
{kind=link}

One of the well-liked, current purposes of diffusion modeling is StoryDiffusion. This undertaking goals to present extra management over to the person when chaining sequential diffusion mannequin text-to-image generations, conserving traits of a personality or model as a way to assist facilitate a visible narrative. As a result of the strategy is so versatile and plug-and-play, it may be mixed with PhotoMaker for a good larger diploma of constancy within the last output.
Because it’s open-source launch three weeks in the past, StoryDiffusion has already gained greater than 4900 stars on GitHub, and the undertaking exhibits nice promise for additional adaptation with different methods and fashions. On this tutorial, we are going to present easy methods to get StoryDiffusion working on highly effective NVIDIA A100 GPUs in Paperspace Notebooks to quickly generate new comics. We are going to begin with a brief overview of the underlying know-how, earlier than leaping into the code demo itself.
How does StoryDiffusion work?
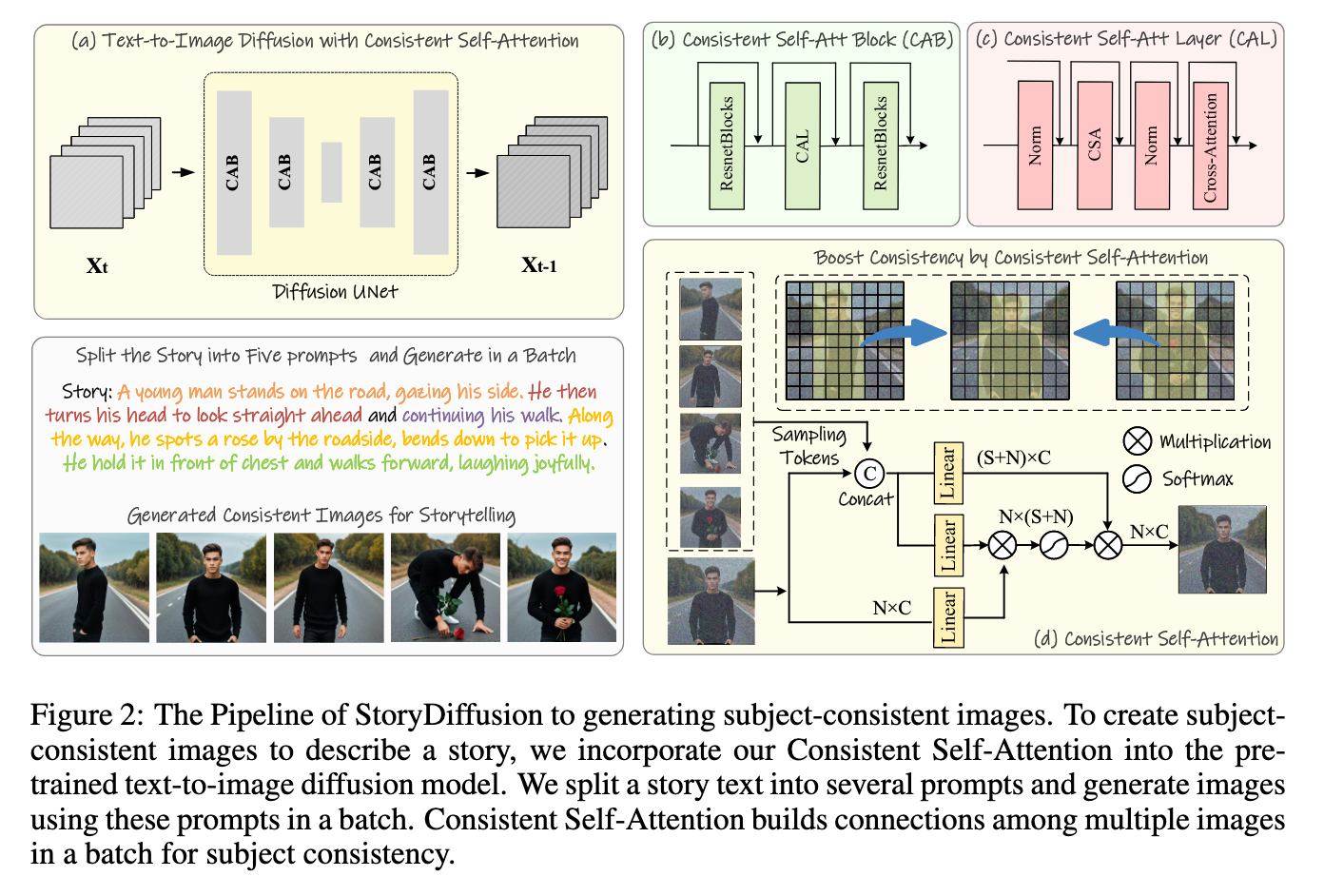
StoryDiffusion is actually a pipeline for creating linked photos with shared options. It achieves this via the intelligent utility of the paper’s creator’s novel consideration mechanism, Constant Self-Consideration, throughout a collection of linked prompts. Their Constant Self-Consideration “technique performs the self-attention throughout a batch of photos, facilitating interactions amongst options of various photos. One of these interplay promotes the mannequin to the convergence of characters, faces, and attires throughout the technology course of.” (Supply).
We will see an instance from the paper displaying how this mechanism works with code beneath.
def ConsistentSelfAttention(images_features, sampling_rate, tile_size):
"""
images_tokens: [B, C, N]
sampling_rate: Float (0-1)
tile_size: Int
"""
output = zeros(B, N, C), depend = zeros(B, N, C), W = tile_size
for t in vary(0, N - tile_size + 1):
# Use tile to override out of GPU reminiscence
tile_features = images_tokens[t:t + W, :, :]
reshape_featrue = tile_feature.reshape(1, W*N, C).repeat(W, 1, 1)
sampled_tokens = RandSample(reshape_featrue, fee=sampling_rate, dim=1)
# Concat the tokens from different photos with the unique tokens
token_KV = concat([sampled_tokens, tile_features], dim=1)
token_Q = tile_features
# carry out consideration calculation:
X_q, X_k, X_v = Linear_q(token_Q), Linear_k(token_KV),Linear_v(token_KV)
output[t:t+w, :, :] += Consideration(X_q, X_k, X_v)
depend[t:t+w, :, :] += 1
output = output/depend
return outputIn observe, this permits for a coaching free methodology to retain the coarse to high-quality options of the pictures throughout the generated outputs. This permits for the collection of outputted photos to evolve to the overall traits of that batch whereas nonetheless remaining trustworthy to the unique textual content immediate.

They discovered that their method alone really outperformed SOTA picture consistency methods like IP-Adapter or Picture Maker. As well as, their coaching free methodology additionally permits for the person to make use of further methods like Picture Maker to present much more management over the synthesized photos, and Picture Maker is a key a part of making the usable pipeline for the demo work with real looking, human topics.
StoryDiffusion demo
Carry this undertaking to life
Working StoryDiffusion with Paperspace is straightforward. All we have to do is click on the hyperlink above, and spin up our new Paperspace Pocket book on an NVIDIA A100 to get began. As soon as our Machine is working, we will open a terminal window, and paste the next code snippet in. This may do all of our setup for us, and launch the mannequin demo!
git-lfs clone https://huggingface.co/areas/YupengZhou/StoryDiffusion
cd StoryDiffusion
pip set up -r necessities.txt
python app.py --share Click on the general public Gradio URL to proceed onto the appliance. This may open in a brand new window.
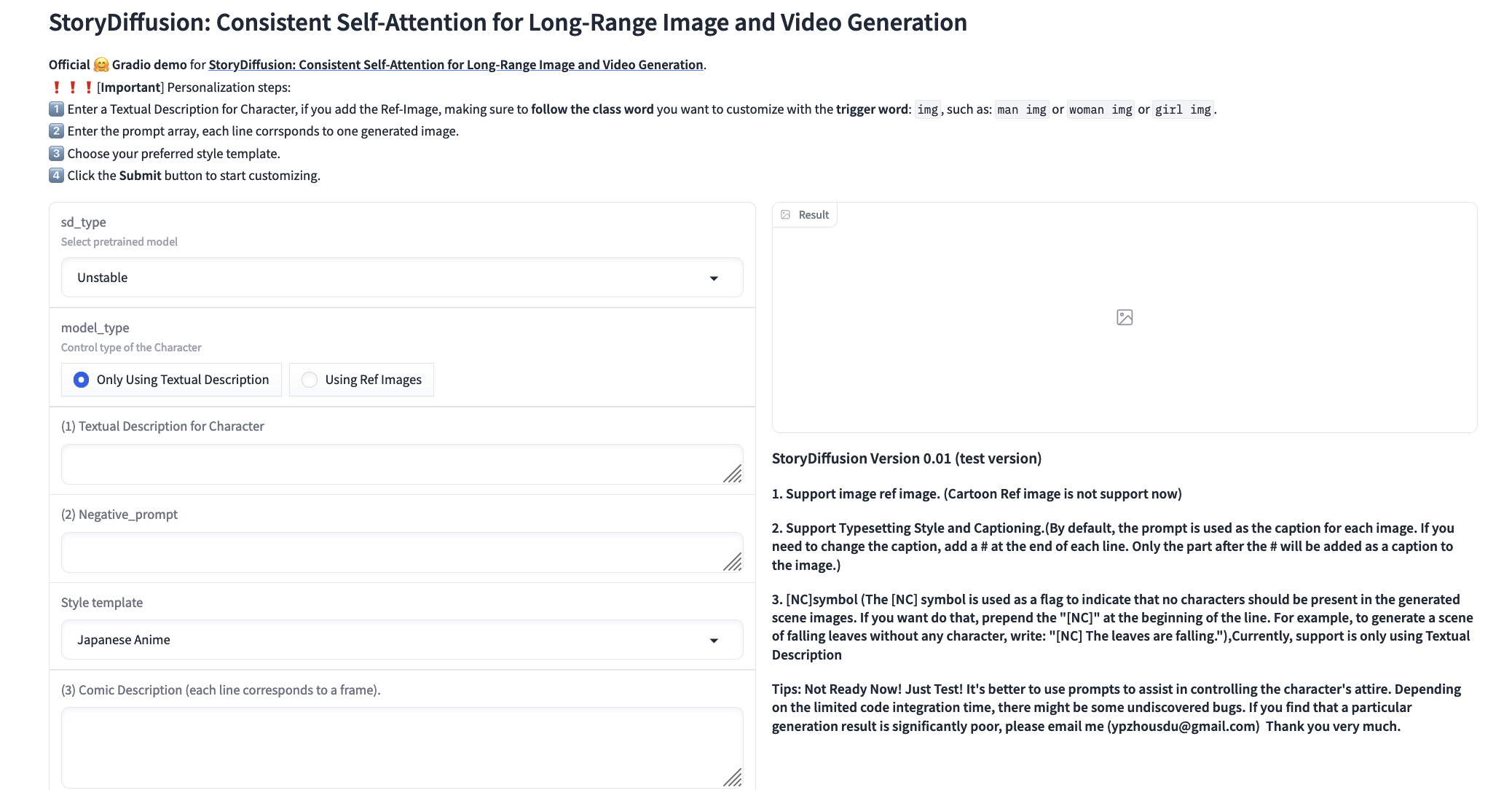
From right here, we will get began producing our story. They’ve supplied directions on the prime and proper hand aspect of the demo, in addition to further examples on the backside that we will use. Learn these fastidiously as a way to get the generations proper.
To start, we have to select our mannequin. They supply Unstable Diffusion and RealVision 4.0 for the person. We suggest utilizing RealVision if human realism is the specified final result, and Unstable Diffusion for just about each different scenario.
When you intend to make use of reference photos, we will subsequent submit them right here by toggling the ‘Utilizing Ref Photographs’ button. This may reload the modal to permit us to add photos. Add a wide range of photos which have a transparent depiction of the topic’s options we wish to perform to the outputs. We suggest 10-20 headshots/portrait photos, and an extra 10-20 at totally different angles and distances from the topic. This may make sure the mannequin has one of the best understanding of the topic in several positions. We are going to then want so as to add a textual description for the character. If we included reference photos, then we have to add IMG to permit Picture Maker to operate higher.
Subsequent, enter within the textual content description. For this, we wish to not really write out a “story”. As an alternative, it’s more practical to explain what the topic is doing in every body of the comedian. For instance, we might use:
A mad scientist mixes chemical compounds in his lab
a mad scientist is thrown again from an explosion of purple gasoline
a mad scientist with glowing eyes screams in ache
a mad scientist with glowing eyes and superpowers fires lasers from his eyesFor the model template, this may have an effect on the ultimate output considerably. We suggest utilizing “No Fashion” until the particular, desired model is listed within the dropdown.
Lastly, we get to the hyperparameter tuning. We suggest leaving every little thing on the default settings. The three exceptions are the dimensions dimensions, the steering scale, and the model power. We could wish to regulate our output dimension (peak and width) as a way to higher match the specified form of our comedian. Adjusting the steering scale impacts how strongly the textual content immediate controls the output, so elevating it could actually improve the constancy to the textual content but in addition dangers introducing artifacts and different Secure Diffusion quirks. Lastly, the model power impacts how vital the power of the reference photos are.
If we put all of it collectively, we get one thing like the next picture. Have in mind, we added a bit extra taste into the descriptions of the prompts:

You possibly can run this demo utilizing the hyperlink beneath!
Carry this undertaking to life
Closing ideas
General, we’re fairly impressed with the capabilities of this mannequin. It has a protracted solution to go in as far as really taking a narrative from a person and turning right into a viable comedian, however this pipeline represents a tangible step ahead. We’re excited to see their text-to-video code launch utilizing Constant Self-Consideration within the coming months, as that needs to be an much more helpful utility of this new method.