
{kind=link}
Introduction
The Retrieval-Augmented Era method combines LLMs with a retrieval system to enhance response high quality. Nevertheless, inaccurate retrieval can result in sub-optimal responses. Cohere’s re-ranker mannequin enhances this course of by evaluating and ordering search outcomes based mostly on contextual relevance, bettering accuracy and saving time for particular info seekers. This text offers a information on implementing Cohere command re-ranker mannequin for doc re-ranking, evaluating its effectiveness with and with out the re-ranker. It makes use of a pipeline to display each situations, offering insights into how the re-ranker mannequin can streamline info retrieval and enhance search duties.

The article will dive into using the Cohere Command, Embedding and Reranker fashions in doc embeddings, responses, and re-ranking. It focuses on the accuracy variations between responses with and with out Reranker fashions. The experiment will use Langchain instruments, together with the Cohere Reranker implementation, with Nvidia’s Kind 10K as enter and Deeplake Vector retailer for doc storage.
Studying Goals
- Learners will grasp the idea of mixing massive language fashions with retrieval techniques to boost generated responses by offering extra context.
- Members will change into aware of Cohere’s reranker mannequin, which evaluates and reorders search outcomes based mostly on contextual relevance to enhance the accuracy of responses.
- College students will achieve hands-on expertise in implementing Cohere’s reranker mannequin for doc re-ranking, together with establishing a pipeline for doc ingestion, question processing, and response era.
- Members will discover ways to conduct a side-by-side comparability of search outcomes with and with out using the reranker mannequin, highlighting the distinction in response high quality and relevance.
- Learners will perceive find out how to combine numerous parts corresponding to Cohere command , embeddings, Deeplake vector retailer, and retrieval QA chain to construct an efficient search and response era system.
- College students will discover strategies to optimize response era by tuning prompts and leveraging reranker fashions to make sure extra correct and contextually acceptable responses.
- Members will find out about situations the place the reranker mannequin can considerably enhance response accuracy, corresponding to when the vector retailer incorporates numerous content material or paperwork of comparable sort.
This text was printed as part of the Knowledge Science Blogathon.
Doc Retrieval and Query Answering
Let’s receive our free Cohere API Key earlier than we begin with the doc ingestion and query answering. First, create an account at Cohere should you don’t have one. Then, generate a Trial key. Go
to this hyperlink and generate a Trial key.
Then, let’s setup our improvement atmosphere for operating the experiments. We have to set up few packages to run the experiments. Beneath, set up the record of packages required.
cohere==5.2.6
deeplake==3.9.0
langchain==0.1.16
tiktoken==0.6.0
langchain_cohere==0.1.4As soon as the packages are put in, we’re able to proceed with the experiments. First, we’ll ingest the doc into the vector retailer. We will probably be utilizing Deeplake vector retailer to retailer the doc embeddings.
Step1: Import Libraries
First make the mandatory imports. We are going to want the Deeplake vector retailer, PyPDFLoader, CharacterTextSplitter, PromptTemplate and RetrievalQA modules from Langchain. We may even import ChatCohere and CohereEmbeddings from langchain_cohere.
from langchain.vectorstores.deeplake import DeepLake
from langchain.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_cohere import ChatCohere
from langchain_cohere import CohereEmbeddingsStep2: Initializing CohereEmbeddings and DeepLake
Initialize the CohereEmbeddings utilizing the Cohere API key that we generated earlier. Additionally, point out the title of the embeddings mannequin for use.
There are a number of choices to selected from. An in depth description of the mannequin in listed right here. We will probably be utilizing the embed-english-v3.0 mannequin to generate the embeddings. Beneath is the code to initialize the embeddings mannequin and Deeplake vector retailer utilizing the embeddings.
embeddings = CohereEmbeddings(
mannequin="embed-english-v3.0",
cohere_api_key=API_KEY,
)
docstore = DeepLake(
dataset_path="deeplake_vstore",
embedding=embeddings,
verbose=False,
num_workers=4,
)Right here, the trial API key generated earlier serves because the API_KEY, and ‘deeplake_vstore’ denotes the trail the place the vector retailer will probably be created domestically.
Step3: Ingesting Doc into Vector Retailer
Now that we have now setup the vector retailer, let’s ingest the doc into the vector retailer. To do that, we’ll first learn the doc and cut up it into chunks of specified dimension. Beneath is the code to learn the doc, cut up it into chunks and including them to the vector retailer.
file = "path/to/doc/doc.pdf"
loader = PyPDFLoader(file_path=file)
text_splitter = CharacterTextSplitter(
separator="n",
chunk_size=1000,
chunk_overlap=200,
)
pages = loader.load()
chunks = text_splitter.split_documents(pages)
_ = docstore.add_documents(paperwork=chunks)The code reads a doc from its path, splits it into smaller chunks with a 1000 chunk dimension and 200 chunk overlap to keep up context, after which ingests the chunks into the vectorstore. The ‘add_documents’ technique yields a listing of chunk IDs, which customers can make use of to entry, delete, or modify particular chunks.
Question Pipeline Setup
With our vector retailer ready with ingested paperwork, we’ll proceed with the querying pipeline, having imported the mandatory dependencies, and can proceed straight with its implementation.
Step1: Initializing DeepLake Vector Retailer and ChatCohere
First, we’ll initialize the Deeplake vector retailer utilizing the trail the place the vector retailer is saved and initialize the Cohere mannequin occasion.
docstore = DeepLake(
dataset_path="deeplake_vstore",
embedding=embeddings,
verbose=False,
read_only=True,
num_workers=4,
)
llm = ChatCohere(
mannequin="command",
cohere_api_key=API_KEY,
temperature=TEMPERATURE,
)For this experiment we’ll use the ‘command’ mannequin to generate the responses. We additionally must move the Cohere API key into the mannequin param.
Step2: Creating Retriever Object
Utilizing the vector retailer occasion, we have to create the retriever object. This retriever object will probably be used to retrieve context for the LLM to reply the consumer’s queries. Beneath is the code to create the retriever object
utilizing the vector retailer.
retriever = docstore.as_retriever(
search_type="similarity",
search_kwargs={
"fetch_k": 20,
"okay": 10,
}
)The search kind is’similarity’, permitting the retriever to fetch related paperwork utilizing similarity search. The code passes key phrase arguments like fetch_k and okay, the place fetch_k represents the variety of related paperwork and okay represents the highest okay. Moreover, a filter discipline might be added to the search_kwargs parameter for additional filtering.
Step3: Defining Immediate Template and Initializing RetrievalQA Chain
Subsequent, we’ll outline the Immediate Template whereas would be the instruction for the mannequin to generate responses. After which we’ll initialize the RetrievalQA chain utilizing the mannequin occasion, the immediate and few different parameters.
prompt_template = """You might be an clever chatbot that may reply consumer's
queries. You'll be supplied with Related context based mostly on the consumer's queries.
Your process is to research consumer's question and generate response for the question
utiliing the context. Be sure to recommend one related follow-up query based mostly
on the context for the consumer to ask.
NEVER generate response to queries for which there is no such thing as a or irrelevant context.
Context: {context}
Query: {query}
Reply:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"immediate": PROMPT, "verbose": False}
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
)The code snippet outlines the creation of a PromptTemplate object, which takes within the ‘prompt_template’ variable and a listing of keys for inputs. The system is knowledgeable that these keys will probably be handed into the immediate in runtime. The RetrievalQA object is created utilizing the mannequin and retriever, with chain_type set to’stuff’, verbose set to True for debugging, and return_source_documents set to True. This ensures that the response features a record of Doc objects, permitting us to determine the sources used to generate the response.
Step4: Producing a Response to a Question
Now we have all the mandatory parts setup to generate response to consumer question. We are going to take a question and generate response for that.
question = "What had been the fiscal yr summaries for yr 2023 and 2024? How are they comparable?"
response = qa.invoke({"question": question})
consequence = response["result"]The qa (RetrievalQA) object retrieves a response for a question. It takes a dictionary containing the question as enter to the qa.invoke() technique, which requires a while to execute. The response is then saved within the response variable, which permits entry to the response utilizing the “consequence” key and the “source_document” key. For the question response is offered.
The fiscal yr 2024 noticed a major improve in income, reaching $60.9
billion, up 126% from the earlier yr. This was pushed by robust efficiency
within the Knowledge Heart sector, which alone generated $47.5 billion, a staggering
217% progress. Working revenue additionally skilled a considerable enhance, rising to
$32,972 million, in comparison with $4,224 million in 2023. This interprets to an
spectacular 681% progress.
In distinction, fiscal yr 2023 confirmed slower progress, with income remaining
flat at $26.97 billion. Each working and web revenue declined by 58% and
55% respectively in comparison with the earlier yr.
The 2 years are comparable in that they signify consecutive fiscal durations
and showcase the corporate's evolving monetary well being.
A follow-up query might be: What components contributed to the substantial
progress within the Knowledge Heart income in fiscal yr 2024?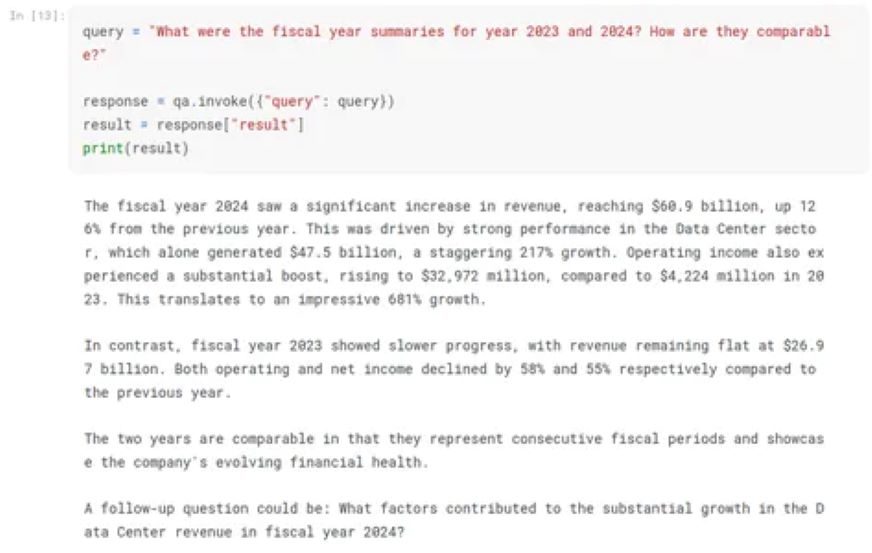
The response that the mannequin gave is appropriate and to the purpose. Now let’s see how the reranker can assist get higher response.
Implementing Cohere’s Reranker Mannequin
Step1: Importing Obligatory Modules
First, we have to import two modules which can be mandatory to make use of reranker retriever in our pipeline.
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerankContextualCompressionRetriever will probably be used as a wrapper across the vector retailer retriever and can assist compress the retrieved paperwork after reranking. CohereRerank is critical to create the reranker object.
Step2: Creating the Reranker Object and Compression Retriever
Now, we have to create the reranker object, then use it within the Retriever compressor.
cohere_rerank = CohereRerank(
cohere_api_key=API_KEY,
mannequin="rerank-english-v3.0",
)
docstore = DeepLake(
dataset_path="deeplake_vstore",
embedding=embeddings,
verbose=False,
read_only=True,
num_workers=4,
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=cohere_rerank,
base_retriever=docstore.as_retriever(
search_type="similarity",
search_kwargs={
"fetch_k": 20,
"okay": 15,
},
),
)The CohereRerank object is created utilizing the Cohere API key and reranker mannequin title, initialized utilizing earlier configurations, and initialized with the Compression Retriever object. The cohere_rerank object is handed and a retriever occasion is created utilizing the vector retailer occasion.
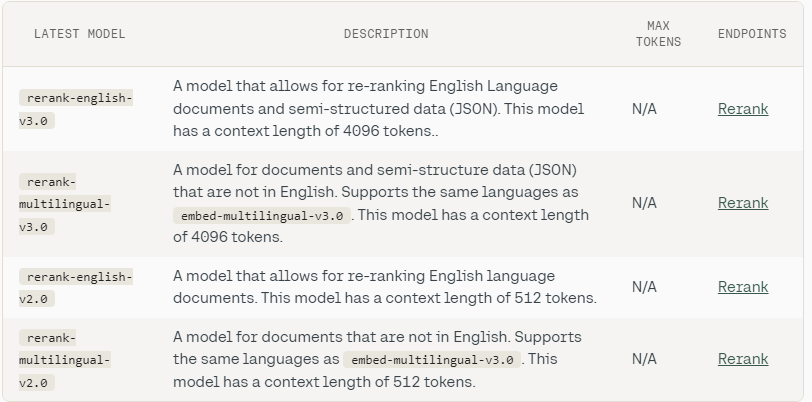
There are few different selections of reranker mannequin, which can be utilized based mostly on the use-case. Right here are the record of different Reranker fashions to selected from.
Step3: Establishing QA (RetrievalQA) Object with the Reranker
Subsequent, we have to setup the qa (RetrievalQA) object with the immediate template, similar to we did for the qa pipeline with out reranker. The one change we want right here is the retriever being changed with compression_retriever.
prompt_template = """You might be an clever chatbot that may reply consumer's
queries. You'll be supplied with Related context based mostly on the consumer's queries.
Your process is to research consumer's question and generate response for the question
utiliing the context. Be sure to recommend one related follow-up query based mostly
on the context for the consumer to ask.
NEVER generate response to queries for which there is no such thing as a or irrelevant context.
Context: {context}
Query: {query}
Reply:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"immediate": PROMPT, "verbose": False}
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
)Step4: Producing a response to a question with the reranker
Lastly, we’ll use the qa object to invoke the LLM on the consumer question.
question = "What had been the fiscal yr summaries for yr 2023 and 2024? How are they comparable?"
response = qa.invoke({"question": question})
consequence = response["result"]After operating the above code, we get the response from LLM. We are able to print the response by printing ‘consequence’. Beneath is the LLM response for the question requested:
The fiscal yr 2023 ended on January 29, 2023, and the fiscal yr 2024 started
on January 30, 2023. The abstract for fiscal yr 2023 exhibits income of $26,974
million with a 56.9% gross margin, whereas fiscal yr 2024's abstract is just not
talked about within the context offered.
The working bills for fiscal yr 2023 noticed an increase of fifty% to succeed in
$11,132 million as a consequence of acquisition termination fees and different operational
prices. Conversely, fiscal yr 2022's working bills had been $7,434 million.
Web revenue and revenue from operations witnessed a downward development in fiscal yr
2023 in comparison with the earlier yr. Fiscal yr 2023 reported web revenue of
$4,368 million and revenue from operations of $4,224 million. In the meantime, fiscal
yr 2022 recorded figures of $9,752 million and $10,041 million,
respectively.
With a change in accounting estimate, the depreciation expense for fiscal yr
2024 is anticipated to lower, thereby rising working revenue by $133
million.
An evaluation of the fiscal yr 2023 and 2024 summaries signifies a distinction in
monetary efficiency, primarily as a result of bills incurred in 2023.
Observe-up query: How did the change in accounting estimate influence the fiscal
yr 2024 monetary abstract, particularly relating to income and working
bills?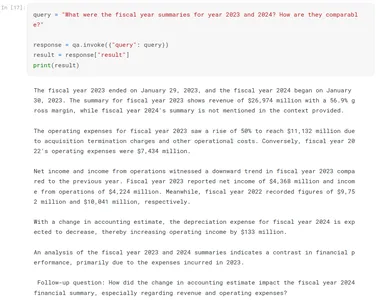
As we will see, the response after utilizing reranker is extra complete and fascinating. We are able to additional customise the response by tuning the immediate based mostly on how we would like the response to be.
Conclusion
The article discusses the applying of Cohere’s re-ranker mannequin in doc re-ranking, highlighting its vital enchancment in accuracy and relevance. The re-ranker mannequin refines info retrieval and contributes to extra informative and contextually acceptable responses, enhancing the general search expertise and reliability of RAG-enabled techniques. The article additionally discusses the modularization of the pipeline to create a doc chatbot with chat reminiscence accessibility and a Streamlit app for seamless interplay with the chatbot. On this we discovered RAG software with cohere command-R and rerank-Half 1.
Key Takeaways
- Cohere command re-ranker mannequin enhances response accuracy by reordering search outcomes based mostly on contextual relevance.
- The article guides readers in implementing Cohere’s re-ranker mannequin for doc re-ranking, bettering search duties.
- Integrating Cohere’s re-ranker mannequin considerably improves the accuracy and relevance of responses within the RAG method.
- Half 2 of the article will deal with modularization and Streamlit app improvement for enhanced consumer interplay.
- The Reranker mannequin improves response accuracy, particularly in situations with numerous content material or related paperwork.
- Cohere’s re-ranker mannequin is suitable with OpenAI’s API, enhancing QnA pipelines.
- Whereas efficient, there could also be slight response inconsistencies, addressable by way of immediate tuning.
Limitations
Whereas the applying works properly, and the responses are quiet correct, there might be few inconsistencies within the responses. However these inconsistencies might be dealt with by tuning the immediate based on desired response. Now we have used Cohere Command-R mannequin for this experiment. The opposite two fashions will also be used if desired.
Regularly Requested Questions
A. In instances the place the vector retailer incorporates contents of many paperwork of comparable sort, the mannequin may generate responses which can be irrelevant with the queries. The reranker mannequin helps to rerank the retrieved paperwork based mostly on the consumer’s question. This helps the mannequin generate correct response.
A. Sure. You need to use the reranker module to wrap the vector retailer retriever object and combine it into the Retrieval QA chain, which makes use of OpenAI’s GPT fashions.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.