{kind=link}

Introduction
Vector databases are specialised databases that retailer knowledge as high-dimensional vectors. These vectors function mathematical representations of options or attributes, with dimensions starting from tens to hundreds primarily based on the complexity of the info. They’re designed to handle high-dimensional knowledge that conventional Database Administration Techniques (DBMS) battle to deal with successfully. Vector databases are essential for purposes involving pure language processing, laptop imaginative and prescient, advice techniques, and different fields requiring correct similarity search and retrieval capabilities.
Vector databases excel in quick and correct similarity search, surpassing conventional databases that depend on actual matches or predefined standards. They assist advanced and unstructured knowledge like textual content, photographs, audio, and video, remodeling them into high-dimensional vectors to seize their attributes effectively. On this article, we are going to talk about completely different indexing algorithms in vector databases.
Overview
- Vector databases use high-dimensional vectors for managing advanced knowledge sorts.
- Tree-based indexing improves search effectivity by partitioning vector area.
- Hashing-based indexing accelerates retrieval utilizing hash capabilities.
- Graph-based indexing enhances similarity searches with node and edge relationships.
- Quantization-based indexing compresses vectors for quicker retrieval.
- Future developments will concentrate on scalability, numerous knowledge dealing with, and higher mannequin integration.
What’s Tree-based Indexing?
Tree-based indexing strategies, like k-d timber and ball timber, are utilized in vector databases to carry out actual searches and group factors in hyperspheres effectively. These algorithms divide vector area into areas, permitting for systematic searches primarily based on proximity and distance. Tree-based indexing allows fast retrieval of nearest neighbors by recursively partitioning the info area, bettering search effectivity. The hierarchical construction of timber organizes knowledge factors, making it simpler to find related factors primarily based on their dimensions.
Tree-based indexing in vector databases units distance bounds to hurry up knowledge retrieval and improve search effectivity. This method optimizes retrieval by navigating the info area to seek out the closest neighbors successfully. The principle tree-based strategies used are:
Approximate Nearest Neighbors Oh Yeah (annoy)
It’s a method for quick and correct similarity search in high-dimensional knowledge utilizing binary timber. Every tree splits the vector area with random hyperplanes, assigning vectors to leaf nodes. Annoy traverses every tree to gather candidate vectors from the identical leaf nodes to seek out related vectors, then calculates actual distances to return the highest okay nearest neighbors.

Finest Bin First
This technique finds a vector’s nearest neighbors by utilizing a kd-tree to divide knowledge into bins and looking the closest bin first. This technique reduces search time and improves accuracy by specializing in promising bins and avoiding far-off factors. Efficiency is determined by components like knowledge dimensionality, variety of bins, and distance strategies, with challenges like dealing with noisy knowledge and selecting good break up factors.
Ok-means tree
It’s a technique to group high-dimensional knowledge right into a tree construction, the place every node is a cluster. It makes use of k-means clustering at every stage and repeats till the tree reaches a sure depth or dimension. Assigning a degree to a cluster makes use of the Euclidean norm. Factors are assigned to leaf nodes in the event that they belong to all ancestor nodes. The closest neighbor search makes use of candidate factors from tree branches. Quick and correct similarity search by following tree branches. Helps including and eradicating factors by updating the tree.
What’s Hashing-based Indexing?
Hashing-based indexing is utilized in vector databases to effectively retailer and retrieve high-dimensional vectors, providing a quicker different than conventional strategies like B-trees or hash tables. Hashing reduces the complexity of looking high-dimensional vectors by remodeling the vectors into hash keys, permitting for faster retrieval primarily based on similarity or distance metrics. Hash capabilities map vectors to particular index positions, enabling quicker searches for approximate nearest neighbors (ANN), thus enhancing the search efficiency of the database.
Hashing strategies in vector databases present flexibility to deal with several types of vector knowledge, together with dense, sparse, and binary vectors, adapting to diverse knowledge traits and necessities. Hashing-based indexing helps scalability and effectivity by effectively distributing workload and optimizing useful resource utilization throughout a number of machines or clusters, which is essential for large-scale knowledge evaluation and real-time processing in AI purposes. There are three hashing-based strategies primarily utilized in vector databases:
Native-sensitive Hashing
It’s designed to take care of vector locality the place related vectors have increased possibilities of sharing related hash codes. Completely different hash operate households cater to varied distance and similarity metrics, similar to Euclidean distance and cosine similarity. LSH reduces reminiscence utilization and search time by evaluating binary codes as an alternative of unique vectors, adapting properly to dynamic datasets. LSH permits for the insertion and deletion of codes with out affecting present ones, providing scalability and suppleness in vector databases.
Spectral hashing
It’s a method used to seek out approximate nearest neighbors in giant vector collections by using spectral graph concept. It generates hash capabilities to reduce quantization error and maximize binary code variance, balancing even distribution and knowledge richness. The algorithm goals to reduce the variance of every binary operate and maximize mutual data amongst completely different capabilities, guaranteeing informative and discriminative codes. Spectral hashing solves an optimization downside with a trade-off parameter for variance and mutual data. Components influencing spectral hashing, challenges, and extensions mirror these of local-sensitive hashing, together with noise dealing with, graph Laplacian choice, and enhanced recall via a number of hash capabilities.
Deep hashing
Deep hashing makes use of neural networks to create compact binary codes from high-dimensional vectors, boosting retrieval effectivity. It balances reconstruction and quantization loss to take care of knowledge constancy and reduce code discrepancies. Hash capabilities convert vectors to binary codes, saved in a hash desk for similarity-based retrieval. Success is determined by neural community design, loss operate, and code bit depend. Challenges embrace dealing with noise, community initialization, and bettering recall with a number of hash capabilities.
Listed here are some related reads:
| Articles | Supply |
| Prime 15 Vector Databases 2024 | Hyperlinks |
| How Do Vector Databases Form the Way forward for Generative AI Options? | Hyperlinks |
| What’s a Vector Database? | Hyperlinks |
| Vector Databases: 10+ Actual-World Functions Remodeling Industries | Hyperlinks |
What’s Graph-based Indexing?
Graph-based indexing in vector databases includes representing knowledge as nodes and relationships as edges in a graph construction. This permits context-aware retrieval and extra clever querying primarily based on the relationships between knowledge factors. This method helps vector databases seize semantic connections, making similarity searches extra correct by contemplating knowledge which means and context. Graph-based indexing improves querying by utilizing graph traversal algorithms to navigate knowledge effectively, boosting search efficiency and dealing with advanced queries on high-dimensional knowledge. Storing relationships within the graph construction reveals hidden patterns and associations, benefiting purposes like advice techniques and graph analytics. Graph-based indexing supplies a versatile technique for representing numerous knowledge sorts and complicated relationships. There are two graph-based strategies that are usually utilized in vector databases:
Navigable Small World
It’s a graph-based method utilized in vector databases to effectively retailer and retrieve high-dimensional vectors primarily based on their similarity or distance. The NSW algorithm builds a graph connecting every vector to its nearest neighbors, together with random long-range hyperlinks that span completely different areas of the vector area. Lengthy-range hyperlinks created in NSW introduce shortcuts, enhancing traversal pace like social networks’ properties. NSW’s graph-based method gives scalability benefits, making it appropriate for dealing with large-scale and real-time knowledge evaluation in vector databases. The tactic balances accuracy and effectivity trade-offs, guaranteeing efficient question processing and retrieval of high-dimensional vectors throughout the database.
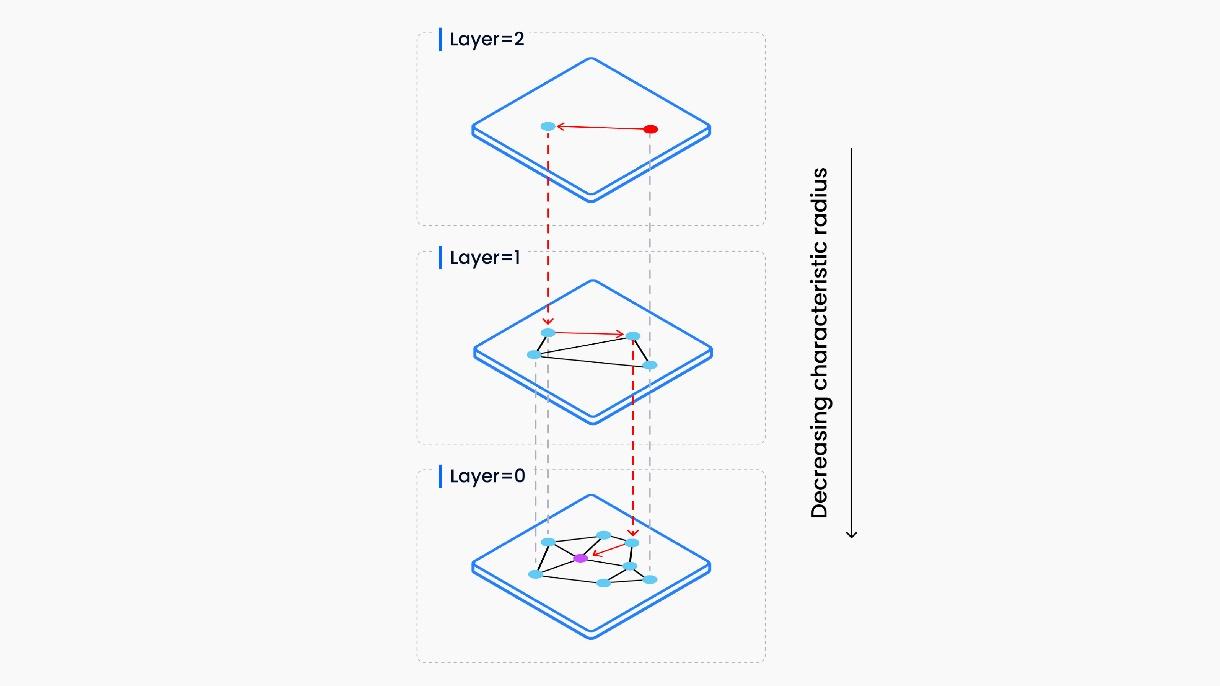
Hierarchical Navigable Small World
The HNSW technique organizes vectors into completely different layers with various chances, the place increased layers embrace fewer factors with longer edges, and decrease layers have extra factors with shorter edges. The algorithm builds a hierarchical graph construction connecting vectors primarily based on similarity or distance, using a multi-layered method to retrieve nearest neighbors effectively. Every layer in HNSW has a managed variety of neighbors per level, influencing search efficiency throughout the database. HNSW makes use of an entry level within the highest layer for searches, with parameters like the utmost neighbors (M) controlling traversal and question operations.
Additionally Learn: Introduction to HNSW: Hierarchical Navigable Small World
What’s Quantization-based Indexing?
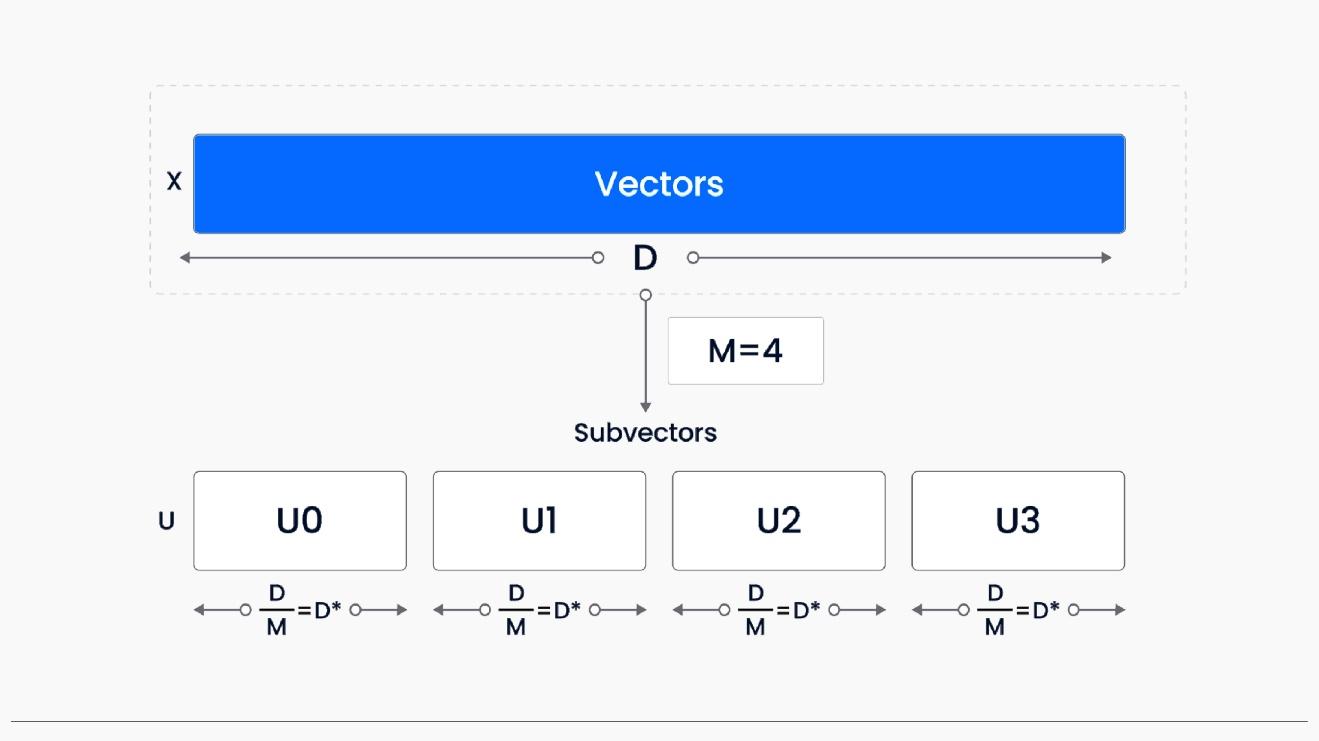
Quantization-based indexing compresses high-dimensional vectors into smaller, environment friendly representations, decreasing storage and enhancing retrieval pace. This includes dividing vectors into subvectors, making use of clustering algorithms like k-means, and creating compact codes. By minimizing space for storing and simplifying vector comparisons, this system allows quicker and extra scalable search operations, bettering efficiency for approximate nearest-neighbor searches and similarity queries. Quantization strategies permit vector databases to deal with giant volumes of high-dimensional knowledge effectively, making them perfect for real-time processing and evaluation. There are three major quantization primarily based indexing strategies obtainable:
Product Quantization
It’s a method for compressing high-dimensional vectors into extra environment friendly representations. OPQ enhances PQ by optimizing area decomposition and codebooks to reduce quantization distortions.
Optimized Product Quantization
It’s a variation of PQ, which focuses on minimizing quantization distortions by optimizing area decomposition and codebooks. It improves data loss and enhances code discriminability.
On-line Product Quantization
This method makes use of an internet studying method with parameters α (studying charge) and β (forgetting charge) to replace codebooks and codes for subvectors. It ensures steady enchancment in encoding processes.
Beneath is a comparability of those indexing algorithms in vector databases primarily based on their efficiency metrics like pace, accuracy, reminiscence utilization, and so forth., and in addition the Commerce-offs between completely different algorithms we have to make earlier than selecting these algorithms.
The Comparability Desk
Right here is the comparability of indexing algorithms in vector databases:
| Strategy | Pace | Accuracy | Reminiscence Utilization | Commerce-offs |
|---|---|---|---|---|
| Tree-Primarily based | Environment friendly for low to reasonably high-dimensional knowledge; efficiency degrades in increased dimensions | Excessive in decrease dimensions; effectiveness diminishes in increased dimensions | Typically, quick for indexing and querying by hashing related objects into the identical buckets | Correct and environment friendly for low-dimensional knowledge; much less efficient and extra memory-intensive as dimensionality will increase |
| Hash-Primarily based | Typically quick for indexing and querying by hashing related objects into the identical buckets | Decrease accuracy attributable to potential hash collisions | Reminiscence-efficient by storing solely hash codes, not the unique vectors | Quick question instances however diminished accuracy attributable to hash collisions |
| Graph-Primarily based | Quick search instances by leveraging graph buildings for environment friendly traversal | Excessive accuracy utilizing grasping search technique to seek out most related vectors | Reminiscence-intensive attributable to storing graph construction; HNSW optimizes reminiscence with hierarchical layers | Excessive accuracy and quick search instances however requires vital reminiscence for storing graph construction |
| Quantization-Primarily based | Quick search instances by compressing vectors into smaller codes | Excessive accuracy is determined by codebook high quality and variety of centroids used | Extremely memory-efficient by storing compact codes as an alternative of unique vectors | Important reminiscence financial savings and quick search instances, however accuracy will be affected by the extent of quantization |
Challenges and Future Instructions in Vector Databases
Vector databases stand on the forefront of contemporary knowledge administration, providing highly effective options for dealing with high-dimensional knowledge. Nevertheless, they face quite a few challenges that push the boundaries of computational effectivity and knowledge group. One of many major hurdles is the sheer complexity of indexing and looking billions of high-dimensional vectors. Conventional strategies battle with the curse of dimensionality, requiring specialised strategies like approximate nearest neighbor (ANN) search, hashing, and graph-based strategies. These approaches steadiness pace and accuracy whereas evolving to satisfy the calls for of data-intensive purposes.
The range of vector knowledge sorts presents one other vital problem. From dense to sparse to binary vectors, every sort comes with its traits and necessities. Vector databases should adapt their indexing techniques to deal with this heterogeneity effectively, guaranteeing optimum efficiency throughout numerous knowledge landscapes. Scalability and efficiency loom giant on the horizon of vector database growth. As knowledge evaluation scales, techniques should use sharding, partitioning, and replication strategies to beat conventional database bottlenecks and guarantee quick responses for AI and knowledge science purposes. Knowledge high quality and variety additionally play essential roles, significantly in coaching giant language fashions (LLMs). Vector databases should rise to the problem of supporting subtle knowledge administration strategies to make sure the reliability and robustness of those fashions.
In a nutshell, Future developments in vector databases will improve LLM integration, allow cross-modal searches, and enhance real-time information retrieval. Ongoing analysis focuses on adapting to dynamic knowledge and optimizing reminiscence and effectivity, promising transformative impacts throughout numerous industries.
Conclusion
Vector databases are pivotal in managing high-dimensional knowledge, providing superior efficiency for similarity searches in comparison with conventional databases. By remodeling advanced knowledge into high-dimensional vectors, they excel in dealing with unstructured knowledge like textual content, photographs, and video. Numerous indexing strategies—tree-based, hashing-based, graph-based, and quantization-based—every supply distinctive benefits and trade-offs in pace, accuracy, and reminiscence utilization.
Regardless of their strengths, vector databases face challenges similar to dealing with numerous knowledge sorts, scaling effectively, and sustaining excessive accuracy. We count on future developments to enhance integration with giant language fashions, allow cross-modal searches, and improve real-time retrieval capabilities. These developments will proceed to drive the evolution of vector databases, making them more and more important for stylish knowledge administration and evaluation throughout industries.
Regularly Requested Questions
Ans. Indexing algorithms are strategies used to arrange and shortly retrieve vectors (knowledge factors) from a database primarily based on similarity or distance metrics.
Ans. They enhance the effectivity of querying giant datasets by decreasing search area and rushing up retrieval.
Ans. Frequent algorithms embrace KD-Bushes, R-Bushes, Locality-Delicate Hashing (LSH), and Approximate Nearest Neighbor (ANN) strategies.
Ans. The selection is determined by components like the kind of knowledge, the dimensions of the dataset, question pace necessities, and the specified trade-off between accuracy and efficiency.