
{kind=link}
Introduction
Vector streaming in EmbedAnything is being launched, a function designed to optimize large-scale doc embedding. Enabling asynchronous chunking and embedding utilizing Rust’s concurrency reduces reminiscence utilization and accelerates the method. At this time, I’ll present combine it with the Weaviate Vector Database for seamless picture embedding and search.
In my earlier article, Supercharge Your Embeddings Pipeline with EmbedAnything, I mentioned the thought behind EmbedAnything and the way it makes creating embeddings from a number of modalities simple. On this article, I wish to introduce a brand new function of EmbedAnything referred to as vector streaming and see the way it works with Weaviate Vector Database.
Overview
- Vector streaming in EmbedAnything optimizes embedding large-scale paperwork utilizing asynchronous chunking with Rust’s concurrency.
- It solves reminiscence and effectivity points in conventional embedding strategies by processing chunks in parallel.
- Integration with Weaviate permits seamless embedding and looking out in a vector database.
- Implementing vector streaming entails making a database adapter, initiating an embedding mannequin, and embedding knowledge.
- This method gives a extra environment friendly, scalable, and versatile resolution for large-scale doc embedding.
What’s the drawback?
First, study the present drawback with creating embeddings, particularly in large-scale paperwork. The present embedding frameworks function on a two-step course of: chunking and embedding. First, the textual content is extracted from all of the information, and chunks/nodes are created. Then, these chunks are fed to an embedding mannequin with a particular batch measurement to course of the embeddings. Whereas that is achieved, the chunks and the embeddings keep on the system reminiscence.
This isn’t an issue when the information and embedding dimensions are small. However this turns into an issue when there are lots of information, and you’re working with massive fashions and, even worse, multi-vector embeddings. Thus, to work with this, a excessive RAM is required to course of the embeddings. Additionally, if that is achieved synchronously, a whole lot of time is wasted whereas the chunks are being created, as chunking is just not a compute-heavy operation. Because the chunks are being made, passing them to the embedding mannequin can be environment friendly.
Our Resolution to the Downside
The answer is to create an asynchronous chunking and embedding process. We are able to successfully spawn threads to deal with this process utilizing Rust’s concurrency patterns and thread security. That is achieved utilizing Rust’s MPSC (Multi-producer Single Client) module, which passes messages between threads. Thus, this creates a stream of chunks handed into the embedding thread with a buffer. As soon as the buffer is full, it embeds the chunks and sends the embeddings again to the principle thread, which then sends them to the vector database. This ensures no time is wasted on a single operation and no bottlenecks. Furthermore, the system shops solely the chunks and embeddings within the buffer, erasing them from reminiscence as soon as they’re moved to the vector database.
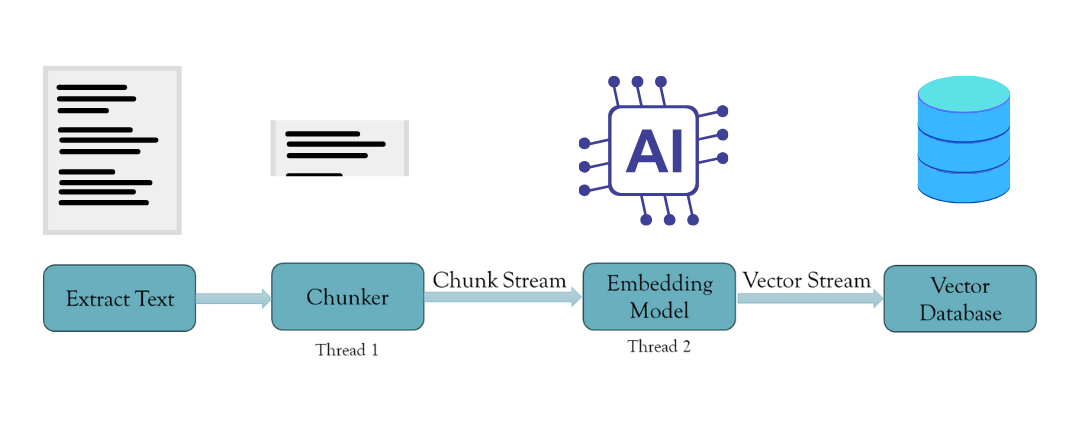
Instance Use Case with EmbedAnything
Now, let’s see this function in motion:
With EmbedAnything, streaming the vectors from a listing of information to the vector database is an easy three-step course of.
- Create an adapter to your vector database: This can be a wrapper across the database’s features that permits you to create an index, convert metadata from EmbedAnything’s format to the format required by the database, and the perform to insert the embeddings within the index. Adapters for the outstanding databases have already been created and are current right here.
- Provoke an embedding mannequin of your selection: You may select from totally different native fashions and even cloud fashions. The configuration may also be decided by setting the chunk measurement and buffer measurement for what number of embeddings must be streamed without delay. Ideally, this must be as excessive as attainable, however the system RAM limits this.
- Name the embedding perform from EmbedAnything: Simply cross the listing path to be embedded, the embedding mannequin, the adapter, and the configuration.
On this instance, we’ll embed a listing of photos and ship it to the vector databases.
Step 1: Create the Adapter
In EmbedAnything, the adapters are created exterior in order to not make the library heavy and also you get to decide on which database you wish to work with. Right here is an easy adapter for Weaviate:
from embed_anything import EmbedData
from embed_anything.vectordb import Adapter
class WeaviateAdapter(Adapter):
def __init__(self, api_key, url):
tremendous().__init__(api_key)
self.shopper = weaviate.connect_to_weaviate_cloud(
cluster_url=url, auth_credentials=wvc.init.Auth.api_key(api_key)
)
if self.shopper.is_ready():
print("Weaviate is prepared")
def create_index(self, index_name: str):
self.index_name = index_name
self.assortment = self.shopper.collections.create(
index_name, vectorizer_config=wvc.config.Configure.Vectorizer.none()
)
return self.assortment
def convert(self, embeddings: Record[EmbedData]):
knowledge = []
for embedding in embeddings:
property = embedding.metadata
property["text"] = embedding.textual content
knowledge.append(
wvc.knowledge.DataObject(properties=property, vector=embedding.embedding)
)
return knowledge
def upsert(self, embeddings):
knowledge = self.convert(embeddings)
self.shopper.collections.get(self.index_name).knowledge.insert_many(knowledge)
def delete_index(self, index_name: str):
self.shopper.collections.delete(index_name)
### Begin the shopper and index
URL = "your-weaviate-url"
API_KEY = "your-weaviate-api-key"
weaviate_adapter = WeaviateAdapter(API_KEY, URL)
index_name = "Test_index"
if index_name in weaviate_adapter.shopper.collections.list_all():
weaviate_adapter.delete_index(index_name)
weaviate_adapter.create_index("Test_index")Step 2: Create the Embedding Mannequin
Right here, since we’re embedding photos, we will use the clip mannequin
import embed_anything import WhichModel
mannequin = embed_anything.EmbeddingModel.from_pretrained_cloud(
embed_anything.WhichModel.Clip,
model_id="openai/clip-vit-base-patch16")Step 3: Embed the Listing
knowledge = embed_anything.embed_image_directory(
"image_directory",
embeder=mannequin,
adapter=weaviate_adapter,
config=embed_anything.ImageEmbedConfig(buffer_size=100),
)Step 4: Question the Vector Database
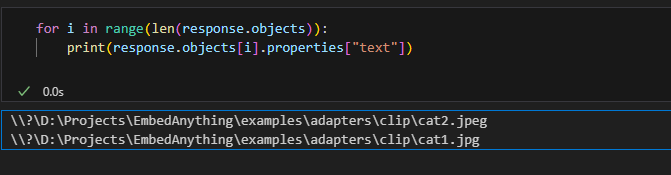
query_vector = embed_anything.embed_query(["image of a cat"], embeder=mannequin)[0].embeddingStep 5: Question the Vector Database
response = weaviate_adapter.assortment.question.near_vector(
near_vector=query_vector,
restrict=2,
return_metadata=wvc.question.MetadataQuery(certainty=True),
)
Verify the response;Output
Utilizing the Clip mannequin, we vectorized the entire listing with photos of cats, canine, and monkeys. With the straightforward question “photos of cats, ” we have been capable of search all of the information for photos of cats.
Take a look at the pocket book for the code right here on colab.
Conclusion
I feel vector streaming is without doubt one of the options that may empower many engineers to go for a extra optimized and no-tech debt resolution. As an alternative of utilizing cumbersome frameworks on the cloud, you should utilize a light-weight streaming choice.
Take a look at the GitHub repo over right here: EmbedAnything Repo.
Often Requested Questions
Ans. Vector streaming is a function that optimizes large-scale doc embedding through the use of Rust’s concurrency for asynchronous chunking and embedding, decreasing reminiscence utilization and dashing up the method.
Ans. It addresses excessive reminiscence utilization and inefficiency in conventional embedding strategies by processing chunks asynchronously, decreasing bottlenecks and optimizing useful resource use.
Ans. It makes use of an adapter to attach EmbedAnything with the Weaviate Vector Database, permitting seamless embedding and querying of knowledge.
Ans. Listed here are steps:
1. Create a database adapter.
2. Provoke an embedding mannequin.
3. Embed the listing.
4. Question the vector database.
Ans. It gives higher effectivity, decreased reminiscence utilization, scalability, and adaptability in comparison with conventional embedding strategies.
AI Developer @ Serpentine AI || TU Eindhoven
Making Starlight – Semantic Search Engine for Home windows in Rust 🦀.
Constructing EmbedAnything – A minimal embeddings pipeline constructed on Candle.
I like watching massive AI fashions practice.