{kind=link}

Retrieval-augmented technology (RAG) permits giant language fashions (LLMs) to reply questions utilizing exterior data sources. Nonetheless, it wants assist with international questions on complete textual content corpora, resembling figuring out important themes. Microsoft’s current analysis proposed Graph RAG in April, which mixes RAG and Question Focussed Summarization or QFS strategies for scalable query answering over personal textual content corpora. Graph RAG makes use of an LLM to create a graph-based textual content index, deriving an entity data graph and producing neighborhood summaries of associated entities. When a query is requested, these summaries generate partial responses which might be mixed right into a ultimate reply. Graph RAG considerably improves the comprehensiveness and variety of solutions for international questions over giant datasets in comparison with a fundamental RAG method.
Limitations of Retrieval-Augmented Technology (RAG)
RAG Limitations: RAG is efficient for answering questions when the solutions are discovered inside particular, retrievable textual content areas. Nevertheless, it wants assist with extra basic questions that require summarizing data from a whole dataset.
QFS Relevance: Question-focused summarization (QFS) is extra appropriate for these basic questions as a result of it generates pure language summaries based mostly on the question moderately than simply extracting textual content excerpts.
Developments in LLMs: Fashionable giant language fashions (LLMs) like GPT, Llama, and Gemini have improved all forms of summarization duties, making distinctions between totally different sorts of summarization (abstractive vs. extractive, single-document vs. multi-document) much less important.
Challenges with Giant Corpora: Regardless of these developments, summarizing complete corpora stays difficult as a result of the textual content quantity usually exceeds the context window of LLMs, resulting in potential lack of data.
Potential Options: A brand new type of pre-indexing may improve RAG approaches, particularly for international summarization duties, by higher organizing and summarizing giant datasets.
Graph RAG is a novel method that makes use of international summarization of a data graph created by an LLM. In contrast to earlier strategies specializing in structured graph retrieval, this method leverages the graph’s modularity to divide it into intently associated teams or communities.
Right here’s the way it works:
- Group Summaries: The LLM generates summaries for these communities, offering a whole overview of the graph and the paperwork it covers.
- Question Answering: A map-reduce methodology is used to reply queries. First, every neighborhood abstract is used to create partial solutions independently. Then, these partial solutions are mixed to type a ultimate, complete response.
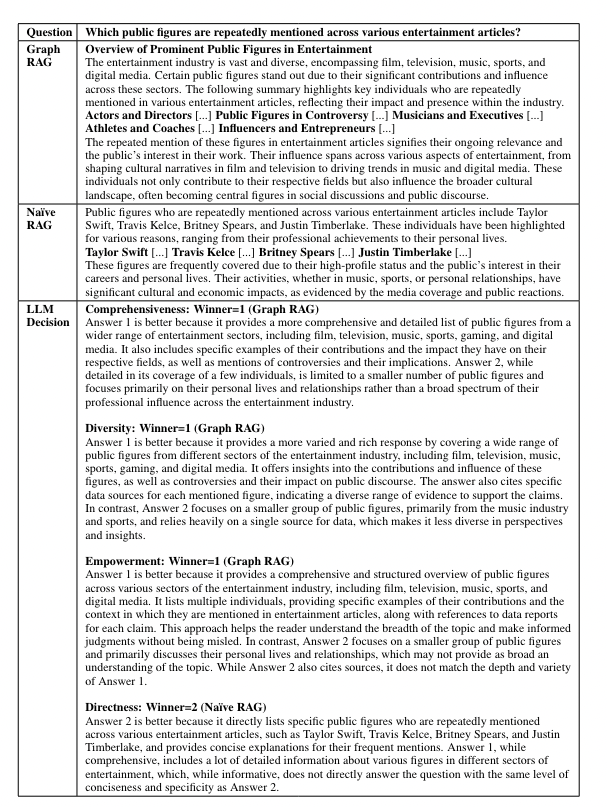
To check this method, various real-world datasets, together with podcast transcripts and information articles, are used to see how effectively it handles questions on broad themes and points. Moreover, Graph RAG approaches are in comparison with conventional RAG strategies, and it was discovered that the Graph RAG method gives extra complete and various solutions at decrease prices, particularly when utilizing summaries from intermediate and decrease ranges of the neighborhood hierarchy.
Introduction to Graph RAG
Graph RAG is an idea based mostly on a data graph, which mixes with a big language mannequin to offer clever, cost-effective, and extra correct search outcomes.
Graph RAG goals to beat the restrictions of conventional RAG strategies by leveraging graph constructions for higher group and summarization of data, particularly when coping with in depth and complicated datasets.
Graph RAG combines graph expertise with retrieval-augmented technology to boost how giant language fashions (LLMs) course of and perceive complicated data. Here is a breakdown:
- Graph Database: It organizes data as a community of interconnected nodes (entities) and edges (relationships). This construction is right for representing complicated contexts and relationships in a graphical format.
- Information Graph: By constructing a data graph, you present a wealthy, structured context that helps LLMs higher perceive how totally different entities relate and work together. This improves the LLM’s capacity to specific and motive in regards to the data.
- Graph RAG Idea:
- Information Graph as Vocabulary: In Graph RAG, the data graph is handled like an enormous vocabulary the place entities and relationships are akin to phrases.
- Modeling Entities and Relationships: It collectively fashions entities and relationships throughout retrieval. This implies it may well extra precisely grasp the intent behind a question and ship extra exact outcomes.
Graph RAG leverages the structured, interconnected nature of data graphs to boost LLMs’ retrieval and technology capabilities, main to raised understanding and responses to complicated queries.
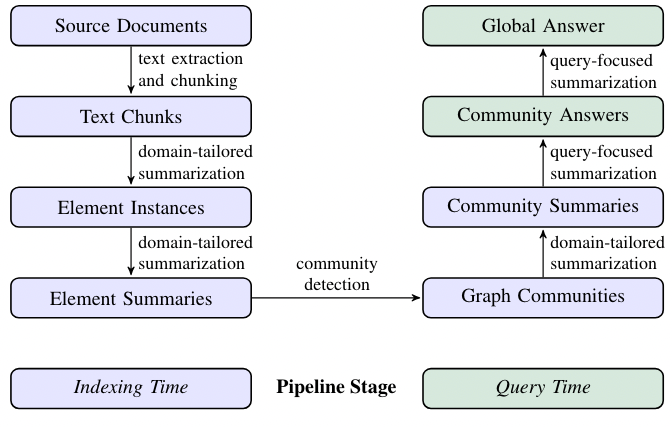
Supply Paperwork → Textual content Chunks
When processing textual content from supply paperwork, a key determination is how you can cut up the textual content into chunks. Every chunk is then used with LLM prompts to construct a graph index. Longer chunks imply fewer LLM calls however can scale back recall as a result of limitations of lengthy context home windows in LLMs. Due to this fact, discovering a steadiness between recall and precision is vital to get the most effective outcomes.
Textual content Chunks → Aspect Cases
This step entails extracting graph nodes and edges from textual content chunks utilizing a multipart LLM immediate. The immediate first identifies entities, together with their names, varieties, and descriptions, after which identifies relationships between them, detailing the supply and goal entities and their connections. This data is output as an inventory of delimited tuples. To create the immediate for particular domains, we use few-shot examples related to the area, resembling science or legislation, enhancing extraction accuracy. Moreover, a secondary immediate extracts covariates like claims associated to the entities, together with particulars like topic, object, and dates. To make sure complete extraction, we use a number of rounds of “gleanings,” the place the LLM assesses if any entities have been missed after which tries to detect these missed entities in subsequent rounds. This method helps preserve top quality even with bigger chunk sizes, avoiding high quality loss or pointless noise.
Aspect Cases → Aspect Summaries
On this step, an LLM is used to create summaries of entities, relationships, and claims from textual content, a type of abstractive summarization. The LLM generates significant descriptions of ideas. Subsequent, these particular person descriptions are additional summarized into cohesive blocks of textual content for every graph component (entity, relationship, declare). There could also be inconsistent references to the identical entity, resulting in duplicates. Nonetheless, that is manageable because the LLM can perceive totally different names for a similar entity, and our method teams associated entities collectively. This methodology ensures wealthy, descriptive summaries that help international, query-focused summarization, distinguishing our method from conventional data graphs that use concise, fixed-format triples.
Aspect Summaries → Graph Communities
On this step, the index from the earlier stage is was an undirected, weighted graph the place nodes characterize entities and edges characterize relationships between them, with weights displaying the energy of those relationships. To make sense of this graph, we use the Leiden algorithm, which effectively finds communities or teams of nodes which might be intently related. This algorithm helps to interrupt down the graph into hierarchical layers, every displaying totally different ranges of neighborhood construction. This hierarchical partitioning successfully summarizes your complete graph by specializing in smaller, manageable teams of associated nodes.
This step creates an in depth abstract of every neighborhood within the Leiden hierarchy. These summaries assist perceive the general construction and that means of the dataset, even with out a particular query. As an illustration, a consumer can learn by summaries at a broader stage to seek out basic themes after which dive into extra detailed summaries at decrease ranges for particular matters. On this case, these neighborhood summaries are helpful for answering broad, international queries by offering well-organized and significant data from the graph.
Given a consumer question, the neighborhood summaries generated within the earlier step can be utilized to create a ultimate reply in a multi-stage course of.
Right here’s how the neighborhood summaries are used to reply a consumer question:
- Put together Summaries: First, shuffle and cut up the neighborhood summaries into manageable chunks. This helps unfold vital data so it’s not multi function place.
- Generate Solutions: For every chunk, partial solutions are created utilizing an LLM, which additionally charges how useful every reply is for the question. Low-scored solutions are discarded.
- Mix Solutions: The solutions are sorted by their rating; they’re added collectively right into a single context window, after which this mixed context is used to generate the ultimate reply for the consumer.
This methodology helps ensures an intensive and related response to the question.
What’s a Information Graph?
A data graph sometimes consists of nodes, edges, and labels. An edge represents the connection between the nodes.
- Nodes: These characterize entities, which might be something of curiosity, resembling individuals, locations, organizations, ideas, or objects.
- Edges: These are the connections between nodes, representing relationships or interactions between the entities. For instance, an edge would possibly present that an individual “works for” an organization or {that a} product “belongs to” a class.
- Labels: Labels characterize the kind of relationship.
A data graph might be known as a structured database that represents data in an interconnected approach. The general construction is a community the place entities are related, permitting for complicated relationships and information to be expressed to spotlight how totally different items of data are associated.
A Paperspace Demo
Carry this venture to life
On this house, we are going to discover how you can run Graph RAG Native with Ollama utilizing an interactive Gradio software. Microsoft’s Graph RAG model has been tailored to help native fashions with Ollama integration. Moreover, please word Ollama handles each LLMs and embeddings. This venture additionally features a new interactive consumer interface. Moreover, this venture may be very current and evolving quickly.
Earlier than we bounce to the set up steps, allow us to shortly undergo a number of of this venture’s notable options.
- Native Mannequin Help: Helps native fashions resembling llama3 and mistral with Ollama for LLM and embeddings.
- Interactive UI: Person-friendly interface for managing information, working queries, and visualizing outcomes. Moreover, it even gives a graph visualization choice
- Price-Efficient: Eradicate dependency on pricey OpenAI fashions.
- File Administration: Add, view, edit, and delete enter recordsdata instantly from the UI. Nevertheless, whereas attempting it out, I confronted points whereas importing textual content recordsdata.
- Settings Administration: Simply replace Graph RAG settings by the Gradio UI.
- Output Exploration: Browse and think about indexing outputs and artifacts.
Earlier than beginning with the installations, we extremely suggest that you simply create a separate setting. In any other case, chances are you’ll come throughout dependency points.
You may log in to the Paperspace console and open up a brand new terminal.
- Create and activate the setting.
python -m venv tutorial-env
supply tutorial-env/bin/activate
- Set up Ollama and pull the mistral mannequin together with the embedding mannequin; in our case, we are going to pull ‘mxbai-embed-large’ as our embedding mannequin.
ollama pull mxbai-embed-largeWe have now an in depth weblog publish on putting in Ollama and pull mannequin. We extremely suggest that our readers click on the hyperlink and take a look at the weblog.
As soon as every thing is put in, we are going to transfer to the following step.
- Git clone the repository and set up the necessities.txt
git clone https://github.com/severian42/GraphRAG-Native-UI.git && cd GraphRAG-Native-UIpip set up -r necessities.txt- Run the code under to start out the dwell Gradio app.
python app.pyAnd there you go! The UI of Graph RAG is dwell.
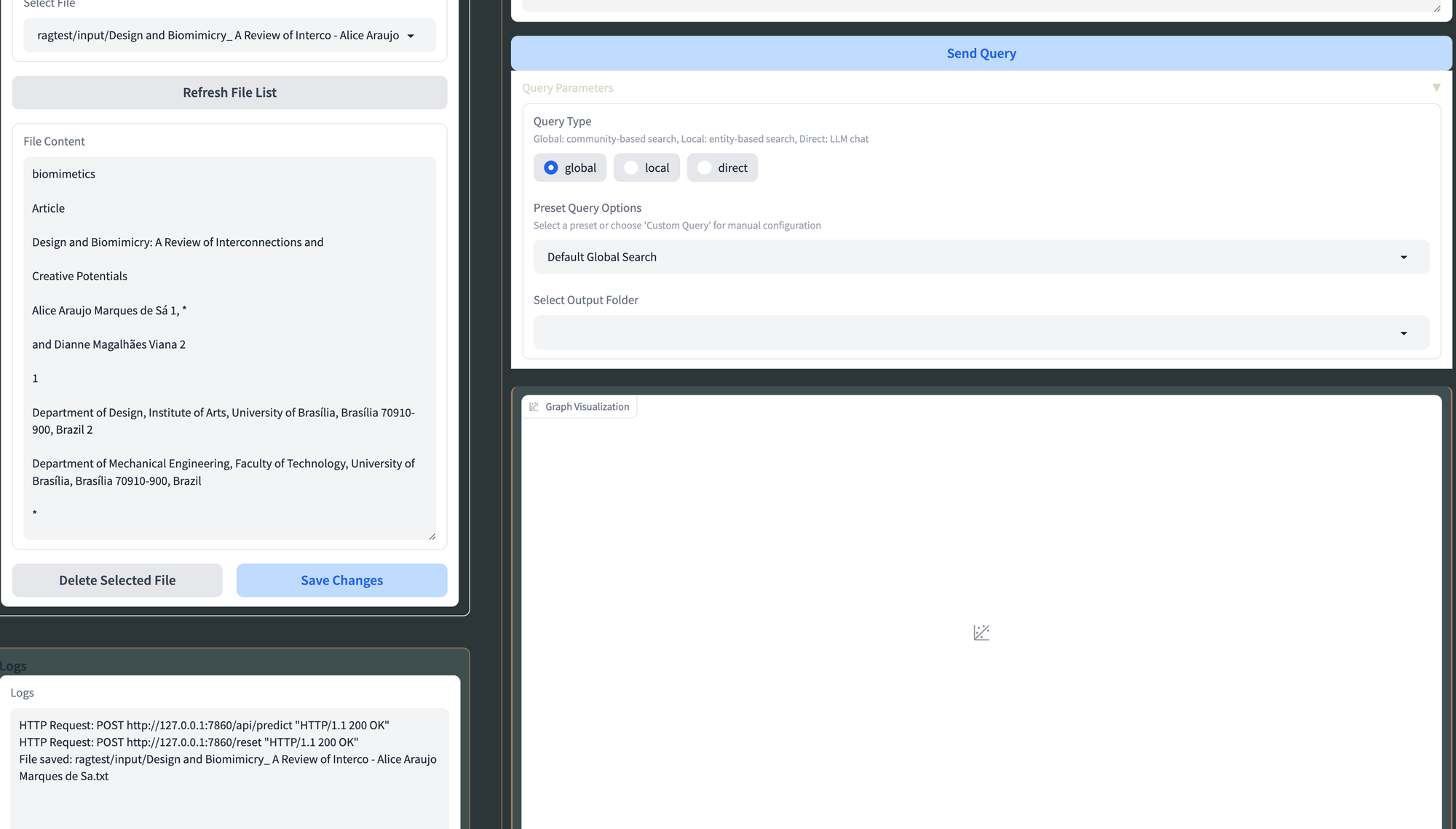
In information administration, you may both click on on this feature or navigate to file operations, the place you may add your textual content file or choose an current one.
In Knowledge Administration, you may add .txt recordsdata to the enter listing by way of the “File Add” part within the “Knowledge Administration” tab. You may view, edit, and delete these recordsdata within the “File Administration” part, and refresh the checklist of accessible recordsdata with the “Refresh File Record” button. To configure indexing, go to the “Indexing” tab, set the basis listing (default is “./ragtest”), and optionally add a config file.
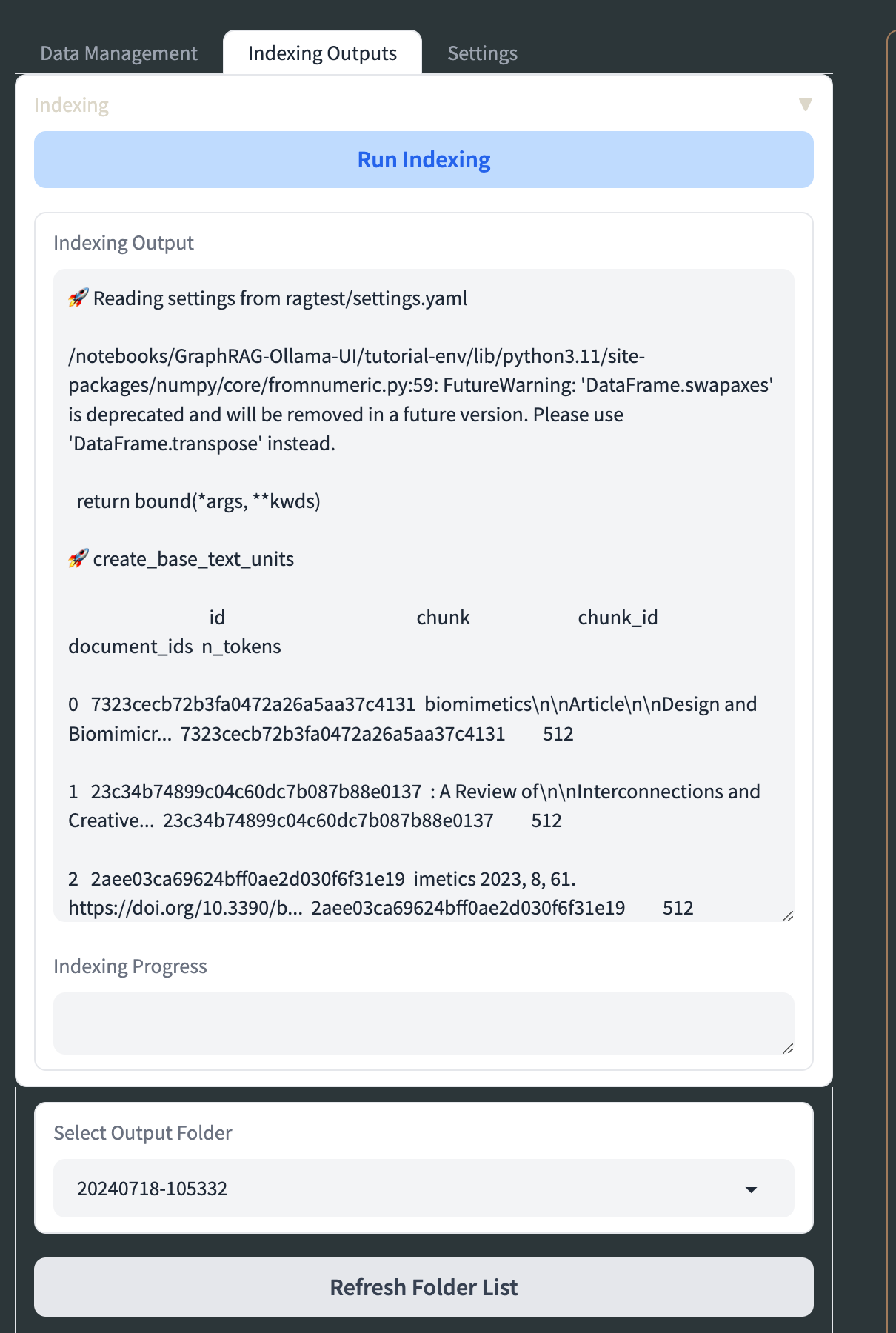
Modify parameters like verbosity, caching, and output codecs earlier than clicking “Run Indexing” to start out the method, with real-time progress monitoring accessible. If wanted, you may halt the method utilizing “Cease Indexing.” Within the “KG Chat/Outputs” part, you may discover listed information by deciding on an output folder, viewing file contents, and producing visualizations of your data graph from Graph ML recordsdata. Customise these visualizations utilizing the “Visualization Settings” accordion.
For LLM settings, configure API base URLs and keys for each LLM and embeddings, select the service sort, choose fashions, and regulate parameters resembling system message, context window, temperature, and max tokens. Save these modifications by clicking “Replace LLM Settings.” When querying, choose the question sort (international, native, or direct chat), select a preset choice or customise question parameters, enter your question, and think about ends in the chat interface. Extra Graph RAG settings might be adjusted within the “YAML Settings” tab as wanted.
For Ollama: Use fashions like llama2, mistral, phi-2, and so on. Discover the entire checklist of Ollama fashions right here.
💡
If you cannot run gradio app.py, attempt working pip set up --upgrade gradio after which exit out and begin a brand new terminal.
How one can Effortlessly Lease GPUs on Paperspace
Paperspace is extremely environment friendly in offering GPU sources, providing a scalable resolution for each particular person and enterprise wants. The platform delivers highly effective GPUs on-demand, which might be simply rented and managed by the platform. Paperspace helps a spread of GPU varieties and configurations, from entry-level choices for gentle duties to high-end GPUs resembling H100 for intensive computations. This flexibility permits customers to pick the suitable sources based mostly on their particular workload necessities.
Moreover, Paperspace’s infrastructure ensures excessive availability and efficiency, with international information facilities. Automated scaling and pay-as-you-go pricing fashions additional improve effectivity, permitting customers to optimize prices by paying just for the sources they use.
So as to use Paperspace GPUs, begin by creating an account or logging into your current Paperspace account on their web site.
As soon as you might be logged in to the workspace. Click on on “Create Challenge,” it will open up the Challenge web page. Subsequent, click on the “Create” tab to create a venture.
Now, from right here we are able to launch a pocket book utilizing the machine of your selection. Choose a machine. Flick thru the accessible GPU plans and choose the one that most closely fits your wants. Paperspace presents numerous choices based mostly on efficiency and pricing.
Be sure that to verify and regulate the Auto-shutdown timeout to your fascinating time. As soon as finished click on on begin pocket book. And there you go!
Get pleasure from versatile billing with Paperspace’s pay-as-you-go pricing mannequin, making certain you pay for the GPU sources you really use.
This streamlined course of permits you to effectively lease and handle GPUs, focusing in your tasks with out the effort of complicated configurations or lengthy setup instances.
Conclusion
Graph RAG is a robust idea that mixes data graph creation, retrieval-augmented technology (RAG), and query-focused summarization (QFS) to boost understanding of enormous textual content corpora. The analysis outcomes reveals that it considerably outperforms fundamental RAG strategies in reply high quality and is aggressive with international approaches like map-reduce summarization, however at a decrease token price. For datasets with frequent international queries, utilizing summaries from top-level communities within the graph index presents a superior and cost-effective resolution in comparison with naïve RAG.
This analysis on Graph RAG has targeted on particular sensemaking questions for datasets round 1 million tokens. Additional analysis is required to evaluate how efficiency varies with totally different query varieties, information codecs, and dataset sizes, and to validate our metrics with finish customers. Whereas Graph RAG constantly outperforms different strategies, less complicated graph-free summarization approaches are additionally aggressive. Choices about utilizing a graph index ought to contemplate components resembling compute prices, question frequency, and the added worth of the graph’s neighborhood summaries.
Future work may refine Graph RAG by integrating extra native RAG strategies, embedding-based question matching, and hybrid approaches that mix these with neighborhood summaries. Exploring these strategies throughout numerous ranges of the neighborhood hierarchy may additionally present deeper insights and higher data retrieval.
We hope you loved studying the article!