
{kind=link}

In recent times, zero-shot object detection has change into a cornerstone of developments in pc imaginative and prescient. Creating versatile and environment friendly detectors has been a big deal with constructing real-world purposes. The introduction of Grounding DINO 1.5 by IDEA Analysis marks a big leap ahead on this discipline, notably in open-set object detection.
We’ll run the demo utilizing Paperspace GPUs, a platform identified for providing high-performance computing sources for numerous purposes. These GPUs are designed to fulfill the wants of machine studying, deep studying, and information evaluation and supply scalable and versatile computing energy while not having bodily {hardware} investments.
Paperspace provides a variety of GPU choices to go well with totally different efficiency necessities and budgets, permitting customers to speed up their computational workflows effectively. Moreover, the platform integrates with common instruments and frameworks, making it simpler for builders and researchers to deploy, handle, and scale their tasks.
What’s Grounding DINO?
Grounding DINO, an open-set detector primarily based on DINO, not solely achieved state-of-the-art object detection efficiency but in addition enabled the combination of multi-level textual content info via grounded pre-training. Grounding DINO provides a number of benefits over GLIP or Grounded Language-Picture Pre-training or GLIP. Firstly, its Transformer-based structure, much like language fashions, facilitates processing each picture and language information.
Grounding DINO Framework
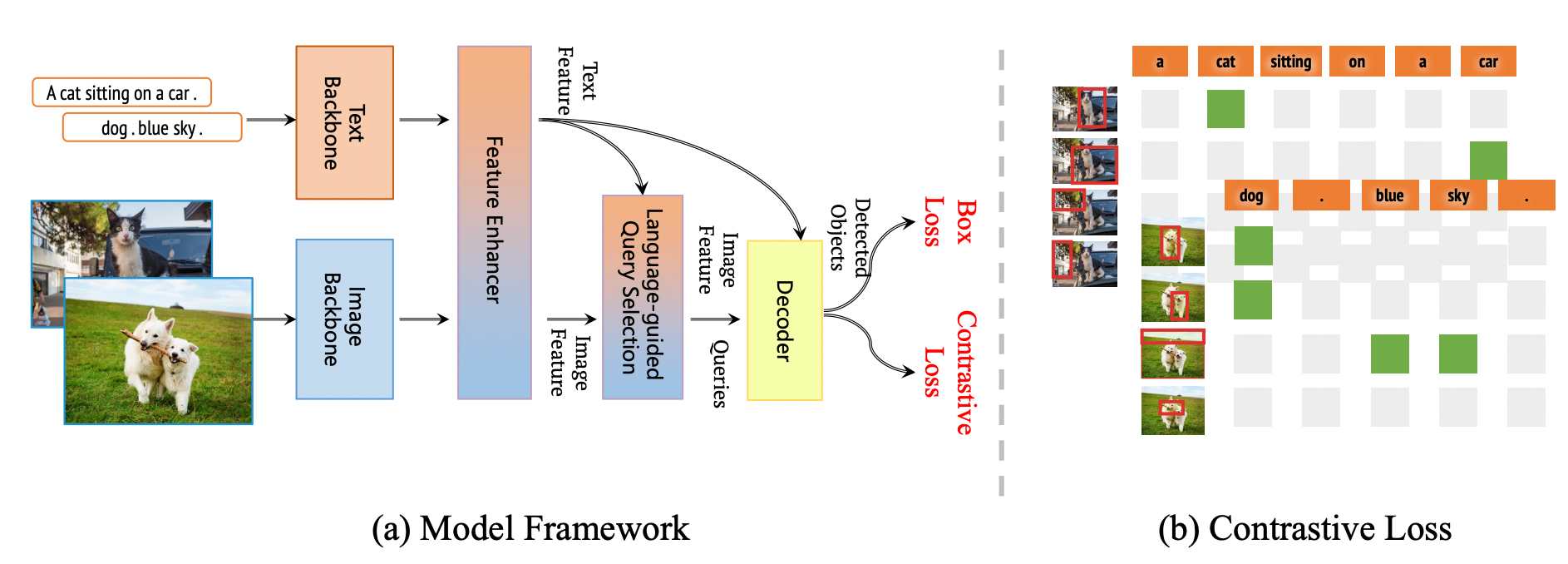
The framework proven within the above picture is the general framework of the Grounding DINO 1.5 collection. This framework retains the dual-encoder-single-decoder construction of Grounding DINO. Additional, this framework extends it to Grounding DINO 1.5 for each the Professional and Edge fashions.
Grounding DINO combines ideas from DINO and GLIP. DINO, a transformer-based technique, excels in object detection with end-to-end optimization, eradicating the necessity for handcrafted modules like Non-Most Suppression or NMS. Conversely, GLIP focuses on phrase grounding, linking phrases or phrases in textual content to visible parts in photos or movies.
Grounding DINO’s structure consists of a picture spine, a textual content spine, a characteristic enhancer for image-text fusion, a language-guided question choice module, and a cross-modality decoder for refining object bins. Initially, it extracts picture and textual content options, fuses them, selects queries from picture options, and makes use of these queries in a decoder to foretell object bins and corresponding phrases.
Convey this mission to life
What’s new in Grounding DINO 1.5?
Grounding DINO 1.5 builds upon the muse laid by its predecessor, Grounding DINO, which redefined object detection by incorporating linguistic info and framing the duty as phrase grounding. This modern method leverages large-scale pre-training on numerous datasets and self-training on pseudo-labeled information from an intensive pool of image-text pairs. The result’s a mannequin that excels in open-world eventualities on account of its sturdy structure and semantic richness.
Grounding DINO 1.5 extends these capabilities even additional, introducing two specialised fashions: Grounding DINO 1.5 Professional and Grounding DINO 1.5 Edge. The Professional mannequin enhances detection efficiency by considerably increasing the mannequin’s capability and dataset measurement, incorporating superior architectures just like the ViT-L, and producing over 20 million annotated photos. In distinction, the Edge mannequin is optimized for edge units, emphasizing computational effectivity whereas sustaining excessive detection high quality via high-level picture options.
Experimental findings underscore the effectiveness of Grounding DINO 1.5, with the Professional mannequin setting new efficiency requirements and the Edge mannequin showcasing spectacular pace and accuracy, rendering it extremely appropriate for edge computing purposes. This text delves into the developments introduced by Grounding DINO 1.5, exploring its methodologies, impression, and potential future instructions within the dynamic panorama of open-set object detection, thereby highlighting its sensible purposes in real-world eventualities.
Grounding DINO 1.5 is pre-trained on Grounding-20M, a dataset of over 20 million grounding photos from public sources. Throughout the coaching course of, high-quality annotations with well-developed annotation pipelines and post-processing guidelines are ensured.
Efficiency Evaluation
The determine under exhibits the mannequin’s means to acknowledge objects in datasets like COCO and LVIS, which include many classes. It signifies that Grounding DINO 1.5 Professional considerably outperforms earlier variations. In comparison with a selected earlier mannequin, Grounding DINO 1.5 Professional exhibits a outstanding enchancment.
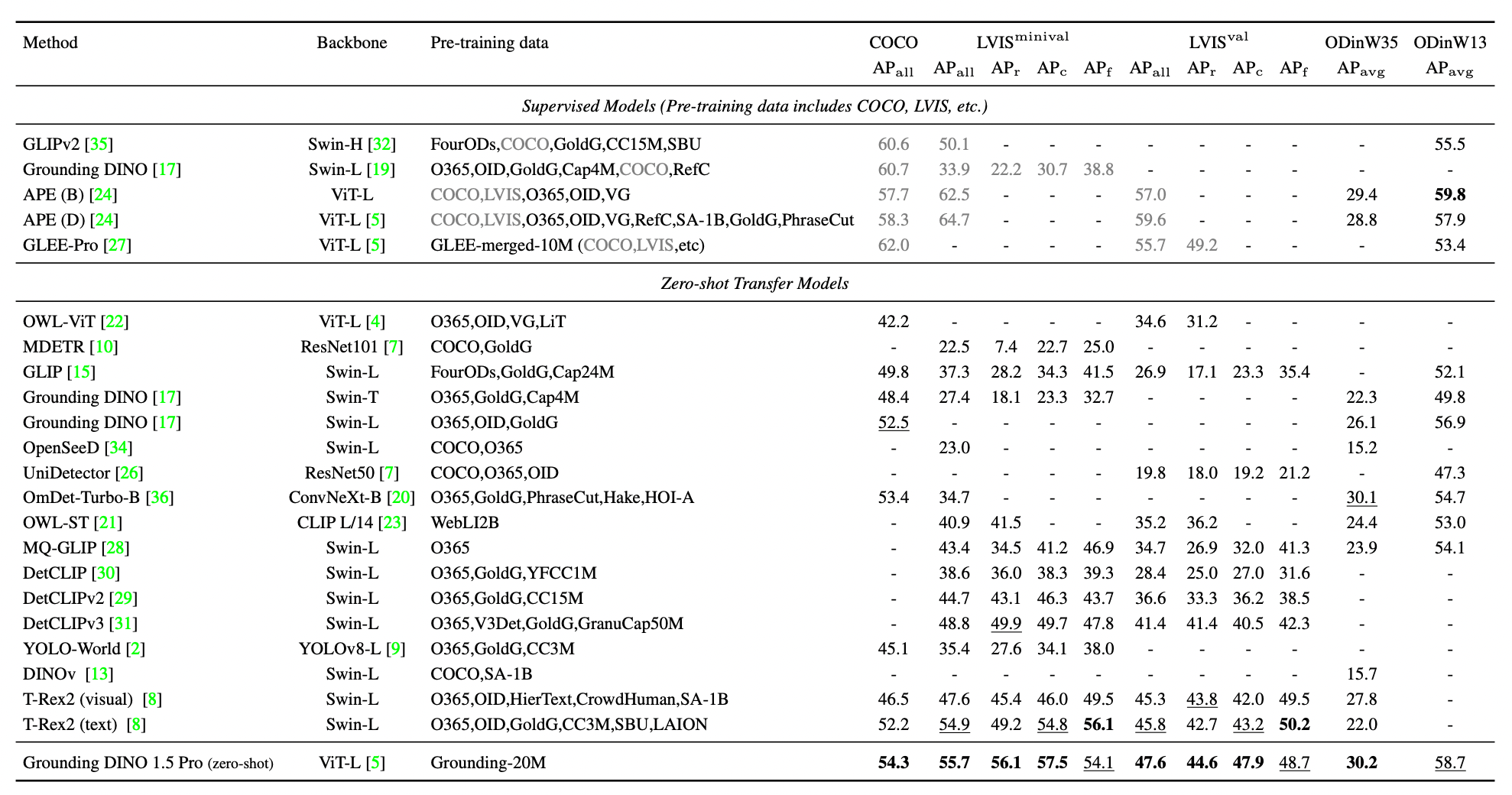
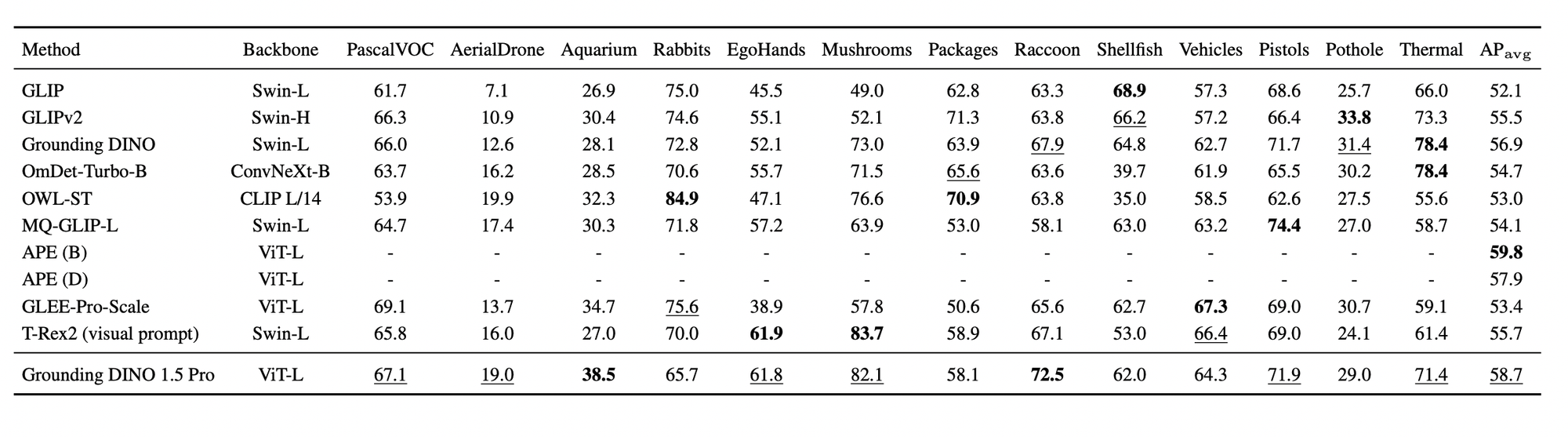
The mannequin was examined in numerous real-world eventualities utilizing the ODinW (Object Detection within the Wild) benchmark, which incorporates 35 datasets protecting totally different purposes. Grounding DINO 1.5 Professional achieved considerably improved efficiency over the earlier model of Grounding DINO.
Zero-shot outcomes for Grounding DINO 1.5 Edge on COCO and LVIS are measured in frames per second (FPS) utilizing an A100 GPU, reported in PyTorch pace / TensorRT FP32 pace. FPS on NVIDIA Orin NX can be offered. Grounding DINO 1.5 Edge achieves outstanding efficiency and in addition surpasses all different state-of-the-art algorithms (OmDet-Turbo-T 30.3 AP, YOLO-Worldv2-L 32.9 AP, YOLO-Worldv2-M 30.0 AP, YOLO-Worldv2-S 22.7 AP).
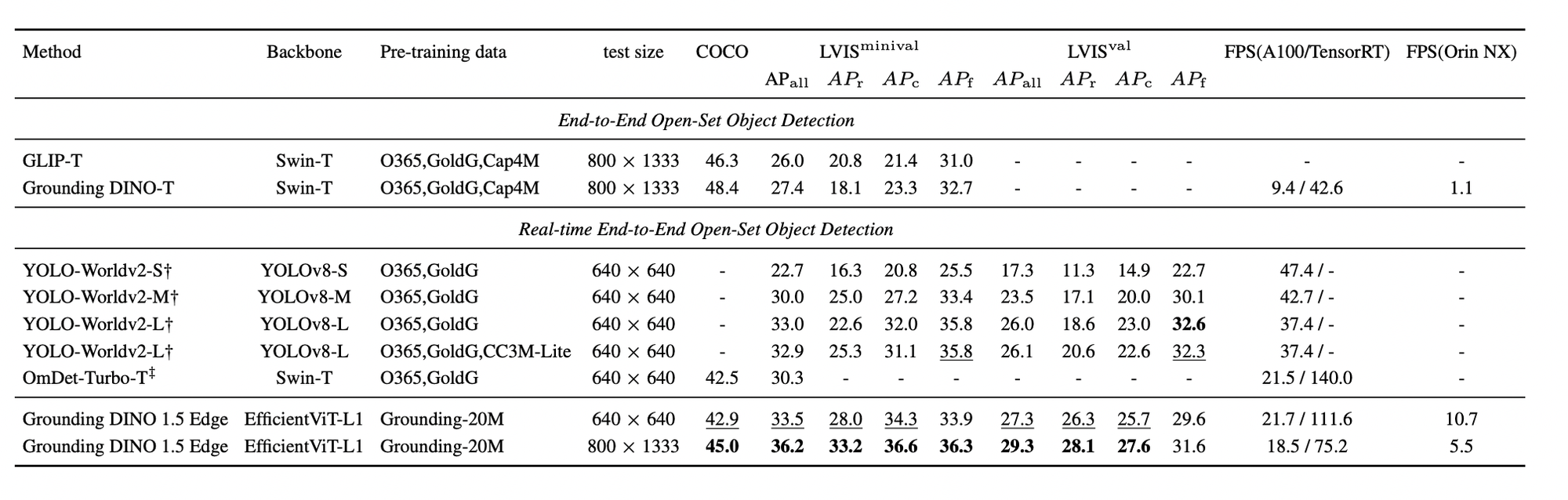
Grounding DINO 1.5 Professional and Grounding DINO 1.5 Edge
Grounding DINO 1.5 Professional
Grounding DINO 1.5 Professional builds on the core structure of Grounding DINO however enhances the mannequin structure with a bigger Imaginative and prescient Transformer (ViT-L) spine. The ViT-L mannequin is thought for its distinctive efficiency on numerous duties, and the transformer-based design aids in optimizing coaching and inference.
One of many key methodologies Grounding DINO 1.5 Professional adopts is a deep early fusion technique for characteristic extraction. Which means that language and picture options are mixed early on utilizing cross-attention mechanisms throughout the characteristic extraction course of earlier than transferring to the decoding part. This early integration permits for a extra thorough fusion of data from each modalities.
Of their analysis, the group in contrast early fusion with later fusion methods. In early fusion, language, and picture options are built-in early within the course of, resulting in larger detection recall and extra correct bounding field predictions. Nevertheless, this method can typically trigger the mannequin to hallucinate, which means it predicts objects that are not current within the photos.
Alternatively, late fusion retains language and picture options separate till the loss calculation part, the place they’re built-in. This method is usually extra sturdy towards hallucinations however tends to lead to decrease detection recall as a result of aligning imaginative and prescient and language options turns into tougher when they’re solely mixed on the finish.
To maximise the advantages of early fusion whereas minimizing its drawbacks, Grounding DINO 1.5 Professional retains the early fusion design however incorporates a extra complete coaching sampling technique. This technique will increase the proportion of destructive samples—photos with out the objects of curiosity—throughout coaching. By doing so, the mannequin learns to tell apart between related and irrelevant info higher, thereby decreasing hallucinations whereas sustaining excessive detection recall and accuracy.
In abstract, Grounding DINO 1.5 Professional enhances its prediction capabilities and robustness by combining early fusion with an improved coaching method that balances the strengths and weaknesses of early fusion structure.
Grounding DINO 1.5 Edge
Grounding DINO is a robust mannequin for detecting objects in photos, but it surely requires a variety of computing energy. This makes it difficult to make use of on small units with restricted sources, like these in vehicles, medical tools, or smartphones. These units must course of photos shortly and effectively in actual time.
Deploying Grounding DINO on edge units is very fascinating for a lot of purposes, reminiscent of autonomous driving, medical picture processing, and computational pictures.
Nevertheless, open-set detection fashions usually require important computational sources, which edge units lack. The unique Grounding DINO mannequin makes use of multi-scale picture options and a computationally intensive characteristic enhancer. Whereas this improves the coaching pace and efficiency, it’s impractical for real-time purposes on edge units.
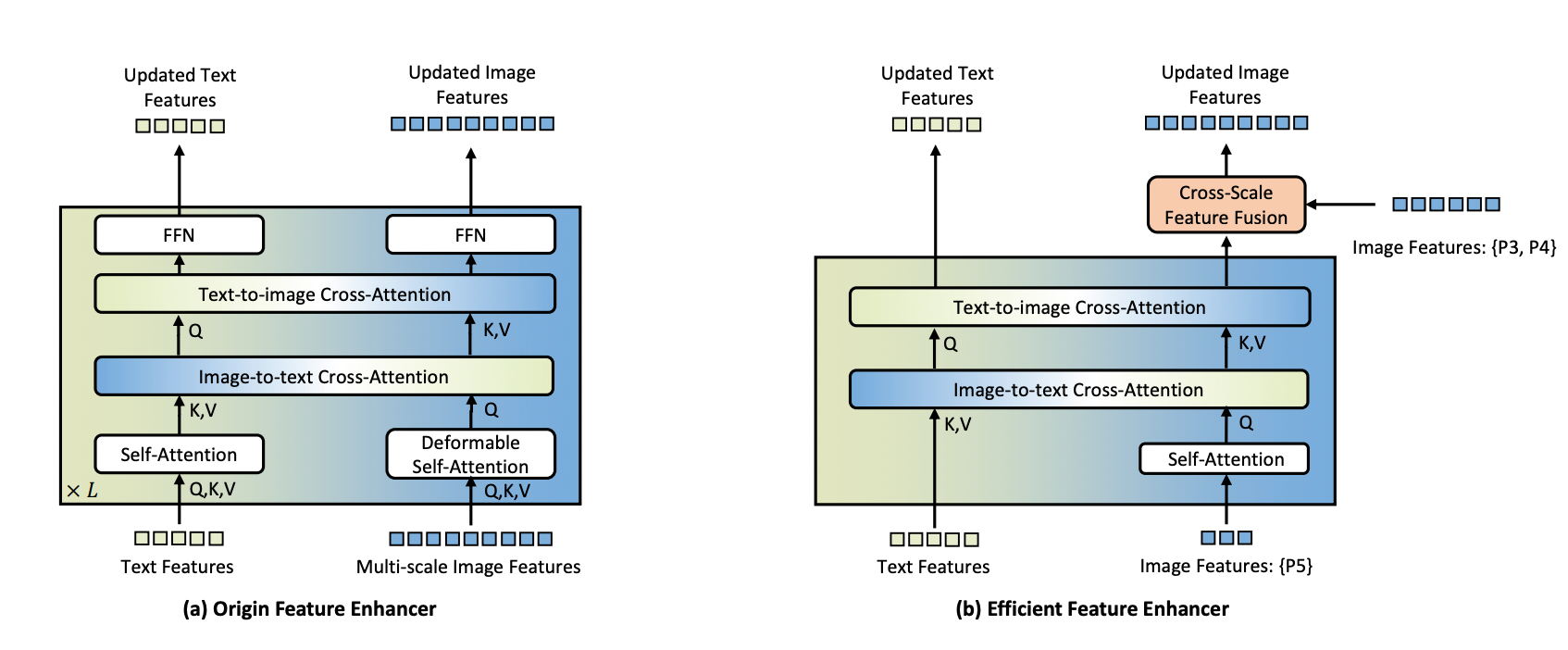
To handle this problem, the researchers suggest an environment friendly characteristic enhancer for edge units. Their method focuses on utilizing solely high-level picture options (P5 stage) for cross-modality fusion, as lower-level options lack semantic info and enhance computational prices. This technique considerably reduces the variety of tokens processed, slicing the computational load.
For higher integration on edge units, the mannequin replaces deformable self-attention with vanilla self-attention and introduces a cross-scale characteristic fusion module to combine lower-level picture options (P3 and P4 ranges). This design balances the necessity for characteristic enhancement with the need for computational effectivity.
In Grounding DINO 1.5 Edge, the unique characteristic enhancer is changed with this new environment friendly enhancer, and EfficientViT-L1 is used because the picture spine for fast multi-scale characteristic extraction. When deployed on the NVIDIA Orin NX platform, this optimized mannequin achieves an inference pace of over 10 FPS with an enter measurement of 640 × 640. This makes it appropriate for real-time purposes on edge units, balancing efficiency and effectivity.

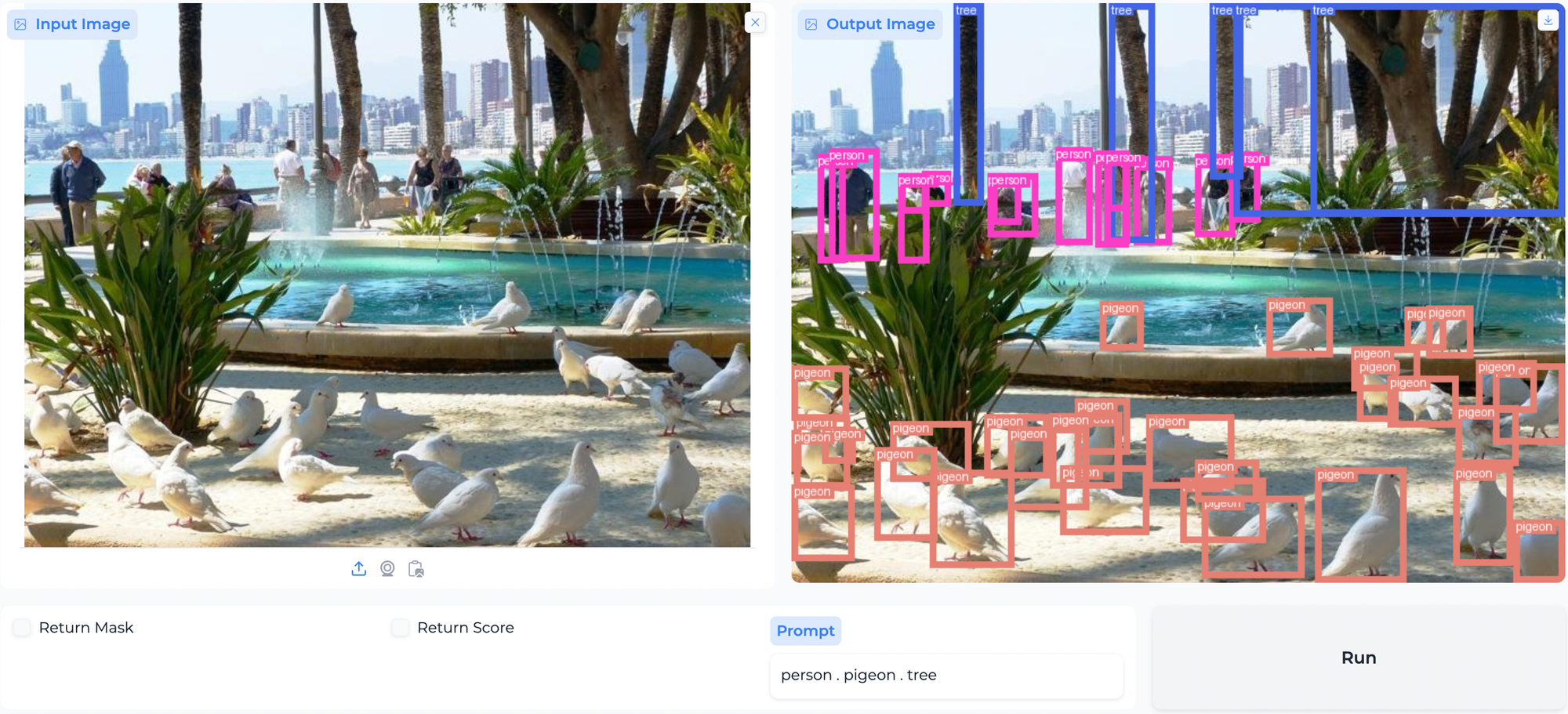
Object Detection and Paperspace Demo
Convey this mission to life
Please ensure that to request DeepDataSpace to get the API key. Please check with the DeepDataSpace for API keys: https://deepdataspace.com/request_api.
To run this demo and begin your experimentation with the mannequin, we’ve got created and added a Jupyter pocket book with this text so as to take a look at it.
First, we’ll clone the repository:
!git clone https://github.com/IDEA-Analysis/Grounding-DINO-1.5-API.git
Subsequent, we’ll set up the required packages:
!pip set up -v -e .Run the code under to generate the hyperlink:
!python gradio_app.py --token ad6dbcxxxxxxxxxx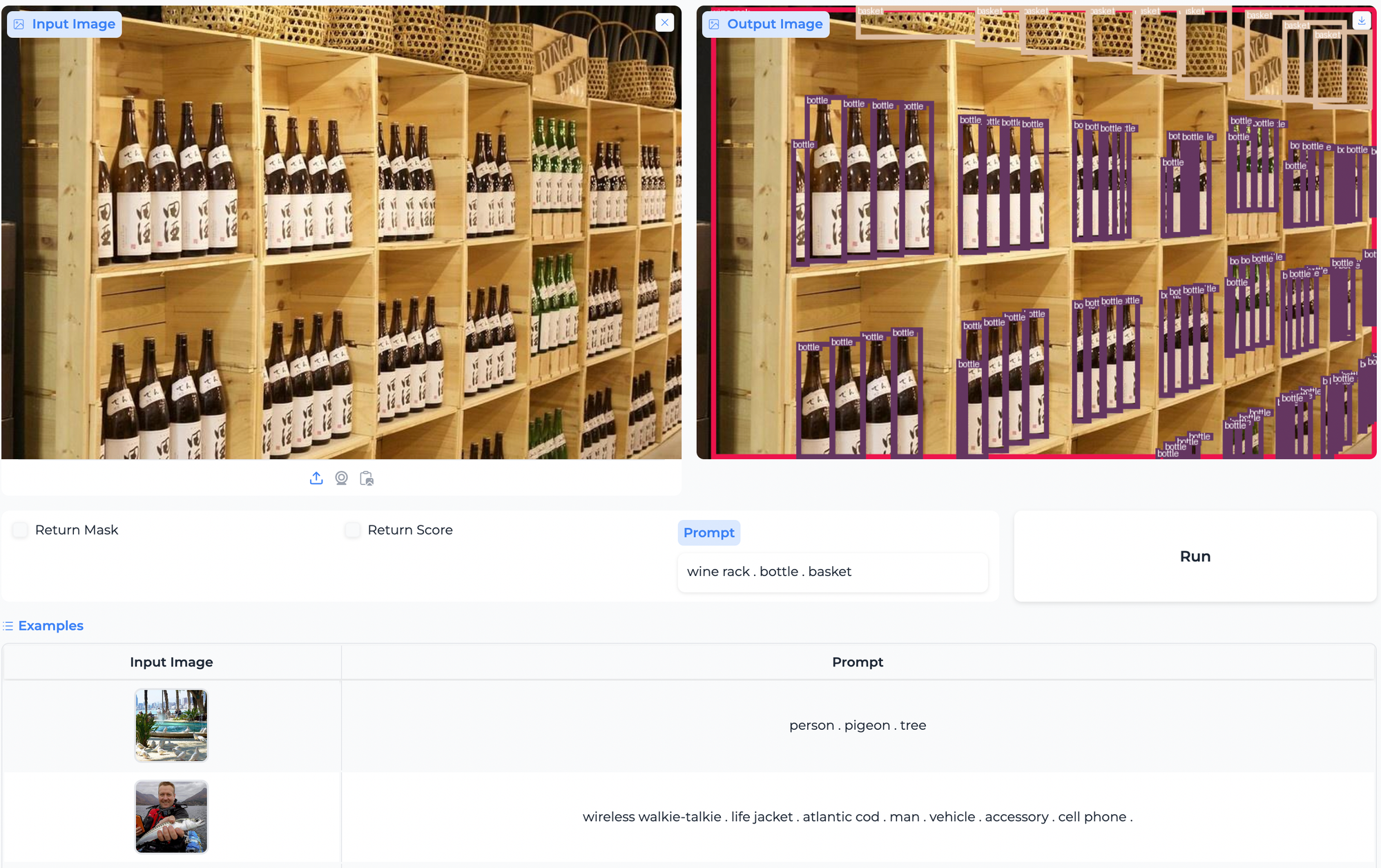
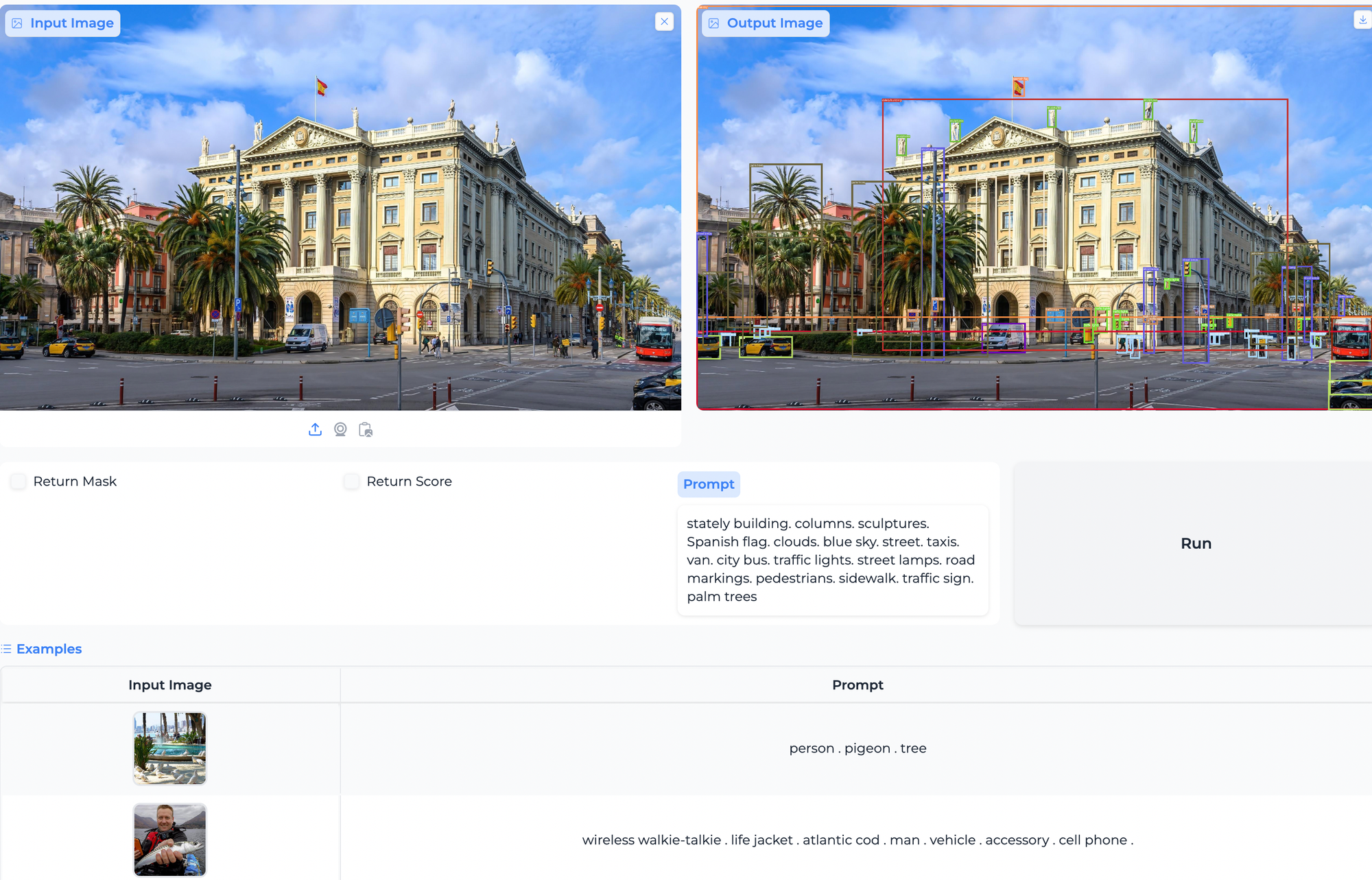
Actual-World Software and Concluding Ideas on Grounding DINO 1.5
- Autonomous Automobiles:
- Detecting and recognizing identified visitors indicators and pedestrians and unfamiliar objects that may seem on the highway, guaranteeing safer navigation.
- Figuring out sudden obstacles, reminiscent of particles or animals, that aren’t pre-labeled within the coaching information.
- Surveillance and Safety:
- Recognizing unauthorized people or objects in restricted areas, even when they have not been seen earlier than.
- Detecting deserted objects in public locations, reminiscent of airports or prepare stations, could possibly be potential safety threats.
- Retail and Stock Administration:
- Figuring out and monitoring gadgets on retailer cabinets, together with new merchandise that won’t have been a part of the unique stock.
- Recognizing uncommon actions or unfamiliar objects in a retailer that would point out shoplifting.
- Healthcare:
- Detecting anomalies or unfamiliar patterns in medical scans, reminiscent of new kinds of tumors or uncommon situations.
- Figuring out uncommon affected person behaviors or actions, particularly in long-term care or post-surgery restoration.
- Robotics:
- Enabling robots to function in dynamic and unstructured environments by recognizing and adapting to new objects or modifications of their environment.
- Detecting victims or hazards in disaster-stricken areas the place the atmosphere is unpredictable and crammed with unfamiliar objects.
- Wildlife Monitoring and Conservation:
- Detecting and figuring out new or uncommon species in pure habitats for biodiversity research and conservation efforts.
- Monitoring protected areas for unfamiliar human presence or instruments that would point out unlawful poaching actions.
- Manufacturing and High quality Management:
- Figuring out defects or anomalies in merchandise on a manufacturing line, together with new kinds of defects not beforehand encountered.
- Recognizing and sorting all kinds of objects to enhance effectivity in manufacturing processes.
This text introduces Grounding DINO 1.5, designed to boost open-set object detection. The main mannequin, Grounding DINO 1.5 Professional, has set new benchmarks on the COCO and LVIS zero-shot checks, marking important progress in detection accuracy and reliability.
Moreover, the Grounding DINO 1.5 Edge mannequin helps real-time object detection throughout numerous purposes, broadening the collection’ sensible applicability.
We hope you will have loved studying the article!