
{kind=link}

Actual-time object detection has discovered trendy purposes in all the things from autonomous automobiles and surveillance methods to augmented actuality and robotics. The essence of real-time object detection lies in precisely figuring out and classifying a number of objects inside a picture or a video body in a fraction of a second.
Over time, quite a few algorithms have been developed to boost the effectivity and accuracy of real-time object detection. The “You Solely Look As soon as” (YOLO) sequence emerged as a outstanding method resulting from its pace and efficiency. The YOLO algorithm revolutionized object detection by framing it as a single regression downside, predicting bounding packing containers and sophistication chances instantly from full pictures in a single analysis. This streamlined method has made YOLO synonymous with real-time detection capabilities.
Researchers have just lately centered on CNN-based object detectors for real-time detection, with YOLO fashions gaining reputation for his or her stability between efficiency and effectivity. The YOLO detection pipeline contains the mannequin ahead course of and Non-maximum Suppression (NMS) post-processing, however each have limitations that lead to suboptimal accuracy-latency trade-offs.
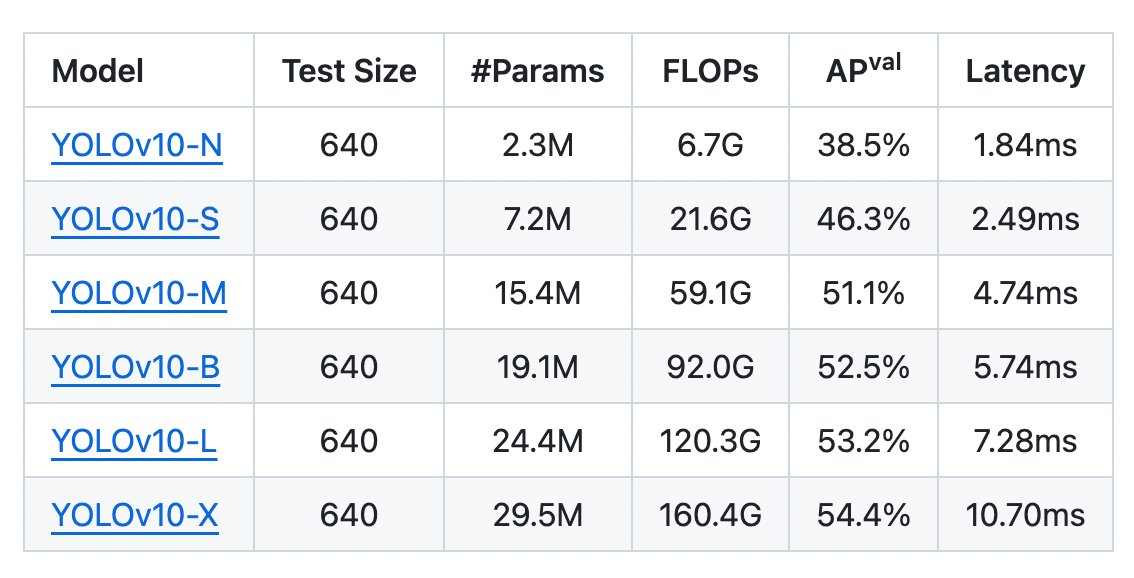
The latest addition to this YOLO sequence is YOLOv10-N / S / M / B / L / X, constructing on its predecessors, YOLOv10 integrates superior strategies to enhance detection accuracy, pace, and robustness in various environments. YOLOv10’s enhancements make it a strong instrument for purposes requiring instant and dependable object recognition, pushing the boundaries of what’s achievable in real-time detection. Experiments present that YOLOv10 considerably outperforms earlier state-of-the-art fashions relating to computation-accuracy trade-offs throughout varied mannequin scales.
What’s YOLOv10?
YOLO fashions sometimes use a one-to-many label task technique throughout coaching, which suggests that one ground-truth object corresponds to a number of optimistic samples. Whereas this improves efficiency, non-maximum suppression (NMS) throughout inference is required to pick the very best prediction, which slows down inference and makes efficiency delicate to NMS hyperparameters. This additional prevents the YOLO fashions from reaching optimum end-to-end deployment.
As mentioned within the YOLOv10 analysis paper, one doable answer is adopting end-to-end DETR architectures, like RT-DETR, which introduces environment friendly encoder and question choice strategies for real-time purposes. Nonetheless, DETRs’ complexity can hinder the stability between accuracy and pace. One other method is exploring end-to-end detection for CNN-based detectors utilizing one-to-one task methods to scale back redundant predictions, although they typically add inference overhead or underperform.
Researchers have experimented with varied spine models (DarkNet, CSPNet, EfficientRep, ELAN) and neck parts (PAN, BiC, GD, RepGFPN) to boost function extraction and fusion. Moreover, mannequin scaling and re-parameterization strategies have been investigated. Regardless of these efforts, YOLO fashions nonetheless face computational redundancy and inefficiencies, leaving room for accuracy enhancements.
The latest analysis paper addresses these challenges by enhancing post-processing and mannequin structure. It proposes a constant twin assignments technique for NMS-free YOLOs, eliminating the necessity for NMS throughout inference and bettering effectivity. The analysis additionally contains an efficiency-accuracy-driven mannequin design technique, incorporating light-weight classification heads, spatial-channel decoupled downsampling, and rank-guided block design to scale back redundancy. For accuracy, the paper explores large-kernel convolution and an efficient partial self-attention module.
YOLOV10 introduces an NMS-free coaching technique for YOLO fashions utilizing twin label assignments and a constant matching metric, which helps to attain excessive effectivity and aggressive efficiency.
Developments in YOLOv10
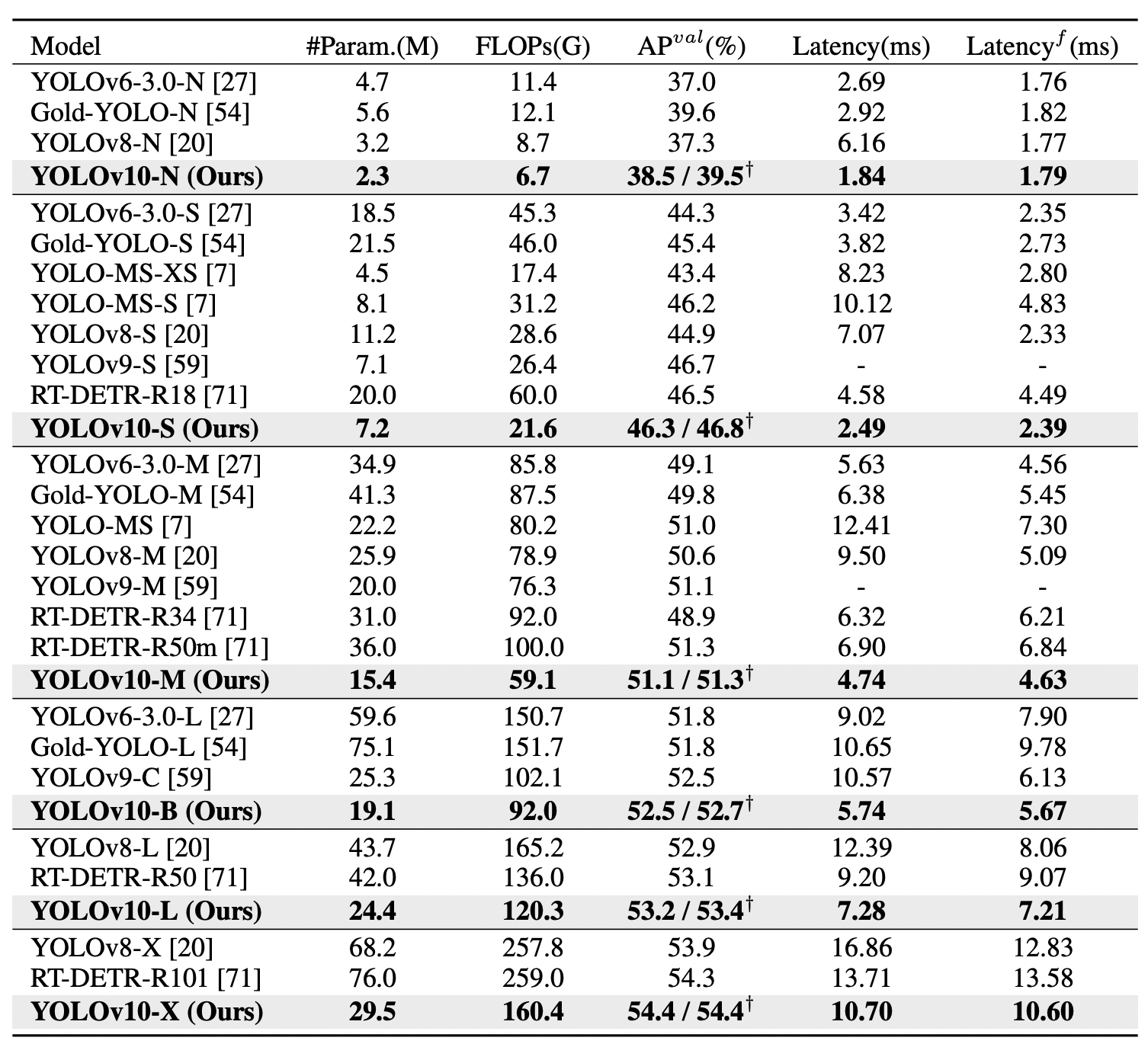
YOLOv10 (N/S/M/B/L/X) has efficiently achieved vital efficiency enhancements on COCO benchmarks. YOLOv10-S and X are notably quicker than RT-DETR-R18 and R101, respectively, with related efficiency. YOLOv10-B reduces latency by 46% in comparison with YOLOv9-C, sustaining the identical efficiency. YOLOv10-L and X outperform YOLOv8-L and X with fewer parameters, and YOLOv10-M matches YOLOv9-M/MS efficiency with fewer parameters.
The six sizes of the YOLOv10 mannequin:
Convey this mission to life
The NMS-free coaching with constant twin assignments cuts the end-to-end latency of YOLOv10-S by 4.63ms, sustaining a powerful efficiency at 44.3% Common Precision or AP.
- The efficiency-driven mannequin design reduces 11.8 million parameters and 20.8 Giga Floating Level Operations Per Second or GFLOPs, reducing YOLOv10-M’s latency by 0.65ms.
- The accuracy-driven mannequin design additionally boosts AP by 1.8 for YOLOv10-S and 0.7 for YOLOv10-M, with minimal latency will increase of simply 0.18ms and 0.17ms, proving its effectiveness.
What are Twin Label Assignments in YOLOv10?
One-to-one matching in YOLO fashions assigns a single prediction to every floor reality, eliminating the necessity for NMS post-processing however leading to weaker supervision and decrease accuracy. To handle this, twin label assignments are used which mix one-to-many and one-to-one methods. A further one-to-one head is launched, similar in construction and optimization to the one-to-many department, which is optimized collectively throughout coaching.
This enables the mannequin to learn from the wealthy supervision of one-to-many assignments whereas utilizing the one-to-one head for environment friendly, end-to-end inference. The one-to-one matching makes use of top-one choice, matching Hungarian efficiency with much less coaching time.
What’s Constant Matching Metric?
In the course of the task of predictions to floor reality situations, each one-to-one and one-to-many approaches use a metric to measure how effectively a prediction matches an occasion. This metric combines the classification rating, the bounding field overlap (IoU), and whether or not the prediction’s anchor level is inside the occasion.
A constant matching metric improves each the one-to-one and one-to-many matching processes, guaranteeing each branches optimize in direction of the identical purpose. This twin method permits for richer supervisory indicators from the one-to-many department whereas sustaining environment friendly inference from the one-to-one department.
The constant matching metric ensures that the very best optimistic pattern (the prediction that greatest matches the occasion) is identical for each the one-to-one and one-to-many branches. That is achieved by making the parameters (α and β) that management the stability between classification and localization duties proportional between the 2 branches.
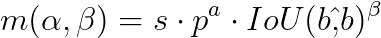
- ( p ) is the classification rating
- ( beta and beta hat) are the expected and floor reality bounding packing containers
- ( s ) is the Spatial prior
- ( alpha ) and ( beta ) are the hyperparameters for balancing classification and localization
By setting the one-to-one parameters proportional to the one-to-many parameters
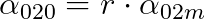
and
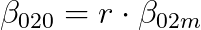
The matching metric aligns each branches to determine the identical greatest optimistic samples. This alignment helps cut back the supervision hole and enhance efficiency.
This constant matching metric ensures that the predictions chosen by the one-to-one department are extremely in keeping with the highest predictions of the one-to-many department, leading to more practical optimization. Thus, this metric demonstrates improved supervision and higher mannequin efficiency.
Mannequin Structure
YOLOv10 consists of the parts beneath, that are the important thing components for mannequin designs and assist to attain effectivity and accuracy.
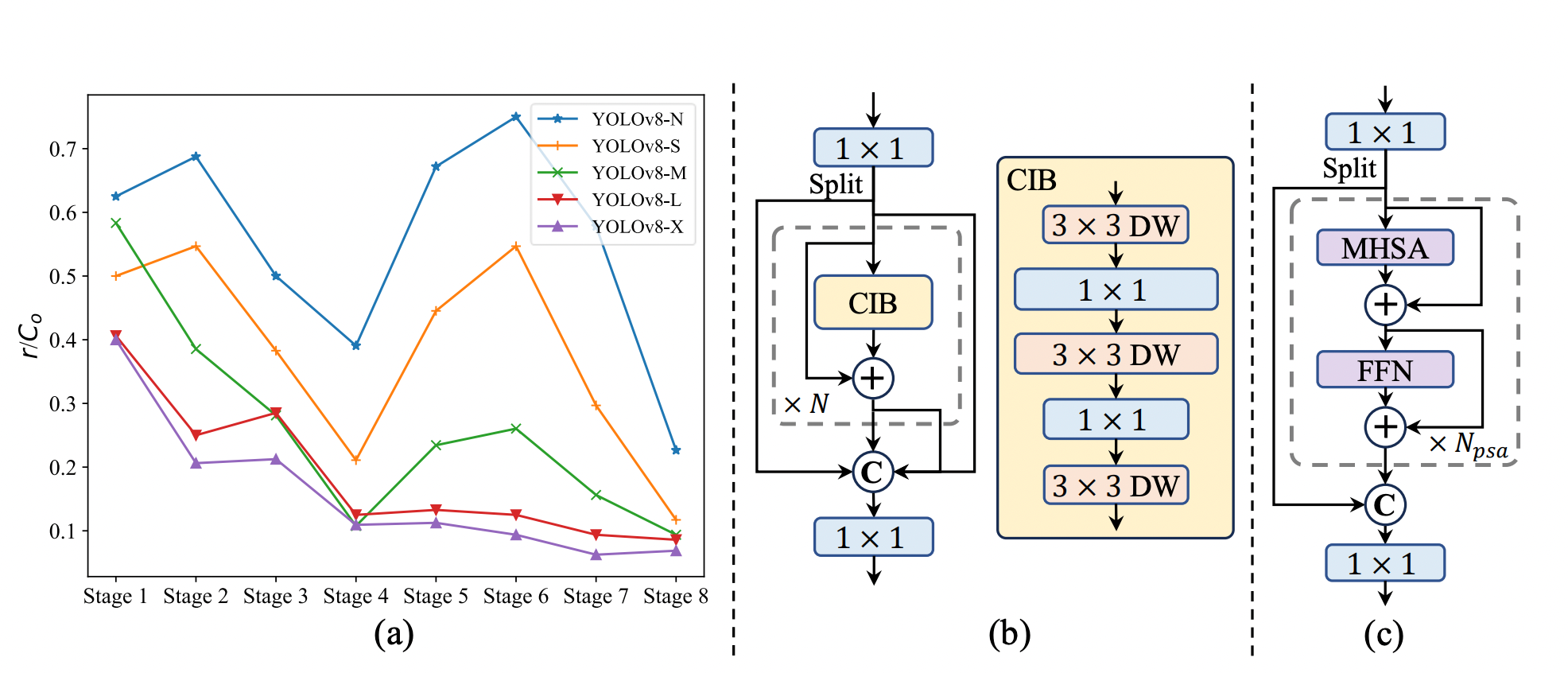
- Light-weight classification head: A light-weight classification head structure contains two depthwise separable convolutions (3×3) adopted by a 1×1 convolution. This reduces computational demand and makes the mannequin quicker and extra environment friendly, notably useful for real-time purposes and deployment on gadgets with restricted assets.
- Spatial-channel decoupled downsampling: In YOLO fashions, downsampling (decreasing the dimensions of the picture whereas growing the variety of channels) is normally achieved utilizing 3×3 normal convolutions with a stride of two. This course of is computationally costly and requires loads of parameters.
To make this course of extra environment friendly, Spatial-channel decoupled downsampling is proposed and contains two steps:
- Pointwise Convolution: This step adjusts the variety of channels with out altering the picture measurement.
- Depthwise Convolution: This step reduces the picture measurement (downsampling) with out considerably growing the variety of computations or parameters.
Decoupling these operations considerably reduces the computational value and the variety of parameters wanted. This method retains extra info throughout downsampling, main to higher efficiency with decrease latency.
- Rank-guided block design: The rank-guided block allocation technique optimizes effectivity whereas sustaining efficiency. Levels are sorted by intrinsic rank, and the essential block in probably the most redundant stage is changed with the CIB. This course of continues till a efficiency drop is detected. This adaptive method ensures environment friendly block designs throughout levels and mannequin scales, reaching greater effectivity with out compromising efficiency. Additional algorithm particulars are offered within the appendix.
- Massive-kernel convolution: The method leverages large-kernel depthwise convolutions selectively in deeper levels to boost mannequin functionality whereas avoiding points with shallow function contamination and elevated latency. The usage of structural reparameterization ensures higher optimization throughout coaching with out affecting inference effectivity. Moreover, large-kernel convolutions are tailored based mostly on mannequin measurement, optimizing efficiency and effectivity.
- Partial self-attention (PSA): The Partial Self-Consideration (PSA) module effectively integrates self-attention into YOLO fashions. By selectively making use of self-attention to solely a part of the function map and optimizing the eye mechanism, PSA enhances the mannequin’s international illustration studying with minimal computational value. This method ensures improved efficiency with out the extreme overhead typical of full self-attention mechanisms.
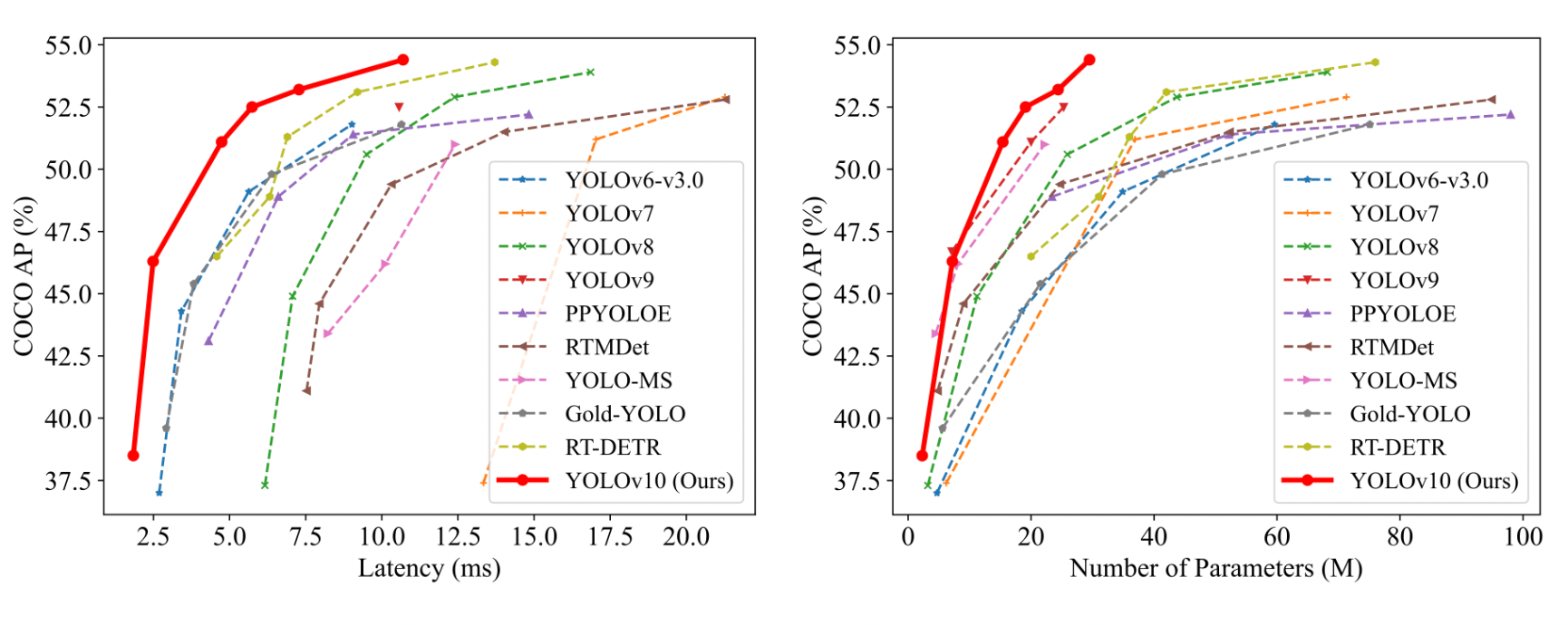
Comparability with SOTA Fashions
YOLOv10 efficiently achieves state-of-the-art efficiency and end-to-end latency throughout varied mannequin scales. In comparison with the baseline YOLOv8 fashions, YOLOv10 considerably improves Common Precision (AP) and effectivity. Particularly, YOLOv10 variants (N/S/M/L/X) obtain 1.2% to 1.4% AP enhancements, with 28% to 57% fewer parameters, 23% to 38% fewer computations, and 37% to 70% decrease latencies.
When in comparison with different YOLO fashions, YOLOv10 demonstrates superior trade-offs between accuracy and computational value. YOLOv10-N and S outperform YOLOv6-3.0-N and S by 1.5 and a couple of.0 AP, respectively, with considerably fewer parameters and computations. YOLOv10-B and M cut back latency by 46% and 62%, respectively, in comparison with YOLOv9-C and YOLO-MS whereas sustaining or bettering efficiency. YOLOv10-L surpasses Gold-YOLO-L with 68% fewer parameters, 32% decrease latency, and a 1.4% AP enchancment.
Moreover, YOLOv10 considerably outperforms RT-DETR in each efficiency and latency. YOLOv10-S and X are 1.8× and 1.3× quicker than RT-DETR-R18 and R101, respectively, with related efficiency.
These outcomes spotlight YOLOv10’s superiority as a real-time end-to-end detector, demonstrating state-of-the-art efficiency and effectivity throughout completely different mannequin scales. This effectiveness is additional validated when utilizing the unique one-to-many coaching method, confirming the affect of our architectural designs.
Paperspace Demo
Convey this mission to life
To run YOLOv10 utilizing Paperspace, we’ll first clone the repo and set up the required packages.
!pip set up -q git+https://github.com/THU-MIG/yolov10.gitAt the moment, YOLOv10 doesn’t have its personal PyPI bundle. Due to this fact, we have to set up the code from the supply.
However earlier than we begin, allow us to confirm the GPU we’re utilizing.
!nvidia-smi
Subsequent, set up the required libraries,
!pip set up -r necessities.txt
!pip set up -e .
These installations are needed to make sure that the mannequin has all the required instruments and libraries to perform accurately.
!wget https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10s.pt
After we run this command, wget will entry the URL offered, obtain the pre-trained weights of the YOLOv10 small mannequin yolov10s.pt, and reserve it within the present listing.
As soon as achieved we’ll run the app.py file to generate the url.
python app.pyObject detection duties utilizing YOLOv10
Inference on Pictures
YOLOv10 supplies weight information pre-trained on the COCO dataset in varied sizes. First we’ll obtain the weights.
!mkdir -p {HOME}/weights
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10n.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10s.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10m.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10b.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10x.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/obtain/v1.1/yolov10l.pt
!ls -lh {HOME}/weightsSubsequent strains of code will use the YOLO mannequin to course of the enter picture canine.jpeg, detect the objects inside it based mostly on the mannequin’s coaching, and save the output picture with detected objects highlighted. The outcomes will probably be saved within the specified listing.
%cd {HOME}
!yolo process=detect mode=predict conf=0.25 save=True
mannequin={HOME}/weights/yolov10n.pt
supply={HOME}/knowledge/canine.jpeg
import cv2
import supervision as sv
from ultralytics import YOLOv10
mannequin = YOLOv10(f'{HOME}/weights/yolov10n.pt')
picture = cv2.imread(f'{HOME}/knowledge/canine.jpeg')
outcomes = mannequin(picture)[0]
detections = sv.Detections.from_ultralytics(outcomes)
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated_image = bounding_box_annotator.annotate(
scene=picture, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections)
sv.plot_image(annotated_image)
0: 640×384 1 particular person, 1 canine, 8.3ms
Velocity: 1.8ms preprocess, 8.3ms inference, 0.9ms postprocess per picture at form (1, 3, 640, 384)
This cell runs inference utilizing the YOLOv10 mannequin on an enter picture, processes the outcomes to extract detections, and annotates the picture with bounding packing containers and labels utilizing the supervision library to show the outcomes.
Conclusion
On this weblog, we mentioned about YOLOv10, a brand new member within the YOLO sequence. YOLOv10 has tailored development in each post-processing and mannequin structure of YOLOs for object detection. The foremost method contains NMS-free coaching with constant twin assignments for extra environment friendly detection. These enhancements lead to YOLOv10, a real-time object detector that outperforms different superior detectors in each efficiency and latency.
We hope you loved the article! Maintain a watch out for half 2 of our weblog, the place we’ll be evaluating YOLOv10 with different YOLO fashions.