{kind=link}

Introduction
Think about a world the place coding turns into as seamless as conversing with a good friend, the place advanced programming duties are tackled with only a few prompts. This isn’t science fiction—that is CodeLlama, the revolutionary device leveraging Meta’s Llama 2 mannequin to remodel the best way we write and perceive code. On this article, we’ll delve into how CodeLlama can improve your growth course of, making code technology, commenting, conversion, optimization, and debugging extra environment friendly than ever earlier than. Let’s discover how this highly effective open-source mannequin is reshaping the way forward for coding.
Studying Targets
- Perceive how CodeLlama enhances code technology and optimization.
- Be taught to leverage CodeLlama for environment friendly code commenting and documentation.
- Discover strategies for changing code between totally different programming languages utilizing CodeLlama.
- Achieve insights into utilizing CodeLlama for superior debugging and error decision.
- Uncover sensible functions and use instances of CodeLlama in real-world growth situations.
This text was revealed as part of the Information Science Blogathon.
What’s CodeLlama?
CodeLlama represents a complicated framework that facilitates the technology and dialogue of code, leveraging the capabilities of Llama 2 (open supply giant language mannequin by Meta). It’s a open-source mannequin that makes use of prompts to generate code .This platform goals to streamline developer workflows, improve effectivity, and simplify the training course of for builders. It helps to generate each code snippets and explanations in pure language associated to programming. CodeLlama provides sturdy assist for a wide selection of up to date programming languages comparable to Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash, amongst others.
The CodeLlama mannequin was proposed in CodeLlama: Open Basis Fashions for Code.
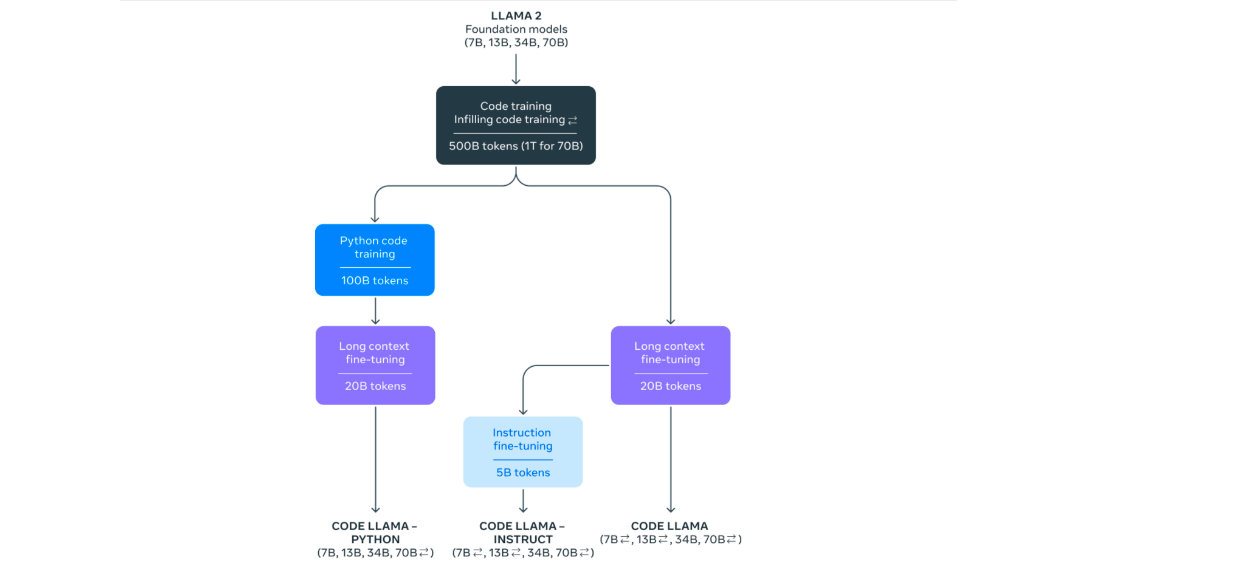
CodeLlama is a household of enormous language fashions for code, primarily based on Llama 2, providing state-of-the-art efficiency, infilling capabilities, assist for big enter contexts, and zero-shot instruction following potential for programming duties. It is available in a number of flavors, together with basis fashions, Python specializations, and instruction-following fashions. All fashions are educated on 16k token sequences and present enhancements on inputs with as much as 100k tokens. CodeLlama reaches state-of-the-art efficiency on a number of code benchmarks, with scores of as much as 53% and 55% on HumanEval and MBPP, respectively.

CodeLlama is a fine-tuned model of Llama 2 (an open- supply mannequin by Meta) and is out there in three fashions:
- CodeLlama: basis code mannequin.
- CodeLlama Python: fine-tuned for Python.
- CodeLlama: Instruct, which is fine-tuned for understanding pure language directions.
Efficiency of CodeLlama
CodeLlama has demonstrated state-of-the-art efficiency on a number of coding benchmarks, together with HumanEval and Principally Primary Python Programming (MBPP). It outperforms different publicly out there fashions in code-specific duties.
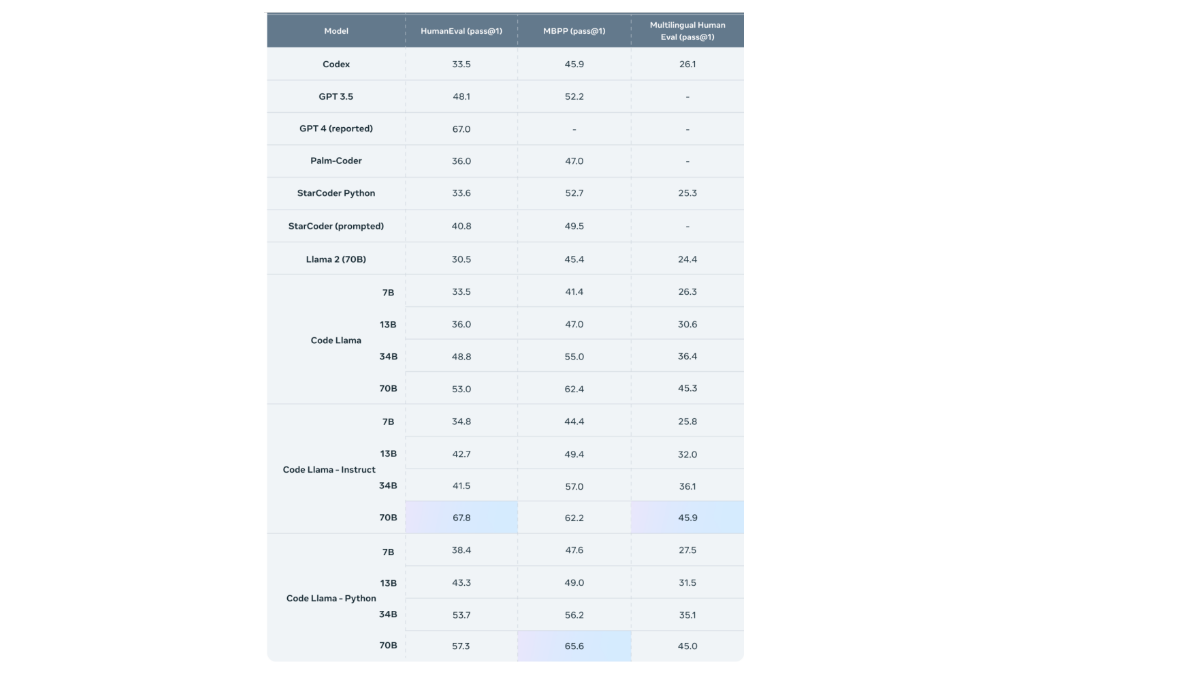
Supply: Meta AI : https://ai.meta.com/weblog/code-llama-large-language-model-coding/
CodeLlama Capabilities
- Code Technology: CodeLlama assists in producing code throughout varied programming languages. Customers can present prompts in pure language to generate the specified code.
- Code Commenting: Commented code elucidates how your program capabilities and the intentions behind it. Feedback themselves don’t affect the execution of your program however are invaluable for people studying your code. CodeLlama facilitates the method of including feedback to code.
- Code Conversion: A developer makes use of a number of programming languages like Python, Pyspark, SQL and many others and would possibly generally wish to convert a code to totally different programming language for e.g Python to Pyspark. CodeLlama can be utilized to transform the code effectively and very quickly.
- Code Optimization: Code optimization is a program transformation strategy that goals to reinforce code by lowering useful resource consumption (i.e., CPU and reminiscence) whereas sustaining excessive efficiency. In code optimization, high-level generic programming constructions are substituted with low-level programming codes. Use CodeLlama to jot down efficient and optimized code.
- Code Debugging: As software program builders, the code we write inevitably doesn’t at all times carry out as anticipated—it could generally behave unexpectedly. When these sudden conditions come up, our subsequent problem is to find out why. Whereas it may be tempting to spend hours scrutinizing our code, a extra environment friendly strategy is to make use of a debugging device. CodeLlama aids builders in debugging their code successfully.
Listed here are examples that illustrate the set up course of, tips on how to present prompts, and generate responses utilizing CodeLlama in varied classes. Code-Llama Instruct, excels in understanding and decoding pure language queries, successfully discerning person expectations and offering related responses to prompts.
Putting in CodeLlama
We have now used “CodeLlama-7b-Instruct-hf” for the producing responses within the examples beneath:
Step1: Import the Required Libraries
!pip set up -q transformers einops speed up langchain bitsandbytesStep2: Login into Hugging Face
Generate a token on hugging face and put that token within the login to hook up with hugging face.
!huggingface-cli loginStep3: Set up Github Repo
Set up the Github repo for putting in it regionally on the system you’ll have to:
!git clone https://huggingface.co/codellama/CodeLlama-7b-Instruct-hfStep4: Load the Mannequin within the Reminiscence
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
import transformers
import torch
mannequin = "/content material/CodeLlama-7b-Instruct-hf"
tokenizer = AutoTokenizer.from_pretrained(mannequin)
pipeline = transformers.pipeline(
"text-generation",
mannequin=mannequin,
torch_dtype=torch.float16,
device_map="auto",
)Understanding Code Technology
CodeLlama can generate code in varied programming languages. Offering an acceptable immediate can yield efficient and environment friendly code.
To make use of CodeLlama, we make the most of a immediate template the place we outline the roles of the system and the person. Modify your query and assign it to the person to acquire the specified end result. The pipeline takes the immediate as enter together with totally different parameters for the massive language mannequin.
system = "Present solutions in python"
person = "create graph utilizing pyneo library"
immediate = f"<s>[INST] <<SYS>>n{system}n<</SYS>>nn{person}[/INST]"
sequences = pipeline(
immediate,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
add_special_tokens=False
)
for seq in sequences:
print(f"End result: {seq['generated_text']}")This question will produce Python code utilizing the PyNeo library to generate a graph. The supplied code consists of directions for importing essential libraries and descriptions varied strategies for graph creation. Moreover, the code consists of explanations and feedback to reinforce person understanding of every element. The size of the output will differ relying on the variety of tokens assigned within the pipeline.

End result:
To create a graph utilizing PyNeo, you need to use the `py2neo.create_graph()` perform.
This perform takes a dictionary of graph properties as an argument,
and returns a `Graph` object.
Here is an instance of how you need to use `py2neo.create_graph()` to create a graph:
```
import py2neo
# Create a graph
graph = py2neo.create_graph({
"identify": "My Graph",
"description": "A graph created utilizing PyNeo"
})
# Add nodes and edges to the graph
node1 = graph.create_node({"identify": "Node 1"})
node2 = graph.create_node({"identify": "Node 2"})
edge = graph.create_edge(node1, node2, {"label": "is aware of"})
# Print the graph
print(graph)
```
This may create a graph with two nodes and one edge, a
nd print the graph to the console.
You can too use the `py2neo.create_graph()` perform to
create a graph from a file. For instance:
```
import py2neo
# Create a graph from a file
graph = py2neo.create_graph("my_graph.json")
# Print the graph
print(graph)
```
This may create a graph from the JSON file `my_graph.json`,
and print the graph to the console.
You can too use the `py2neo.create_graph()`
perform to create a graph from a string. For instance:
```
import py2neo
# Create a graph from a string
graph = py2neo.create_graph("""
{
"identify": "My Graph",
"description": "A graph created utilizing PyNeo"
}
""")
# Print the graph
print(graph)
```
This may create a graph from the JSON string, and
print the graph to the console.
I hope this helps! Let me know if in case you have any questions.This instance is to generate code in pyspark for connecting to azure and querying a folder.
system = "Present solutions in pyspark"
person = "Assist me write pyspark code to attach with Azure adls account abc
and container pqr utilizing a sas token to learn file gross sales parquet from
container folder sales_data and get product sensible gross sales for every month"
immediate = f"<s>[INST] <<SYS>>n{system}n<</SYS>>nn{person}[/INST]"
#inputs = tokenizer(immediate, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
immediate,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
add_special_tokens=False
)
for seq in sequences:
print(f"End result: {seq['generated_text']}")
#import csvThis question will produce the next end result: it imports the mandatory libraries in PySpark, gives code to provoke the session, units up the account and connects to it, after which performs a group-by operation to search out gross sales per product monthly.
End result:
```
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.appName("Azure ADLS").getOrCreate()
# Set the Azure ADLS account and container
account = "abc"
container = "pqr"
# Set the SAS token
sas_token = "your_sas_token"
# Create a DataFrame from the Azure ADLS account and container
df = spark.learn.format("parquet")
.possibility("path", f"abfss://{container}@{account}.dfs.core.home windows.internet/sales_data")
.possibility("sasToken", sas_token)
.load()
# Group the DataFrame by product and month
df_grouped = df.groupBy("product", "month")
# Calculate the overall gross sales for every product and month
df_grouped.agg(F.sum("gross sales").alias("total_sales"))Producing SQL Queries Utilizing Database Schema
Code-Llama is a wonderful device for turning pure language questions into correct SQL statements. It outperforms even the most effective fashions, particularly for duties involving code and text-to-SQL conversions, which is the primary focus of this text. Its user-friendly design makes producing SQL queries simple and seamless. Usually, the question is executed on an current database.
Beneath is the instance the place we give pure language immediate to generate SQL question with database schema.
The database schema may be supplied in beneath format:
table1= """
CREATE TABLE buyer
(
custid VARCHAR(6),
fname VARCHAR(30),
mname VARCHAR(30),
ltname VARCHAR(30),
metropolis VARCHAR(15),
mobileno VARCHAR(10),
occupation VARCHAR(10),
dob DATE,
CONSTRAINT customer_custid_pk PRIMARY KEY(custid)
);
CREATE TABLE department
(
bid VARCHAR(6),
bname VARCHAR(30),
bcity VARCHAR(30),
CONSTRAINT branch_bid_pk PRIMARY KEY(bid)
);
CREATE TABLE account
(
acnumber VARCHAR(6),
custid VARCHAR(6),
bid VARCHAR(6),
opening_balance INT(7),
aod DATE,
atype VARCHAR(10),
astatus VARCHAR(10),
CONSTRAINT account_acnumber_pk PRIMARY KEY(acnumber),
CONSTRAINT account_custid_fk FOREIGN KEY(custid) REFERENCES buyer(custid),
CONSTRAINT account_bid_fk FOREIGN KEY(bid) REFERENCES department(bid)
);
CREATE TABLE trandetails
(
tnumber VARCHAR(6),
acnumber VARCHAR(6),
dot DATE,
medium_of_transaction VARCHAR(20),
transaction_type VARCHAR(20),
transaction_amount INT(7),
CONSTRAINT trandetails_tnumber_pk PRIMARY KEY(tnumber),
CONSTRAINT trandetails_acnumber_fk FOREIGN KEY(acnumber) REFERENCES account(acnumber)
);
CREATE TABLE mortgage
(
custid VARCHAR(6),
bid VARCHAR(6),
loan_amount INT(7),
CONSTRAINT loan_customer_custid_bid_pk PRIMARY KEY(custid,bid),
CONSTRAINT loan_custid_fk FOREIGN KEY(custid) REFERENCES buyer(custid),
CONSTRAINT loan_bid_fk FOREIGN KEY(bid) REFERENCES department(bid)
);
"""The query in pure language may be requested within the beneath format:
query = 'Write a question to show account id, buyer’s firstname, buyer’s lastname for the client’s whose account is Energetic.'
immediate = f"[INST] Write MYSQL question to reply the next query given the database schema.
Please wrap your code reply utilizing ```: Schema: {table1} Query: {query} [/INST]
Right here is the MYSQL question to reply to the query: {query}: ``` "
ans = pipeline(immediate, max_new_tokens=200)
print(ans[0]['generated_text'].cut up('```')[2])This question will end in :

SELECT account.acnumber, buyer.fname, buyer.ltname
FROM account
INNER JOIN buyer ON account.custid = buyer.custid
WHERE account.astatus="Energetic";The codes may be commented utilizing CodeLlama. Beneath are some examples of tips on how to do it:
person = """please full the code with feedback
'''def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return 1'''
"""
immediate = f"<s>[INST] {person.strip()} [/INST]"
sequences = pipeline(
immediate,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
add_special_tokens=False
)
for seq in sequences:
print(f"End result: {seq['generated_text']}")
The question will end in code with feedback (as proven beneath) and explains the code as effectively.
Setting `pad_token_id` to `eos_token_id`:2 for open-end technology.
End result: Right here is the whole code with feedback:
```
def fibonacci(n):
# Base case: If n is 0 or 1, return the worth
if n == 0:
return 0
elif n == 1:
return 1
else:
# Recursive case: If n is bigger than 1,
#return the sum of the earlier two values
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
# Base case: If n is 0 or 1, return the worth
if n == 0:
return 0
elif n == 1:
return 1
else:
# Examine if the worth is already within the memoization desk
if n in memo:
return memo[n]
else:
# If not, calculate the worth and add it to the memoization desk
memo[n] = fibonacci(n-1) + fibonacci(n-2)
return memo[n]
```
The `fibonacci` perform is similar because the one you supplied,
however with feedback added to elucidate what every line does.
The `fibonacci_memo` perform is analogous,
nevertheless it makes use of a memoization desk to retailer the values of `fibonacci`
for earlier inputs. This enables the perform to keep away from recalculating the
similar values a number of occasions, which may make the perform a lot sooner for big inputs.
The `memo` dictionary is initialized to an empty dictionary,
and it's used to retailer the values of `fibonacci` for earlier inputs.
The `if n in memo` assertion checks if the worth is already within the memoization
desk, and whether it is, the perform returns the worth from the desk.
If the worth just isn't within the desk, the perform calculates the worth
and provides it to the desk earlier than returning it.Understanding Code Conversion
Right here , we’re changing binary search code in Python to Java:
system = "Present solutions in Java"
person = """convert the next python code to Java
'''
def binarySearch(array, x, low, excessive):
whereas low <= excessive:
mid = low + (excessive - low)//2
if array[mid] == x:
return mid
elif array[mid] < x:
low = mid + 1
else:
excessive = mid - 1
return -1
array = [3, 4, 5, 6, 7, 8, 9]
x = 4
end result = binarySearch(array, x, 0, len(array)-1)
if end result != -1:
print("Ingredient is current at index " + str(end result))
else:
print("Not discovered")
'''
"""
immediate = f"<s>[INST] <<SYS>>n{system}n<</SYS>>nn{person}[/INST]"
#inputs = tokenizer(immediate, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
immediate,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2000,
add_special_tokens=False
)
for seq in sequences:
print(f"End result: {seq['generated_text']}")This may end in :
End result: Right here is the Java equal of the given Python code:
```
import java.util.Arrays;
public class BinarySearch {
public static int binarySearch(int[] array, int x, int low, int excessive) {
whereas (low <= excessive) {
int mid = low + (excessive - low) / 2;
if (array[mid] == x) {
return mid;
} else if (array[mid] < x) {
low = mid + 1;
} else {
excessive = mid - 1;
}
}
return -1;
}
public static void principal(String[] args) {
int[] array = {3, 4, 5, 6, 7, 8, 9};
int x = 4;
int end result = binarySearch(array, x, 0, array.size - 1);
if (end result!= -1) {
System.out.println("Ingredient is current at index " + end result);
} else {
System.out.println("Not discovered");
}
}
}
```
Observe that in Java, the `Arrays.binarySearch()` methodology can be utilized as an alternative of the customized implementation, which might simplify the code.
Understanding Code Optimization
system = "Present solutions in python"
person = """Please optimize the next code to scale back runtime
'''
input_list = [1, 2, -3]
output_list = []
for x in input_list:
if x >= 0:
output_list.append(1)
else:
output_list.append(0)
'''
"""
immediate = f"<s>[INST] <<SYS>>n{system}n<</SYS>>nn{person}[/INST]"
#inputs = tokenizer(immediate, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
immediate,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2000,
add_special_tokens=False
)
for seq in sequences:
print(f"End result: {seq['generated_text']}")This may use listing comprehension as an alternative of a for loop, offering an optimized model of the earlier code.
End result: Here is a extra environment friendly option to write the identical code in Python:
```
output_list = [1 if x >= 0 else 0 for x in input_list]
```
This makes use of a listing comprehension to create a brand new listing with the identical size as `input_list`, the place every factor is both 1 or 0 relying on whether or not the corresponding factor in `input_list` is bigger than or equal to 0.
This strategy is extra environment friendly as a result of it avoids the necessity to iterate over the enter listing a number of occasions, and it additionally avoids the necessity to create and append parts to the output listing. As a substitute, it creates the whole output listing in a single go, which may be a lot sooner for big enter lists.Understanding Code Debugging
system = "Please repair the code"
person = """I confronted an error once I run my program utilizing python: The error is like this:
ZeroDivisionError: division by zero
My codes appears to be like like beneath
'''
x = 0
y = 0
z = x/y'''
tips on how to keep away from that error in python. My desired output is z = 0 and see the error and repair it
"""
immediate = f"<s>[INST] <<SYS>>n{system}n<</SYS>>nn{person}[/INST]"
#inputs = tokenizer(immediate, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
immediate,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2000,
add_special_tokens=False
)
for seq in sequences:
print(f"End result: {seq['generated_text']}")
This may end result within the following end result. Right here it explains what the error is after which offers the code to rectify it.
End result:The error you might be seeing is as a result of you are attempting to divide by zero,
which isn't allowed in Python.
To repair this error, you possibly can add a test to make it possible for
`y` just isn't equal to zero earlier than dividing.
Right here is an instance of how one can modify your code to keep away from this error:
```
x = 0
y = 0
z = 0
if y!= 0:
z = x/y
else:
print("Error: division by zero")
```
This code will first test if `y` is the same as zero.
Whether it is, it's going to print an error message and set `z` to zero.
If `y` just isn't equal to zero, it's going to divide `x` by `y` and
set `z` to the end result.
Alternatively, you need to use the built-in `attempt` and `besides` blocks to catch the error and deal with it appropriately. Right here is an instance of how one can modify your code to make use of this strategy:
```
x = 0
y = 0
z = 0
attempt:
z = x/y
besides ZeroDivisionError:
print("Error: division by zero")
```
This code will attempt to divide `x` by `y` and set `z` to the end result.
If an error happens, it's going to catch the error and print an error message.
I hope this helps! Let me know if in case you have any questions.Conclusion
Via the discharge of CodeLlama, helps communities to do issues extra effectively. The tailor-made CodeLlama is one cease resolution for all coding wants and builders can profit loads from it.
Additionally, Builders ought to consider their fashions utilizing code-specific analysis benchmarks and carry out security research on code-specific use instances. It ought to be used responsibly.
Key Takeaways
- CodeLlama enhances coding effectivity via superior code technology and pure language processing.
- Additionally helps varied programming languages and duties, together with code technology, commenting, conversion, and debugging.
- It outperforms different open fashions on coding benchmarks, demonstrating state-of-the-art efficiency.
- CodeLlama gives specialised fashions for common coding, Python, and instruction-following.
- It’s open-source, facilitating each analysis and industrial functions with a permissive license.
Incessantly Requested Questions
A. CodeLlama is a complicated framework that leverages the Llama 2 giant language mannequin to generate and talk about code, enhancing developer workflows and effectivity.
A. CodeLlama helps a wide selection of up to date programming languages, together with Python, C++, Java, PHP, Typescript (JavaScript), C#, and Bash.
A. CodeLlama can generate code, add feedback, convert code between languages, optimize code, and help in debugging.
A. CodeLlama demonstrates state-of-the-art efficiency amongst open fashions on a number of coding benchmarks, together with HumanEval and MBPP.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.