
{kind=link}

On this article, we’ll discover ways to run inference utilizing the quantized model of IDEFICS and fine-tune IDEFICS-9b utilizing Paperspace A100 GPU. We may even fine-tune IDEFICS 9B, a variant of the progressive visible language mannequin. This fine-tuning course of entails methods like LoRa, that are particularly designed to boost the mannequin’s efficiency in sure areas.
The A100 GPUs on Paperspace are highly effective and versatile instruments designed for high-performance computing duties. Leveraging NVIDIA’s Ampere structure, these GPUs supply distinctive processing energy, making them preferrred for AI, machine studying, and information analytics workloads. With regards to operating inference and fine-tuning IDEFICS-9 b, the excessive processing energy of those GPUs can considerably velocity up the method, permitting you to iterate and experiment extra shortly.
With as much as 90 GB of reminiscence, these GPUs can effectively deal with giant datasets and sophisticated fashions. Paperspace’s cloud infrastructure ensures scalable and versatile entry to those GPUs, enabling builders and researchers to speed up their initiatives with out the necessity for vital upfront funding in {hardware}. The mix of superior know-how and ease of use makes A100 GPUs on Paperspace a worthwhile useful resource for cutting-edge computational duties.
What’s IDEFICS?
IDEFICS (Picture-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access visible language mannequin that may course of sequences of photos and textual content to provide textual content outputs, much like GPT-4.
The mannequin is constructed on DeepMind’s Flamingo mannequin, which is not publicly out there. IDEFICS makes use of publicly out there information and fashions, particularly LLaMA v1 and OpenCLIP, and is obtainable in two variations: a base model and an instructed model, every out there in 9 billion and 80 billion parameter sizes.
Lately, IDEFICS2 was launched. The mannequin is skilled to reply questions on photos, similar to ‘What colour is the automotive?’ or ‘How many individuals are within the image? ‘. It may additionally describe visible content material, create tales grounded in a number of photos, extract data from paperwork, and carry out primary arithmetic operations.
What’s fine-tuning?
Wonderful-tuning is a course of that entails taking a pre-trained mannequin and coaching it for a selected job utilizing a selected dataset. This course of entails updating the mannequin’s weights based mostly on the brand new job’s information, sometimes with a decrease studying price, to make slight changes with out drastically altering the pre-trained information.
Pre-trained fashions are sometimes skilled on giant, various datasets and seize many options. They’re skilled to carry out effectively on a selected job, similar to sentiment evaluation, picture classification, or any domain-specific utility. Utilizing information particular to the brand new job, the mannequin can be taught the nuances and specifics of that information, resulting in improved accuracy and efficiency.
Wonderful-tuning requires considerably much less computational assets and time than coaching a mannequin from scratch.
On this case, we’ll use ‘TheFusion21/PokemonCards‘ to fine-tune the mannequin. Right here is the info construction of this dataset.
{
"id": "pl1-1",
"image_url": "https://photos.pokemontcg.io/pl1/1_hires.png",
"caption": "A Stage 2 Pokemon Card of sort Lightning with the title ""Ampharos"" and 130 HP of rarity ""Uncommon Holo"" developed from Flaaffy from the set Platinum and the flavour textual content: ""None"". It has the assault ""Gigavolt"" with the price Lightning, Colorless, the power value 2 and the injury of 30+ with the outline: ""Flip a coin. If heads, this assault does 30 injury plus 30 extra injury. If tails, the Defending Pokemon is now Paralyzed."". It has the assault ""Mirror Vitality"" with the price Lightning, Colorless, Colorless, the power value 3 and the injury of 70 with the outline: ""Transfer an Vitality card connected to Ampharos to 1 of your Benched Pokemon."". It has the power ""Harm Bind"" with the outline: ""Every Pokemon that has any injury counters on it (each yours and your opponent's) cannot use any Poke-Powers."". It has weak point towards Combating +30. It has resistance towards Steel -20.",
"title": "Ampharos",
"hp": "130",
"set_name": "Platinum"
}Wonderful-tuning IDEFICS-9B
Convey this challenge to life
Set up
We’ll begin by putting in a couple of vital packages. We advocate our customers to click on the hyperlink supplied with the article to spin up the pocket book and begin working.
!pip set up -q datasets
!pip set up -q git+https://github.com/huggingface/transformers.git
!pip set up -q bitsandbytes sentencepiece speed up loralib
!pip set up -q -U git+https://github.com/huggingface/peft.gitWe’ll set up the datasets library. This library supplies instruments for accessing and managing datasets for coaching and evaluating machine studying fashions. We’re additionally putting in transformers and bitsandbytes for environment friendly fine-tuning.
Bitsandbytes is an unbelievable library that enables loading fashions in 4-bit precision, making it extraordinarily helpful for fine-tuning giant language fashions with Qlora.
As soon as these packages are efficiently put in we’ll import the mandatory libraries.
#import the libraries
import torch
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
from PIL import Picture
from transformers import IdeficsForVisionText2Text, AutoProcessor, Coach, TrainingArguments, BitsAndBytesConfig
import torchvision.transforms as transformsLoad the Quantized Mannequin
Subsequent, we’ll load the quantized model of the mannequin, so let’s get the load the mannequin. We’ll choose the gadget as ‘CUDA’; if ‘CUDA’ shouldn’t be out there we’ll use CPU.
gadget = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b"
#load the mannequin in 4-bit precision
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
llm_int8_skip_modules=["lm_head", "embed_tokens"],
)
processor = AutoProcessor.from_pretrained(checkpoint, use_auth_token=True)
We’ll load the mannequin in 4-bit precision, which reduces reminiscence utilization and may velocity up processing. Additionall,y we’ll use a method referred to as double quantization, a method that may enhance the accuracy of the 4-bit quantized mannequin. Subsequent,a processor is initializedr to deal with the mannequin’s inputs and outputs utilizing the pre-trained checkpoint.
mannequin = IdeficsForVisionText2Text.from_pretrained(checkpoint, quantization_config=bnb_config, device_map="auto")
This code initializes the IdeficsForVisionText2Text mannequin by loading a pre-trained model from the required checkpoint. Subsequent, we’ll apply the quantization settings outlined in bnb_config to load the mannequin in an environment friendly 4-bit precision format.
Moreover, the code makes use of computerized gadget mapping to distribute the mannequin’s parts throughout the out there {hardware}, optimizing for efficiency and useful resource utilization.
As soon as the downloads are over, we’ll print the mannequin.
print(mannequin)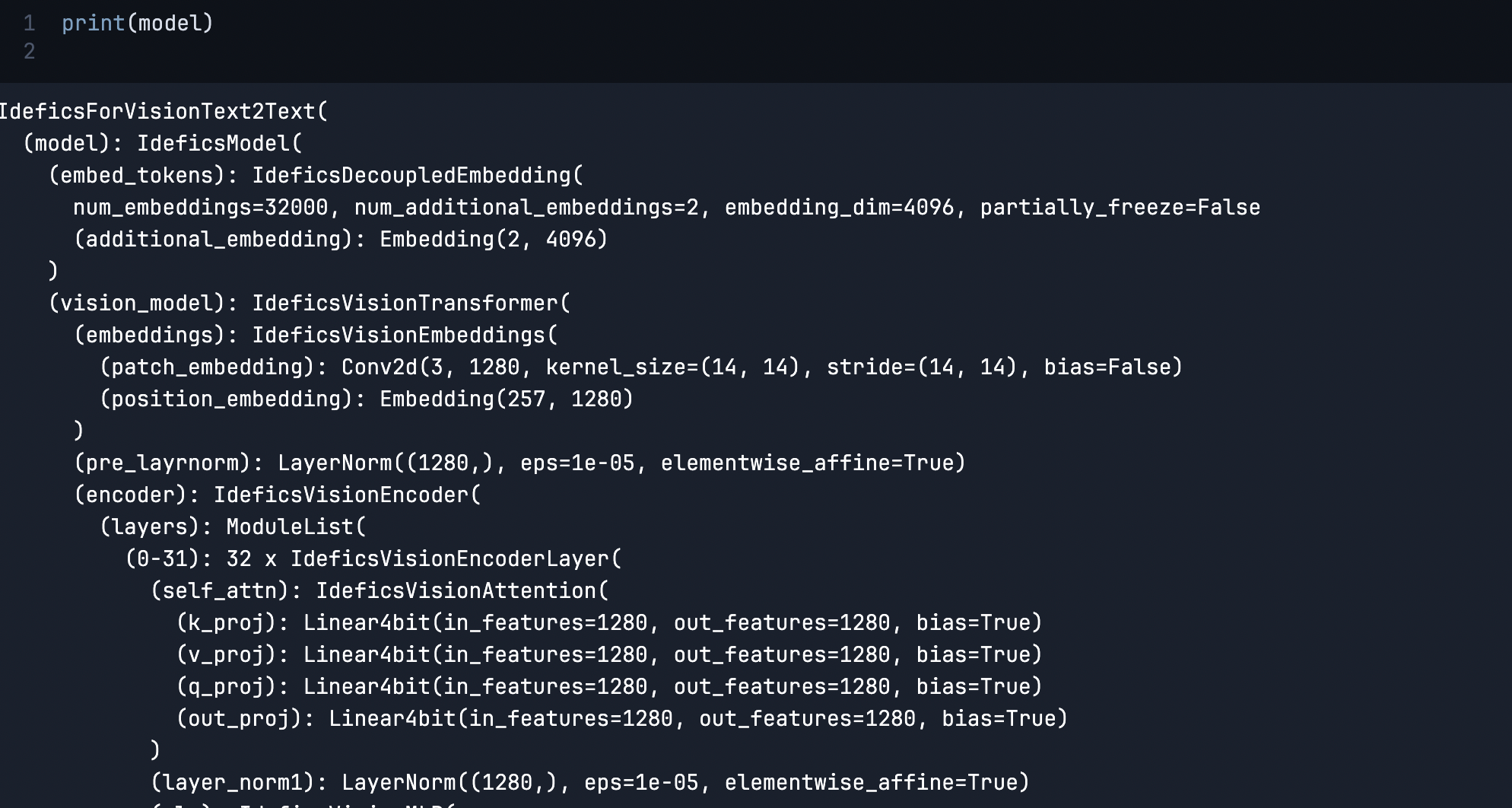
This prints the complete mannequin pipeline with the layer and embedding particulars.
Inference
We’ll use this mannequin for inference and check the mannequin.
def model_inference(mannequin, processor, prompts, max_new_tokens=50):
tokenizer = processor.tokenizer
bad_words = ["<image>", "<fake_token_around_image>"]
if len(bad_words) > 0:
bad_words_ids = tokenizer(bad_words, add_special_tokens=False).input_ids
eos_token = "</s>"
eos_token_id = tokenizer.convert_tokens_to_ids(eos_token)
inputs = processor(prompts, return_tensors="pt").to(gadget)
generated_ids = mannequin.generate(**inputs, eos_token_id=[eos_token_id], bad_words_ids=bad_words_ids, max_new_tokens=max_new_tokens, early_stopping=True)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)The perform processes enter prompts, generates textual content utilizing the mannequin whereas filtering out undesirable tokens, and prints the ensuing textual content. The perform makes use of the tokenizer and processor to deal with textual content tokenization and decoding this in flip ensures that the generated textual content adheres to specified constraints.
url = "https://hips.hearstapps.com/hmg-prod/photos/dog-puppy-on-garden-royalty-free-image-1586966191.jpg?crop=0.752xw:1.00xh;0.175xw,0&resize=1200:*"
prompts = [
# "Instruction: provide an answer to the question. Use the image to answer.n",
url,
"Question: What's on the picture? Answer:",
]
model_inference(mannequin, processor, prompts, max_new_tokens=5)
{kind=link}
Query: What’s on the image? Reply: A pet.
We’ll put together the dataset that we’ll use for our fine-tuning job.
def convert_to_rgb(picture):
# `picture.convert("RGB")` would solely work for .jpg photos, because it creates a mistaken background
# for clear photos. The decision to `alpha_composite` handles this case
if picture.mode == "RGB":
return picture
image_rgba = picture.convert("RGBA")
background = Picture.new("RGBA", image_rgba.dimension, (255, 255, 255))
alpha_composite = Picture.alpha_composite(background, image_rgba)
alpha_composite = alpha_composite.convert("RGB")
return alpha_composite
def ds_transforms(example_batch):
image_size = processor.image_processor.image_size
image_mean = processor.image_processor.image_mean
image_std = processor.image_processor.image_std
image_transform = transforms.Compose([
convert_to_rgb,
transforms.RandomResizedCrop((image_size, image_size), scale=(0.9, 1.0), interpolation=transforms.InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=image_mean, std=image_std),
])
prompts = []
for i in vary(len(example_batch['caption'])):
# We cut up the captions to keep away from having very lengthy examples, which might require extra GPU ram throughout coaching
caption = example_batch['caption'][i].cut up(".")[0]
prompts.append(
[
example_batch['image_url'][i],
f"Query: What's on the image? Reply: That is {example_batch['name'][i]}. {caption}</s>",
],
)
inputs = processor(prompts, rework=image_transform, return_tensors="pt").to(gadget)
inputs["labels"] = inputs["input_ids"]
return inputs
# load and put together dataset
ds = load_dataset("TheFusion21/PokemonCards")
ds = ds["train"].train_test_split(test_size=0.002)
train_ds = ds["train"]
eval_ds = ds["test"]
train_ds.set_transform(ds_transforms)
eval_ds.set_transform(ds_transforms)The convert_to_rgb perform ensures photos are in RGB format, to deal with several types of photos. The ds_transforms perform processes a batch of examples by remodeling photos, making ready textual content prompts, and changing the whole lot right into a format appropriate for mannequin coaching or inference. The perform helps to use vital transformations, tokenizes the prompts, and units up the inputs and labels for the mannequin.
We’ll load the ‘TheFusion21/PokemonCards‘ as prompt by hugging face to fine-tune the mannequin. Nonetheless, please be at liberty to make use of any dataset with the proper format.
LoRA
Low-rank adaptation (LoRA) is a PEFT approach that reduces a big matrix into two smaller low-rank matrices inside the consideration layers, considerably lowering the variety of parameters that want fine-tuning.
model_name = checkpoint.cut up("/")[1]
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
)
mannequin = get_peft_model(mannequin, config)This code configures and applies Low-Rank Adaptation (LoRA) to our mannequin IDEFICS9b:
- Extract the Mannequin Title: From the checkpoint, extract the mannequin.
- Configure LoRA: Set LoRA parameters, together with the rank of the low-rank matrices to 16, goal modules, dropout, and bias dealing with.
- Set Dropout: Units a dropout price of 5% for LoRA. Dropout is a regularization approach to forestall overfitting by randomly setting among the enter models to zero throughout coaching.
- Apply LoRA to the Mannequin: Modify the mannequin to incorporate LoRA within the specified layers with the offered configuration.
mannequin.print_trainable_parameters()
trainable params: 19,750,912 || all params: 8,949,430,544 || trainable%: 0.2206946230030432
Coaching
Subsequent, we’ll finetune the mannequin,
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=2e-4,
fp16=True,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=8,
dataloader_pin_memory=False,
save_total_limit=3,
evaluation_strategy="steps",
save_strategy="steps",
save_steps=40,
eval_steps=20,
logging_steps=20,
max_steps=20,
remove_unused_columns=False,
push_to_hub=False,
label_names=["labels"],
load_best_model_at_end=True,
report_to=None,
optim="paged_adamw_8bit",
)
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=train_ds,
eval_dataset=eval_ds,
)
coach.prepare()[20/20 , Epoch 0/1]
| Step | Coaching Loss | Validation Loss |
|---|---|---|
| 20 | 1.450000 | 0.880157 |
| 40 | 0.702000 | 0.675355 |
Out[23]:TrainOutput(global_step=40, training_loss=1.0759869813919067, metrics={‘train_runtime’: 403.1999, ‘train_samples_per_second’: 1.587, ‘train_steps_per_second’: 0.099, ‘total_flos’: 1445219210656320.0, ‘train_loss’: 1.0759869813919067, ‘epoch’: 0.05})
This code will begin the coaching course of in response to the required parameters, similar to the educational price, precision, batch sizes, gradient accumulation, and test pointing technique. We use a 16-bit floating level precision for sooner and extra environment friendly coaching and can use the optimizer for 8-bit precision.
# test era after finetuning
url = "https://photos.pokemontcg.io/pop6/2_hires.png"
prompts = [
url,
"Question: What's on the picture? Answer:",
]
# test era once more after finetuning
check_inference(mannequin, processor, prompts, max_new_tokens=100)Query: What’s on the image? Reply: That is Lucario. A Stage 2 Pokemon Card of sort Combating with the title Lucario and 90 HP of rarity Uncommon developed from Pikachu from the set Neo Future and the flavour textual content: It may use its tail as a whip
Conclusion
With this, we reached the tip of the article. We had been in a position to fine-tune our mannequin utilizing the Pokemon dataset efficiently. We are able to push our mannequin to hugging faces and use the mannequin for inferencing.
Wonderful-tuning multimodal fashions calls for fastidiously balancing computational assets and coaching methods to realize the most effective outcomes.
The NVIDIA A100 GPU, out there by way of platforms like Paperspace, is a superb alternative for fine-tuning multimodal fashions as a consequence of its excessive efficiency, giant reminiscence capability, and scalability. These options permit environment friendly dealing with of complicated and large-scale duties concerned in integrating visible and textual information, resulting in sooner and simpler mannequin coaching and deployment.
We hope you loved the article!