
{kind=link}
Introduction
The transformer-based diffusion fashions are bettering daily and have confirmed to revolutionize the text-to-image technology mannequin. The capabilities of transformers improve the scalability and efficiency of any mannequin, thereby growing the mannequin’s complexity.
💡
“With nice energy comes nice accountability“
On this case, with nice mannequin complexities comes nice energy and reminiscence consumptions.
For example, working inference with fashions like Secure Diffusion 3 requires an enormous GPU reminiscence, because of the involvement of parts—textual content encoders, diffusion backbones, and picture decoders. This excessive reminiscence requirement causes set again for these utilizing consumer-grade GPUs, which hampers each accessibility and experimentation.
Enter Mannequin Quantization. Think about with the ability to scale down a resource-hungry mannequin to a extra manageable measurement with out sacrificing its effectiveness. Quantization, is like compressing a high-resolution picture right into a extra compact format, transforms the mannequin’s parameters into lower-precision representations. This not solely reduces reminiscence utilization but additionally hurries up computations, making complicated fashions extra accessible and simpler to work with.
On this publish, we discover how Quanto’s quantization instruments can considerably improve the reminiscence effectivity of Transformer-based diffusion pipelines.
Introducing Quanto: A Versatile PyTorch Quantization Backend
Quantization is a vital method for decreasing the computational and reminiscence calls for of Deep Studying Fashions, making them extra appropriate for deployment on client gadgets. By utilizing low-precision information sorts like 8-bit integers (int8) as a substitute of 32-bit floating factors (float32), quantization not solely decreases reminiscence storage necessities but additionally allows optimizations for particular {hardware}, equivalent to int8 or float8 matrix multiplications on CUDA gadgets.
Introducing Quanto, a brand new quantization backend for Optimum, designed to supply a flexible and simple quantization course of. Quanto stands out with its complete assist for varied options, guaranteeing compatibility with various mannequin configurations and gadgets:
- Keen Mode Compatibility: Works seamlessly with non-traceable fashions.
- Gadget Flexibility: Quantized fashions might be deployed on any gadget, together with CUDA and MPS.
- Automated Integration: Inserts quantization/dequantization stubs, purposeful operations, and quantized modules robotically.
- Streamlined Workflow: Gives a simple transition from a float mannequin to each dynamic and static quantized fashions.
- Serialization Help: Suitable with PyTorch
weight_onlyand 🤗 Safetensors codecs. - Accelerated Matrix Multiplications: Helps varied quantization codecs (int8-int8, fp16-int4, bf16-int8, bf16-int4) on CUDA gadgets.
- Large Vary of Help: Handles int2, int4, int8, and float8 weights and activations.
Whereas many instruments give attention to making massive AI fashions smaller, Quanto is designed to be easy and helpful for every kind of fashions.
Quanto Workflow
To put in Quanto utilizing pip, please use the code beneath:-
!pip set up optimum-quanto- Quantize a Mannequin
The beneath code will assist to transform a typical mannequin to a quantized mannequin
from optimum.quanto import quantize, qint8
quantize(mannequin, weights=qint8, activations=qint8)- Calibrate
Quanto’s calibration mode ensures that the quantization parameters are adjusted to the precise information distributions within the mannequin, enhancing the accuracy and effectivity of the quantized mannequin.
from optimum.quanto import Calibration
with Calibration(momentum=0.9):
mannequin(samples)
- Quantization-Conscious-Coaching
In case the mannequin efficiency is effected one can tune the mannequin for few epochs to boost the mannequin efficiency.
import torch
mannequin.practice()
for batch_idx, (information, goal) in enumerate(train_loader):
information, goal = information.to(gadget), goal.to(gadget)
optimizer.zero_grad()
output = mannequin(information).dequantize()
loss = torch.nn.purposeful.nll_loss(output, goal)
loss.backward()
optimizer.step()
- Freeze integer weights
Whereas freezing the mannequin, the float weights will get transformed to quantized weights.
from optimum.quanto import freeze
freeze(mannequin)H100 Benchmarking Research
The H100 GPU is a high-performance graphics card designed particularly for demanding AI duties, together with coaching and inference for giant fashions like transformers and diffusion fashions. Right here’s why it’s chosen for this benchmark:
- Prime-tier Efficiency: The H100 gives distinctive pace and energy, making it ultimate for dealing with complicated operations required by massive fashions like text-to-image and text-to-video technology pipelines.
- Help for FP16: This GPU effectively handles computations in FP16 (half-precision floating level), which reduces reminiscence utilization and hurries up calculations with out considerably sacrificing accuracy.
- Superior {Hardware} Options: The H100 helps optimized operations for mixed-precision coaching and inference, making it a superb selection for quantization strategies that purpose to scale back mannequin measurement whereas sustaining efficiency.
Within the benchmarking examine, the primary focus is on making use of Quanto, a brand new quantization device, to diffusion fashions. Whereas quantization is well-known amongst practitioners of Giant Language Fashions (LLMs), it’s much less generally used with diffusion fashions. Quanto is used to discover whether or not it may present reminiscence financial savings in these fashions with little or no loss in high quality.
This is what the examine includes:
- Surroundings Setup:
- CUDA 12.2: The model of CUDA used, which is essential for working computations on the H100 GPU.
- PyTorch 2.4.0: The deep studying framework used for mannequin coaching and inference.
- Diffusers: A library used for constructing and working diffusion fashions, put in from a selected commit to make sure consistency.
- Quanto: The quantization device, additionally put in from a selected commit.
- Computations in FP16: By default, all computations have been carried out in FP16 to scale back reminiscence utilization and improve pace. Nonetheless, the VAE (Variational Autoencoder) isn’t quantized to keep away from potential numerical instability.
- Give attention to Key Pipelines: For this examine, three transformer-based diffusion pipelines are chosen from Diffusers. These pipelines are chosen as a result of they signify a number of the most superior fashions for text-to-image technology, making them ultimate for testing the effectiveness of Quanto in decreasing reminiscence utilization whereas sustaining mannequin high quality.
- PixArt-Sigma
- Secure Diffusion 3
- Aura Circulation
By utilizing the H100 GPU and specializing in these key fashions, the examine goals to reveal the potential of Quanto to bridge the hole between LLMs and diffusion fashions when it comes to quantization, providing vital reminiscence financial savings with minimal impression on efficiency.
Making use of Quanto to Quantize a DiffusionPipeline
Quantizing a mannequin utilizing quanto follows a simple course of:-
First set up the required packages, right here we’re putting in transformers, quanto, torch, sentencepiece. Nonetheless please observe you would possibly want to put in a number of extra packages as per requirement.
!pip set up transformers==4.35.0
!pip set up quanto==0.0.11
!pip set up torch==2.1.1
!pip set up sentencepiece==0.2.0
!pip set up optimum-quanto
The quantize() perform known as on the module to be quantized, specifying the parts focused for quantization. On this context, solely the parameters are being quantized, whereas the activations stay unchanged. The parameters are quantized to the FP8 information kind. Lastly, the freeze() perform is invoked to interchange the unique parameters with the newly quantized ones.
from optimum.quanto import freeze, qfloat8, quantize
from diffusers import PixArtSigmaPipeline
import torch
pipeline = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16
).to("cuda")
quantize(pipeline.transformer, weights=qfloat8)
freeze(pipeline.transformer)
As soon as accomplished use the pipeline.
picture = pipeline("ghibli fashion, a fantasy panorama with castles").pictures[0]

The beneath code can be utilized to quantize the textual content encoder.
quantize(pipeline.text_encoder, weights=qfloat8)
freeze(pipeline.text_encoder)
The textual content encoder, being a transformer mannequin as properly, can be quantized. By quantizing each the textual content encoder and the diffusion spine, considerably larger reminiscence financial savings are achieved.
LLM Pipelines
💡
optimum-quanto offers helper lessons to quantize, save and reload Hugging Face quantized fashions.
The code beneath will load the pre-trained language mannequin (Meta-Llama-3-8B) utilizing the Transformers library. It then applies quantization to the mannequin utilizing the QuantizedModelForCausalLM class from Optimum Quanto, particularly changing the mannequin’s weights to the qint4 information kind. The lm_head (output layer) is excluded from quantization to protect its precision, guaranteeing that the ultimate output high quality stays excessive.
from transformers import AutoModelForCausalLM
from optimum.quanto import QuantizedModelForCausalLM, qint4
mannequin = AutoModelForCausalLM.from_pretrained('meta-llama/Meta-Llama-3-8B')
qmodel = QuantizedModelForCausalLM.quantize(mannequin, weights=qint4, exclude="lm_head")# quantized mannequin might be saved utilizing save_pretrained
qmodel.save_pretrained('./Llama-3-8B-quantized')
# reload the mannequin utilizing from_pretrained
from optimum.quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM.from_pretrained('Llama-3-8B-quantized')Integrations with the Transformers
Quanto seamlessly integrates with the Hugging Face transformers library. Any mannequin might be quantized by simply passing the mannequin by means of QuantoConfig.
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "fb/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)
💡
With Quanto you’ll be able to quantize and run your mannequin regardless if utilizing CPU/GPU/ MPS (Apple Silicon).
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
mannequin = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)
Tensors in Quanto:
- What Quanto Does: Quanto works with particular Tensors (information constructions) that it modifies to suit into smaller information sorts, like int8 or float8. This makes the mannequin extra memory-efficient and quicker to run.
- Conversion Course of:
- For floating-point numbers, it merely makes use of PyTorch’s built-in conversion.
- For integers, it rounds the numbers to suit them into the smaller information kind.
- Accuracy: Quanto tries to maintain the conversion correct by avoiding too many excessive values (both too massive or too small) that may distort the mannequin’s efficiency.
- Optimized Operations: Utilizing these smaller information sorts (lower-bitwidth) permits the mannequin to run quicker as a result of the operations for these sorts are faster.
Modules in Quanto:
- Changing Torch Modules: Quanto can swap out common PyTorch parts with particular Quanto variations that work with these smaller Tensors.
- Weight Conversion: When the mannequin continues to be being fine-tuned, the weights (the mannequin’s adjustable parameters) are dynamically transformed, which could sluggish issues down a bit. However as soon as the mannequin is finalized (frozen), this conversion stops.
- Biases: Biases (one other set of mannequin parameters) aren’t transformed as a result of changing them would both cut back accuracy or require very excessive precision, making it inefficient.
- Activations: The mannequin’s activations (intermediate outputs) are additionally transformed to smaller information sorts, however solely after the mannequin is calibrated to search out the very best conversion settings.
Modules That Can Be Quantized:
- Linear Layers: These are totally related layers within the mannequin the place weights are at all times quantized, however biases are left as they’re.
- Conv2D Layers: These are convolutional layers typically utilized in picture processing. Right here, weights are additionally at all times quantized, and biases aren’t.
- LayerNorm: This normalizes information within the mannequin. In Quanto, the outputs might be quantized, however weights and biases are left as they’re.
This setup permits fashions to turn into smaller and quicker whereas nonetheless sustaining a superb degree of accuracy.
Ultimate Observations from the Research
Quantizing the textual content encoder in diffusion fashions, equivalent to these utilized in Secure Diffusion, can considerably have an effect on efficiency and reminiscence effectivity. For Secure Diffusion 3, which makes use of three completely different textual content encoders, the observations associated to quantizing these encoders are as follows:
- Quantizing the Second Textual content Encoder: This method doesn’t work properly, seemingly because of the particular traits of the second encoder.
- Quantizing the First Textual content Encoder (CLIPTextModelWithProjection): This feature is really helpful and customarily efficient, as the primary encoder’s quantization offers a superb stability between reminiscence financial savings and efficiency.
- Quantizing the Third Textual content Encoder (T5EncoderModel): This method can be really helpful. Quantizing the third encoder can result in substantial reminiscence financial savings with out considerably impacting the mannequin’s efficiency.
- Quantizing Each the First and Third Textual content Encoders: Combining the quantization of each the primary and third textual content encoders generally is a good technique for maximizing reminiscence effectivity whereas sustaining acceptable efficiency ranges.
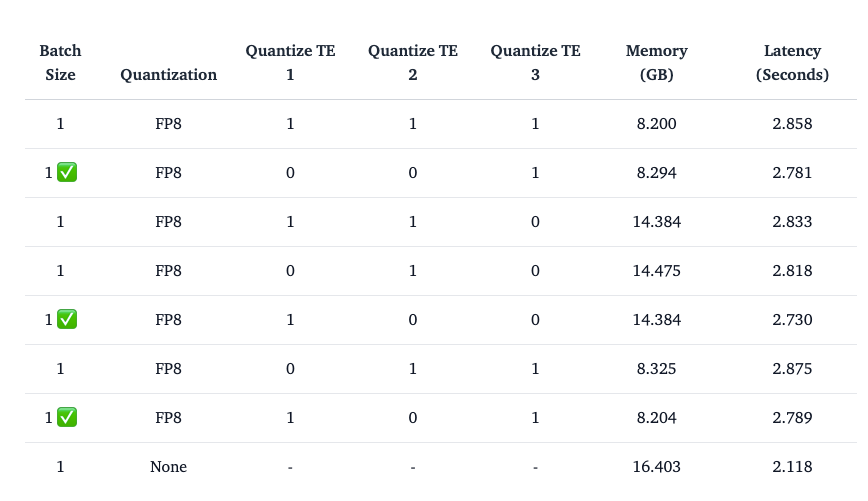
- Quantizing the diffusion transformer in all circumstances ensures that the noticed reminiscence financial savings are primarily because of the textual content encoder quantization.
- Utilizing the bfloat16 might be quicker when highly effective GPUs equivalent to H100 or 4090 are thought-about.
qint8is usually quicker for inference because of environment friendly integer operations and {hardware} optimization.- Fusing QKV Projections thickens the int8 kernels, which optimizes computation additional by decreasing the variety of operations and leveraging environment friendly information processing.
- When utilizing
qint4withbfloat16on an H100 GPU, outcomes enhancements in reminiscence utilization as a result ofqint4makes use of solely 4 bits per worth, which reduces the quantity of reminiscence wanted to retailer the weights. Nonetheless, this comes at the price of elevated inference latency. It’s because the H100 GPU nonetheless doesn’t assist computations with 4-bit integers (int4). Though the weights are saved in a compressed 4-bit format, the precise computations are nonetheless carried out inbfloat16(a 16-bit floating-point format), which suggests the {hardware} has to deal with extra complicated operations, resulting in slower processing instances.
Conclusions
Quanto gives a robust quantization backend for PyTorch, optimizing mannequin efficiency by changing weights to decrease precision codecs. By supporting strategies like qint8 and qint4, Quanto reduces reminiscence consumption and hurries up inference. Moreover, Quanto works throughout completely different gadgets (CPU, GPU, MPS) and is suitable with varied setups. Nonetheless, on MPS gadgets, utilizing float8 will trigger an error.
General, Quanto allows extra environment friendly deployment of deep studying fashions, balancing reminiscence financial savings with efficiency trade-offs.