
{kind=link}
Introduction
Everyone knows about Synthetic Intelligence, don’t we? It’s revolutionizing the technological panorama worldwide and is predicted to develop enormously throughout the subsequent decade. As AI marks its presence in industries worldwide, it goes with out saying that we’re a world the place life with out AI will appear unimaginable. AI is making machines more and more clever on daily basis, driving improvements that revolutionize how individuals work. Nevertheless, there could be a query in your thoughts that goes one thing like this: What helps AI do all this and get correct outcomes? The reply could be very easy, and that’s information.

Information is the foundational gas for AI. The standard and amount of the information, together with the variety of the information, instantly affect how AI techniques can perform. This data-driven studying allows AI to uncover important patterns, making choices with minimal human intervention. Nevertheless, buying giant volumes of good-quality actual information is commonly restricted as a result of prices and privateness considerations, amongst an limitless checklist of others. That is the place artificial information, and its significance, comes into play.
Studying Targets
- Perceive the significance of artificial information
- Study concerning the function of Generative AI in information creation
- Discover sensible purposes and their implementation in your tasks
- Know concerning the moral implications associated to the utilization and significance of artificial information in AI techniques
This text was printed as part of the Information Science Blogathon.
The Significance of Excessive-High quality Artificial Information
Artificial information is nothing however artificially generated information. Particularly, it mimics real-world information’s statistical properties with out having identifiers distinguishing it from actual information.
Fairly cool, proper?
Artificial information isn’t merely a workaround for privateness considerations. Quite, it’s a cornerstone for accountable AI. This type of information technology addresses a number of challenges related to utilizing actual information. It’s useful when the information obtainable is much less or biased in the direction of a selected class. Moreover, it can be utilized in purposes the place privateness is essential. It’s because actual information is usually confidential and may not be obtainable to be used. Therefore, including helps remedy these points and enhance the mannequin’s accuracy.
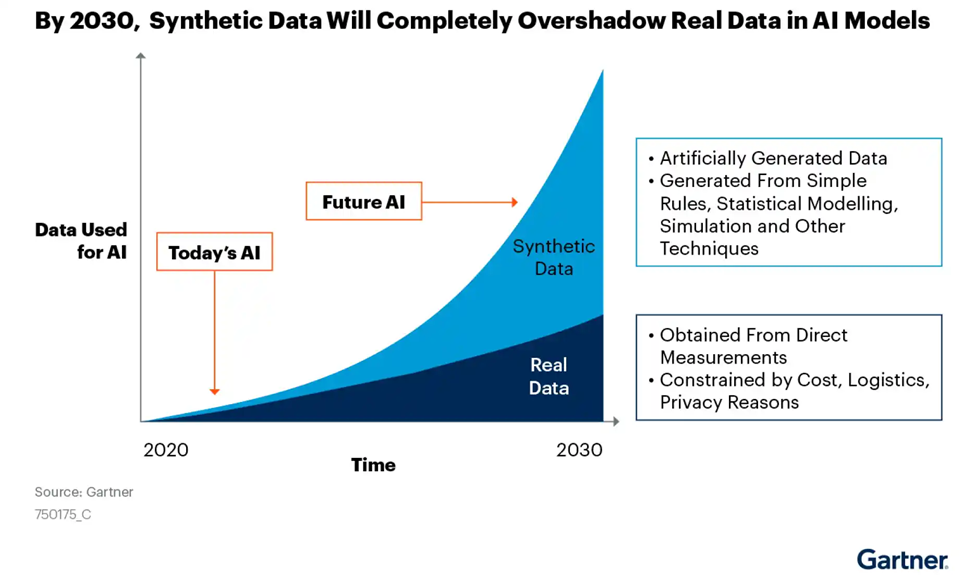
In keeping with an estimation made in a Gartner report, artificial information is predicted to win the race in opposition to actual information relating to utilization in AI fashions by 2030. This showcases its energy and function in enhancing AI techniques.
Position of Generative AI in Artificial Information Creation
Generative AI fashions lie on the coronary heart of artificial information creation. What these basically do is straightforward – they study the underlying patterns inside unique datasets after which attempt to replicate them. By using algorithms like Generative Adversarial Networks (GANs) or Variational Autoencoders, Generative AI can produce extremely correct and various datasets required for coaching many AI techniques.
Within the panorama of artificial information technology, a number of progressive instruments stand out, every designed to cater to particular wants in information science. YData’s ydata-synthetic is a complete toolkit that makes use of superior Generative AI fashions to create high-quality artificial datasets, additionally providing information profiling options to assist perceive the construction of this information.
One other notable framework is DoppelGANger, which makes use of generative adversarial networks (GANs) to effectively generate artificial time sequence and attribute information. Moreover, Twinify gives a novel strategy to creating privacy-preserving artificial twins of delicate datasets, making it a priceless software for sustaining information privateness. These instruments present versatile choices for information scientists trying to improve dataset privateness, increase information volumes, or enhance mannequin accuracy with out compromising delicate data.
Creating Excessive-High quality Artificial Information
Creating good high quality artificial information entails a number of key steps that assist make sure that the generated information is lifelike and likewise preserves the statistical properties of the unique information.
The method begins with defining clear aims for this information, corresponding to information privateness, augmenting actual datasets or testing machine studying fashions. Subsequent, it’s essential to gather and analyze real-world information to know its underlying patterns, distributions, and correlations.
As an example, take into account the next instance datasets:
- UCI Machine Studying Repository: A various assortment of datasets appropriate for understanding information distributions and producing artificial counterparts. UCI Machine Studying Repository
- Kaggle Datasets: Gives a variety of datasets throughout numerous domains, helpful for analyzing and synthesizing information. Kaggle Datasets
- Artificial Information Vault (SDV): Supplies instruments and datasets for producing artificial information primarily based on real-world information utilizing statistical fashions. SDV Documentation
These datasets might be analyzed to establish key statistical properties. Which may then be used to generate artificial information utilizing instruments like YData Artificial, Twinify and DoppelGANger. The generated artificial information might be validated in opposition to the unique information by way of statistical assessments and visualizations to make sure it retains the required properties and correlations. Due to this fact, making it appropriate for numerous purposes corresponding to machine studying mannequin coaching and testing, privacy-preserving information evaluation, and extra.
Potential Software Situations
Allow us to now discover potential software scenarions.
Information Augmentation
That is the highest situation the place artificial information is used—when scarce or imbalanced information is current. Artificial information augments present datasets, thus guaranteeing that AI fashions are skilled on bigger information units. This software is important in fields like healthcare, the place various information units can result in extra sturdy diagnostic instruments.
Beneath is a code snippet that augments the Iris dataset with artificial information generated utilizing YData’s synthesizer, guaranteeing extra balanced information for coaching AI fashions. That is achieved utilizing a synthesizer which is fitted on the actual information (the Iris dataset) and learns the underlying patterns and distributions of the information. Utilizing the fitted synthesizer, artificial information is generated which is then concatenated with the actual information, thus augmenting the dataset.
import pandas as pd
from ydata_synthetic.synthesizers.common import RegularSynthesizer
url = "https://uncooked.githubusercontent.com/mwaskom/seaborn-data/grasp/iris.csv"
real_data = pd.read_csv(url)
synthesizer = RegularSynthesizer()
synthesizer.match(real_data)
synthetic_data = synthesizer.pattern(n_samples=100)
augmented_data = pd.concat([real_data, synthetic_data])
print(augmented_data.head())Output:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaBias Mitigation
Typically, the obtainable information is biased in the direction of a selected class; it has extra samples of sophistication A than class B. Therefore, the mannequin would possibly predict class A far more than class B. To counter this, we are able to deliberately alter the present information distribution, thus selling fairness within the outputs given by AI. That is particularly essential in sectors like lending and hiring, the place biased algorithms can considerably have an effect on individuals’s lives.
The code under generates artificial information in case you have an underrepresented class in your dataset (on this case, the Versicolor class within the iris dataset) to steadiness the category distribution. The unique dataset has a bias the place the Versicolor class is underrepresented in comparison with the opposite courses (Setosa and Virginica). Utilizing the RegularSynthesizer from the YData Artificial library, artificial information is generated particularly for the Versicolor class which is then added to the unique biased dataset. Thus rising the variety of situations within the Versicolor class and making a extra balanced distribution.
import pandas as pd
from ydata_synthetic.synthesizers.common import RegularSynthesizer
url = "https://uncooked.githubusercontent.com/mwaskom/seaborn-data/grasp/iris.csv"
biased_data = pd.read_csv(url)
biased_data = biased_data[biased_data['species'] != 'versicolor']
synthesizer = RegularSynthesizer()
synthesizer.match(biased_data)
# Producing artificial information for the minority class (versicolor)
synthetic_minority_data = synthesizer.pattern(n_samples=50)
synthetic_minority_data['species'] = 'versicolor'
balanced_data = pd.concat([biased_data, synthetic_minority_data])
print("Biased Information Class Distribution:")
print(biased_data['species'].value_counts())
print("nBalanced Information Class Distribution:")
print(balanced_data['species'].value_counts())Output:
Biased Information Class Distribution:
setosa 50
virginica 50
versicolor 0
Identify: species, dtype: int64
Balanced Information Class Distribution:
setosa 50
virginica 50
versicolor 50
Identify: species, dtype: int64Privateness-Preserving Information Sharing
It allows the sharing of lifelike (not actual, however nearly!) datasets throughout organizations with out the chance of exposing delicate data which may create confidentiality points. That is essential for industries corresponding to finance and telecommunications, the place information sharing is critical for innovation, however privateness and confidentiality have to be maintained.
This code creates artificial twins of delicate datasets utilizing Twinify, which permits information sharing with out compromising privateness.
import pandas as pd
from twinify import Twinify
url = "https://uncooked.githubusercontent.com/mwaskom/seaborn-data/grasp/iris.csv"
sensitive_data = pd.read_csv(url)
twinify_model = Twinify()
twinify_model.match(sensitive_data)
synthetic_twins = twinify_model.pattern(n_samples=len(sensitive_data))
print(synthetic_twins.head())Output:
sepal_length sepal_width petal_length petal_width species
0 5.122549 3.527435 1.464094 0.251932 setosa
1 4.846851 3.091847 1.403198 0.219201 setosa
2 4.675999 3.250960 1.324110 0.194545 setosa
3 4.675083 3.132406 1.535735 0.201018 setosa
4 5.014248 3.591084 1.461466 0.253920 setosaThreat Evaluation and Testing
Threat evaluation and testing are important purposes of artificial information, enabling organizations to guage and improve their techniques’ robustness beneath hypothetical situations not represented in actual information. In cybersecurity, artificial information permits for the simulation of subtle assault situations, corresponding to zero-day exploits and superior persistent threats, serving to establish vulnerabilities and strengthen defenses. Equally, in monetary providers, artificial information facilitates stress testing and situation evaluation by modeling excessive market circumstances. This permits establishments to evaluate the resilience of their portfolios and enhance threat administration methods.
Past these fields, artificial information can be priceless in healthcare for testing predictive fashions beneath uncommon scientific situations, in manufacturing for simulating tools failures and provide chain disruptions, and in insurance coverage for modeling the affect of pure disasters and main accidents. Organizations can improve their system’s resilience by making ready for uncommon however catastrophic occasions by way of artificial information simulation. This ensures that they’ve the required tools to deal with sudden conditions and thus successfully mitigate potential dangers.
Conclusion
As AI reshapes our world, information is essential in addressing privateness, price, and accessibility points, guaranteeing moral and efficient fashions. Generative AI methods allow the creation of high-quality datasets that mirror real-world complexities, enhancing mannequin accuracy and reliability. These datasets foster accountable AI improvement by mitigating biases, facilitating privacy-preserving information sharing, and enabling complete threat assessments. Leveraging instruments like ydata-synthetic and DoppelGANger can be important in realizing AI’s full potential and driving innovation. These instruments uphold moral requirements whereas enabling developments in AI improvement. On this article we explored the significance of artificial information.
Key Takeaways
- Significance of Artificial Information is that it gives an answer for using lifelike but fully personal datasets, adhering to stringent information safety legal guidelines. Additionally guaranteeing that delicate data isn’t in danger.
- By producing artificial information that displays the variability and complexity of actual information, organizations can enhance the accuracy Additionally reliability of their AI fashions with out the constraints of information shortage.
- Artificial information reduces the necessity for costly information assortment processes and the storage of huge quantities of actual information. It makes for a cheap various for coaching and testing AI fashions.
- It gives a proactive strategy to creating balanced datasets that forestall the perpetuation of biases, selling extra honest and equitable AI purposes.
Every of those factors underscores the transformative potential of artificial information in paving the way in which for accountable, environment friendly, and moral AI improvement. As we advance, the function of instruments like ydata-synthetic or DoppelGANger can be pivotal in shaping this future, guaranteeing that AI continues to evolve as a software for good, guided by the rules of accountable AI.
Steadily Requested Questions
A. Artificial information is artificially generated information that mimics the statistical properties of real-world information with out containing any identifiable data.
A. Artificial information addresses points of information privateness, price, and accessibility, enabling AI fashions to coach on giant and various datasets whereas mitigating privateness considerations.
A. Generative AI fashions, corresponding to GANs (Generative Adversarial Networks) and Variational Autoencoders, study patterns from actual information and replicate these patterns to generate this type of information.
A. Artificial information can improve the standard and equity of AI fashions by augmenting information, mitigating bias, and preserving privateness in information sharing.
The media proven on this article are usually not owned by Analytics Vidhya and is used on the Creator’s discretion.