
{kind=link}
Introduction
On this article, we’re going to discover a brand new device, EmbedAnything, and see the way it works and what you should use it for. EmbedAnything is a high-performance library that permits you to create picture and textual content embeddings immediately from recordsdata utilizing native embedding fashions in addition to cloud-based embedding fashions. We will even see an instance of this in motion with a situation the place we wish to group trend photographs collectively based mostly on the attire that they present.

What Are Embeddings?
If you’re working within the AI area or labored with massive language fashions, you’d have positively come throughout the time period embeddings. In easy phrases, embeddings are a compressed illustration of a sentence or a phrase. It’s principally a vector of floating level numbers. It may very well be of any measurement starting from 100 to as huge as 5000.
How Are Embeddings Made?
Embedding fashions have developed quite a bit through the years. The earliest fashions had been based mostly on one scorching encoding or phrase occurrences. Nonetheless, with new technological developments and extra knowledge availability, embedding fashions have turn into extra highly effective.
Pre-Transformer Period
The only method to characterize a phrase as an embedding is utilizing a one-hot encoding with the full vocabulary measurement of the textual content corpus. Nonetheless, that is extraordinarily inefficient because the illustration may be very sparse, and the scale of the embedding is as huge because the vocabulary measurement, which could be as much as thousands and thousands.
The following method is utilizing an NGram mannequin, which makes use of a easy, absolutely related neural community. There are two strategies Skip-gram and Steady Bag of Phrases (CBOW). These strategies are very environment friendly and fall underneath the Word2Vec umbrella. CBOW predicts the goal phrase from its context, whereas Skip-gram tries to foretell the context phrases from the goal phrase.
One other method is GloVe (International Vectors for Phrase Illustration). GloVe focuses on leveraging the statistical data of phrase co-occurrence throughout a big corpus.
Submit Transformer Period
Bidirectional Encoder Transformer
One of many earliest methods to construct contextual embeddings utilizing transformers was BERT. What’s BERT, when you marvel? It’s a self-supervised means of predicting masked phrases. It means if we [MASK] one phrase in a sentence, it simply tries to foretell what that phrase may very well be, and thus, the data strikes each from the left to proper and proper to left of the masked phrase.
Sentence Embeddings
What we’ve got seen thus far are methods to create phrase embeddings. However in lots of circumstances, we wish to seize a illustration of a sentence as an alternative of simply the phrases within the sentence. There are a number of methods to create sentence embeddings from phrase embeddings. One of the prevalent strategies is utilizing pre-trained fashions like SBERT (Sentence BERT). These are educated by making a dataset of comparable pairs of sentences and performing contrastive studying with similarity scores.
There are a number of strategies for utilizing sentence embedding fashions. The best is to make use of cloud-based embedding fashions like OpenAI, Jina, or Cohere. There are a number of native fashions as properly on Hugging Face that can be utilized like AllMiniLM6.
Multimodal embeddings
Multimodal embeddings are vector representations that encode data from a number of varieties of knowledge into a standard vector area. This enables fashions to grasp and correlate data throughout completely different modalities. One of the used multimodal embedding fashions is CLIP, which embeds textual content and pictures in a shared embedding area.
The place Are These Embeddings Used?
Embeddings have numerous purposes throughout numerous industries. Listed here are a number of the commonest use circumstances:
Data Retrieval
- Search Engines: Embeddings are used to enhance search relevance by understanding the semantic which means of queries and paperwork.
- Retrieval Augmented Technology (RAG): Embeddings are used to retrieve data for Giant Language fashions. That is known as LLM Grounding.
- Doc Clustering and Matter Modeling: Embeddings assist in grouping related paperwork collectively and discovering latent subjects in a corpus
Multimodal Purposes
- Picture Captioning: Combining textual content and picture embeddings to generate descriptive captions for photographs.
- Visible Query Answering: Utilizing each visible and textual embeddings to reply questions on photographs.
- Multimodal Sentiment Evaluation: Combining textual content, picture, and audio embeddings to research sentiment from multimedia content material.
How Does EmbedAnything Assist?
AI fashions will not be straightforward to run. They’re computationally very intensive, not straightforward to deploy, and exhausting to observe. EmbedAnything allows you to run embedding fashions effectively and makes them deployment-friendly. Listed here are a number of the advantages of utilizing EmbedAnything enhances the efficiency of AI fashions and may deal with multimodality. When a listing is handed for embedding to EmbedAnything, the file extension is checked to see whether it is textual content or picture and an acceptable embedding mannequin is used to generate the embeddings.
How Does EmbedAnything Work?
EmbedAnything is constructed with Rust. This makes it sooner and offers kind security and a significantly better growth expertise. However why is velocity so essential on this course of?
Creating embeddings from recordsdata entails two steps that demand important computational energy:
- Extracting Textual content from Information, Particularly PDFs: Textual content can exist in numerous codecs reminiscent of markdown, PDFs, and Phrase paperwork. Nonetheless, extracting textual content from PDFs could be difficult and sometimes causes slowdowns. It’s particularly troublesome to extract textual content in manageable batches as embedding fashions have a context restrict. Breaking the textual content into paragraphs containing targeted data may also help.
- Inferencing on the Transformer Embedding Mannequin: The transformer mannequin is often on the core of the embedding course of, however it’s recognized for being computationally costly. To handle this, EmbedAnything makes use of the Candle Framework by Hugging Face, a machine-learning framework constructed completely in Rust for optimized efficiency.
The Advantage of Rust for Velocity
By utilizing Rust for its core functionalities, EmbedAnything gives important velocity benefits:
- Rust is Compiled: In contrast to Python, Rust compiles on to machine code, leading to sooner execution.
- Reminiscence Administration: Rust enforces reminiscence administration concurrently, stopping reminiscence leaks and crashes that may plague different languages.
- Rust achieves true multithreading.
What Does Candle Convey to the Desk?
Working language fashions or embedding fashions regionally could be troublesome, particularly while you wish to deploy a product that makes use of these fashions. Should you use the transformers library from Hugging Face in Python, you’ll rely on PyTorch for tensor operations. This, in flip, has a dependency on Libtorch, which implies that you’ll want to incorporate the whole Libtorch library together with your product. Additionally, Candle permits inferences on CUDA-enabled GPUs proper out of the field. We’ll quickly submit on how we use Candle to extend the efficiency and reduce the reminiscence utilization of EmbedAnything.
Find out how to Use EmbedAnything
Let’s have a look at an instance of how handy it’s to make use of EmbedAnything. We’ll have a look at the zero-shot classification of trend photographs. Let’s say we’ve got some photographs like this:
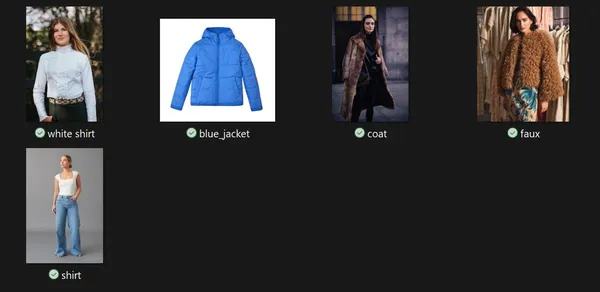
We wish the mannequin to categorize them as [‘Shirt’, ‘Coat’, ‘Jeans’, ‘Skirt’, ‘Hat’, ‘Shoes’, ‘Bag’].
To get began, you’ll want to put in the embed-anything package deal:
pip set up embed-anythingSubsequent, import the required dependencies:
import embed_anything
import numpy as np
from PIL import Picture
import matplotlib.pyplot as pltWith simply two traces of code, you may acquire the embeddings for all the photographs in a listing utilizing CLIP embeddings:
knowledge = embed_anything.embed_directory("photographs", embeder= "Clip") # embed "photographs" folder
embeddings = np.array([data.embedding for data in data])#import csvOutline the labels that you really want the mannequin to foretell and embed the labels:
labels = ['Shirt', 'Coat', 'Jeans', 'Skirt', 'Hat', 'Shoes', 'Bag']
label_embeddings = embed_anything.embed_query(labels, embeder= "Clip")
label_embeddings = np.array([label.embedding for label in label_embeddings])
fig, ax = plt.subplots(1, 5, figsize=(20, 5))
for i in vary(len(knowledge)):
similarities = np.dot(label_embeddings, knowledge[i].embedding)
max_index = np.argmax(similarities)
image_path = knowledge[i].textual content
# Open and plot the picture
img = Picture.open(image_path)
ax[i].imshow(img)
ax[i].axis('off')
ax[i].set_title(labels[max_index])That’s it. Now, we simply test the similarities between the picture embeddings and the label embeddings and assign the label to the picture with the best similarity. We will additionally visualize the output.

Conclusion
With EmbedAnything, including extra photographs to the folder or extra labels to the record is easy. This technique scales very properly and doesn’t require any coaching, making it a strong device for zero-shot classification duties
On this article, we realized about embedding fashions and how you can use EmbedAnything to boost your embedding pipeline, dashing up the technology course of with only a few traces of code.
You’ll be able to take a look at EmbedAnything, right here.
We’re actively on the lookout for contributors to construct and lengthen the pipeline to make embeddings simpler and extra highly effective.