers, it can not but deal with real-time calculations or duties that require up-to-date numerical information.
Conclusion
In conclusion, PaperQA represents a leap ahead within the automation of scientific analysis. By integrating retrieval-augmented era with clever brokers, PaperQA transforms the analysis course of, slicing down the time wanted to seek out and synthesize data from advanced literature. Its skill to dynamically regulate, retrieve full-text papers, and iterate on solutions brings the world of scientific question-answering one step nearer to human-level experience, however with a fraction of the associated fee and time. As science advances at breakneck pace, instruments like PaperQA will play a pivotal function in making certain researchers can sustain and push the boundaries of innovation.
Additionally, try the brand new course on AI Agent: Introduction to AI Brokers
Steadily Requested Questions
Ans. PaperQA is a Retrieval-Augmented Generative (RAG) device designed to assist researchers navigate and extract related data from full-text scientific papers, synthesizing solutions with dependable citations.
Ans. Not like conventional search instruments that depend on key phrase searches, PaperQA makes use of Giant Language Fashions (LLMs) mixed with retrieval mechanisms to drag information from a number of paperwork, producing extra correct and context-rich responses.
Ans. The Agentic RAG Mannequin permits PaperQA to autonomously retrieve, course of, and generate data by breaking down queries, managing duties, and optimizing responses utilizing an agentic method.
Ans. PaperQA competes nicely with human researchers, reaching comparable accuracy charges (round 69.5%) whereas answering questions sooner and with fewer errors.
Ans. PaperQA’s limitations embody potential reliance on defective sources, issue with ambiguous queries, and an incapacity to carry out real-time calculations or deal with up-to-date numerical information.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Captivated with storytelling and crafting compelling narratives that remodel concepts into impactful content material. I really like studying about know-how revolutionizing our way of life.