
{kind=link}
Convey this undertaking to life
This text will discover the llama manufacturing unit, launched on 21 March 2024, and discover ways to fine-tune Llama 3 utilizing the Paperspace platform. For our process, we are going to use the NVIDIA A4000 GPU, thought-about some of the highly effective single-slot GPUs, enabling seamless integration into varied workstation setups.
Using the NVIDIA Ampere structure, the RTX A4000 integrates 48 second-generation RT Cores, 192 third-generation Tensor Cores, and 6,144 CUDA cores alongside 16GB of graphics reminiscence with error-correction code (ECC); this ensures exact and dependable computing for modern initiatives.
Till just lately, fine-tuning a big language mannequin was a posh process primarily reserved for machine studying and A.I. consultants. Nonetheless, this notion is altering quickly with the ever-evolving area of synthetic intelligence. New instruments like Llama Manufacturing facility are rising, making the fine-tuning course of extra accessible and environment friendly. As well as, one can now use strategies reminiscent of DPO, ORPO, PPO, and SFT for fine-tuning and mannequin optimization. Moreover, now you can effectively practice and fine-tune fashions reminiscent of Llama, Mistral, Falcon, and extra.
What’s mannequin fine-tuning?
Positive-tuning a mannequin entails adjusting the parameters of a pre-trained or base mannequin that can be utilized for a particular process or dataset, enhancing its efficiency and accuracy. This course of entails offering the mannequin with new information and modifying its weights, biases, and sure parameters to reduce loss and value. By doing so, this new mannequin can carry out effectively on any new process or dataset with out ranging from scratch, serving to to avoid wasting time and sources.
Usually, when a brand new giant language mannequin (LLM) is created, it undergoes coaching on a big corpus of textual information, which can embody doubtlessly dangerous or poisonous content material. Following the pre-training or preliminary coaching part, the mannequin is fine-tuned with security measures, guaranteeing it avoids producing dangerous or poisonous responses. Nonetheless, this method may very well be higher. Nonetheless, the idea of fine-tuning addresses the necessity to adapt fashions to particular necessities.
Why use LLama-Manufacturing facility?
Enter the Llama Manufacturing facility, a software that facilitates the environment friendly and cost-effective fine-tuning of over 100 fashions. Llama Manufacturing facility streamlines the method of fine-tuning fashions, making it accessible and user-friendly. It additionally has a hugging face house offered by Hiyouga that can be utilized to fine-tune the mannequin.
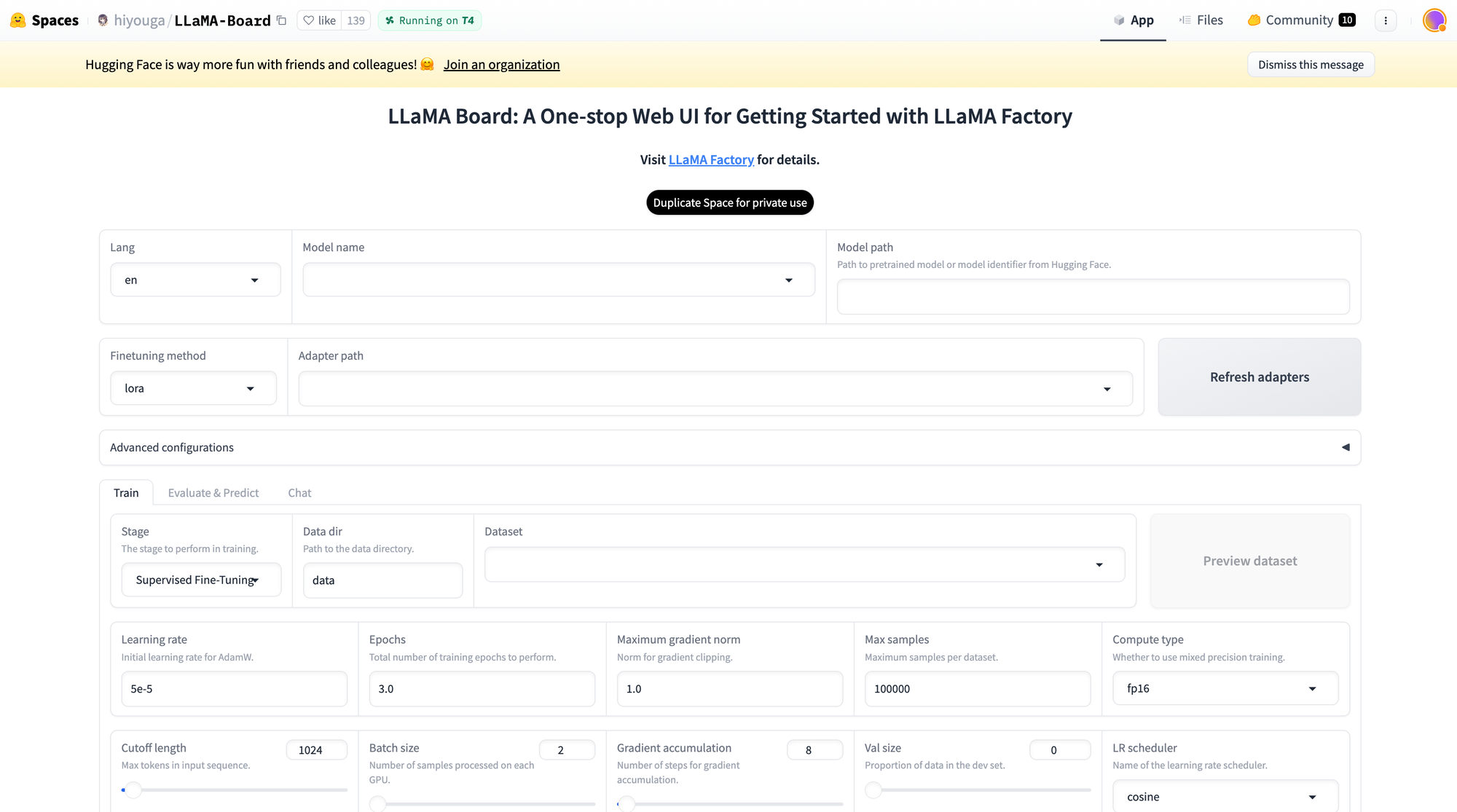
This house additionally helps Lora and GaLore configuration to scale back GPU utilization. With a straightforward slider bar, customers can simply change parameters reminiscent of drop-out, epochs, batch dimension, and so forth. There are additionally a number of dataset choices to select from to fine-tune your mannequin. As mentioned on this article, the Llama Manufacturing facility helps many fashions, together with totally different variations of llama, mistral, and Falcon. It additionally helps superior algorithms like galore, badm, and Lora, providing varied options reminiscent of flash consideration, positional encoding, and scaling.
Moreover, you may combine monitoring instruments like TensorBoard, VanDB, and MLflow. For sooner inference, you may make the most of Gradio and CLI. In essence, the Llama Manufacturing facility offers a various set of choices to reinforce mannequin efficiency and streamline the fine-tuning course of.
LLAMABOARD: A Unified Interface for LLAMAFACTORY
LLAMABOARD is a user-friendly software that helps folks alter and enhance Language Mannequin (LLM) efficiency while not having to know how you can code. It is like a dashboard the place you may simply customise how a language mannequin learns and processes data.
Listed here are some key options:
- Simple Customization: You may change how the mannequin learns by adjusting settings on a webpage. The default settings work effectively for many conditions. You too can see how your information will look to the mannequin earlier than you begin.
- Monitoring Progress: Because the mannequin learns, you may see updates and graphs exhibiting how effectively it is doing. This helps you perceive if it is enhancing or not.
- Versatile Testing: You may examine how effectively the mannequin understands textual content by evaluating it to recognized solutions or by speaking to it your self. This helps you see if the mannequin is getting higher at understanding language.
- Help for Completely different Languages: LLAMABOARD can work in English, Russian, and Chinese language, making it helpful for individuals who converse totally different languages. It is also arrange so as to add extra languages sooner or later.
Positive-tune LLama 3 utilizing Paperspace
Convey this undertaking to life
Let’s log in to the platform, choose the GPU of your selection, and begin the pocket book. You too can click on the hyperlink within the article that will help you begin the pocket book.
- We’ll begin by cloning the repo and putting in the required libraries,
!git clone https://github.com/hiyouga/LLaMA-Manufacturing facility.git
%cd LLaMA-Manufacturing facility
%ls
- Subsequent, we are going to set up unsloth, which permits us to finetune the mannequin effectively. Additional, we are going to set up xformers and bitsandbytes.
# set up needed packages
!pip set up "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip set up --no-deps xformers==0.0.25
!pip set up .[bitsandbytes]
!pip set up 'urllib3<2'- As soon as every thing is put in, we are going to examine the GPU specs,
!nvidia-smi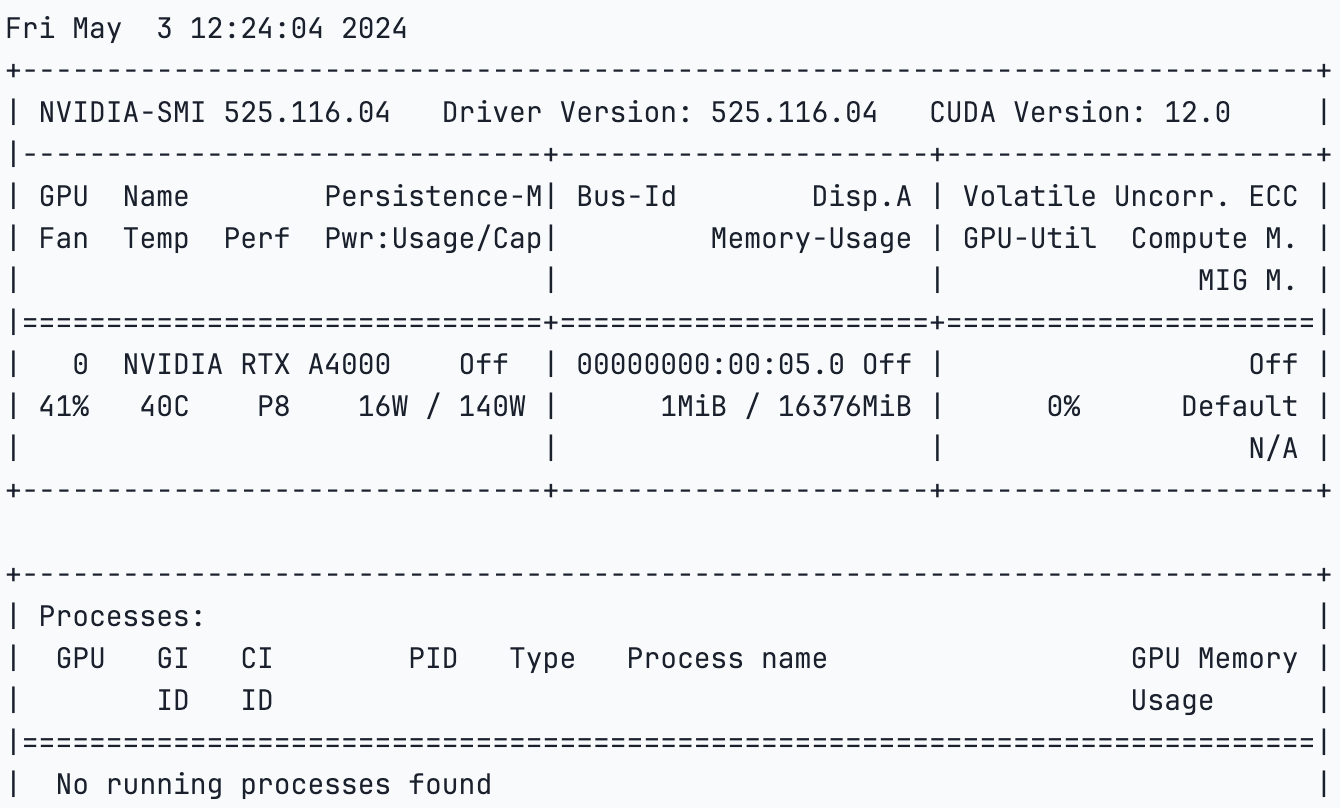
- Subsequent, we are going to import torch and examine our CUDA as a result of we’re utilizing GPU,
import torch
strive:
assert torch.cuda.is_available() is True
besides AssertionError:
print("Your GPU isn't setup!")- We’ll now import the dataset which comes with the GitHub repo that we cloned. We are able to additionally create a customized dataset and use that as a substitute.
import json
%cd /notebooks/LLaMA-Manufacturing facility
MODEL_NAME = "Llama-3"
with open("/notebooks/LLaMA-Manufacturing facility/information/identification.json", "r", encoding="utf-8") as f:
dataset = json.load(f)
for pattern in dataset:
pattern["output"] = pattern["output"].substitute("MODEL_NAME", MODEL_NAME).substitute("AUTHOR", "LLaMA Manufacturing facility")
with open("/notebooks/LLaMA-Manufacturing facility/information/identification.json", "w", encoding="utf-8") as f:
json.dump(dataset, f, indent=2, ensure_ascii=False)- As soon as that is achieved, we are going to execute the code under to generate the Gradio net app hyperlink for Llama Manufacturing facility.
#generates the net app hyperlink
%cd /notebooks/LLaMA-Manufacturing facility
!GRADIO_SHARE=1 llamafactory-cli webuiYou may click on on the generated hyperlink and comply with the directions or use your specs.
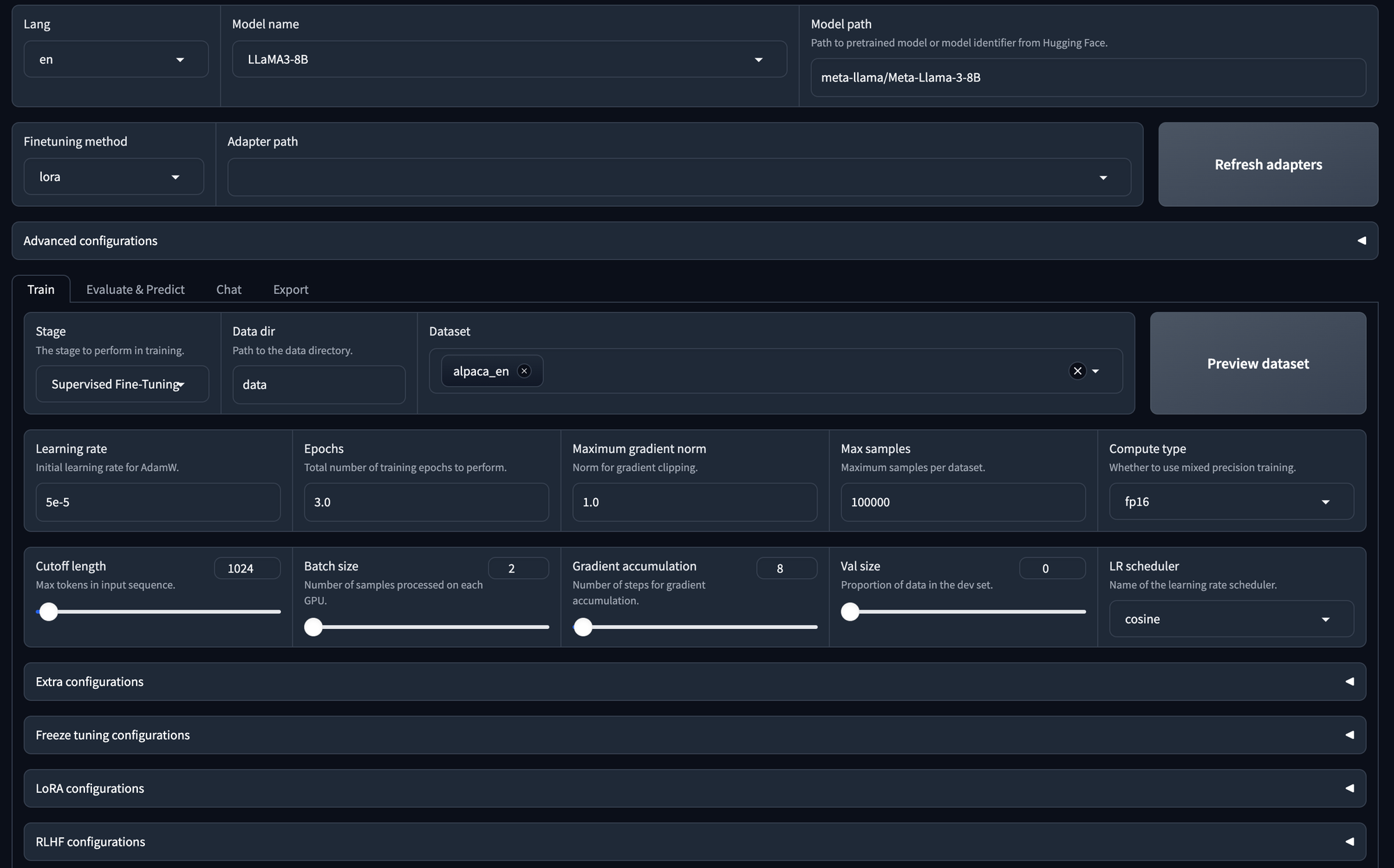
- Mannequin Choice:
- You may select any mannequin; right here, we select Llama 3 with 8 billion parameters.
- Adapter Configuration:
- You could have the choice to specify the adapter path.
- Out there adapters embody LoRa, QLoRa, freeze, or full.
- You may refresh the adapter listing if wanted.
- Coaching Choices:
- You may practice the mannequin utilizing supervised fine-tuning.
- Alternatively, you may go for DPU (Knowledge Processing Unit) or PPU (Parallel Processing Unit) if relevant.
- Knowledge Set Choice:
- The chosen information set is for supervised fine-tuning (SFT).
- You too can select your individual information set.
- Hyperparameter Configuration:
- You may alter hyperparameters, such because the variety of epochs, most gradient norm, and most pattern dimension.
- Laura Configuration:
- Detailed configuration choices can be found for the LoRa mannequin.
- Begin Coaching:
- As soon as all configurations are set, you may provoke the coaching course of by clicking the “Begin” button.
It will begin the coaching.
We can even begin the coaching and fine-tuning utilizing the CLI instructions. You should use the under code to specify the parameters.
args = dict(
stage="sft", # Specifies the stage of coaching. Right here, it is set to "sft" for supervised fine-tuning
do_train=True,
model_name_or_path="unsloth/llama-3-8b-Instruct-bnb-4bit", # use bnb-4bit-quantized Llama-3-8B-Instruct mannequin
dataset="identification,alpaca_gpt4_en", # use the alpaca and identification datasets
template="llama3", # use llama3 for immediate template
finetuning_type="lora", # use the LoRA adapters which saves up reminiscence
lora_target="all", # connect LoRA adapters to all linear layers
output_dir="llama3_lora", # path to avoid wasting LoRA adapters
per_device_train_batch_size=2, # specify the batch dimension
gradient_accumulation_steps=4, # the gradient accumulation steps
lr_scheduler_type="cosine", # use the educational fee as cosine studying fee scheduler
logging_steps=10, # log each 10 steps
warmup_ratio=0.1, # use warmup scheduler
save_steps=1000, # save checkpoint each 1000 steps
learning_rate=5e-5, # the educational fee
num_train_epochs=3.0, # the epochs of coaching
max_samples=500, # use 500 examples in every dataset
max_grad_norm=1.0, # clip gradient norm to 1.0
quantization_bit=4, # use 4-bit QLoRA
loraplus_lr_ratio=16.0, # use LoRA+ with lambda=16.0
use_unsloth=True, # use UnslothAI's LoRA optimization for 2x sooner coaching
fp16=True, # use float16 combined precision coaching
)
json.dump(args, open("train_llama3.json", "w", encoding="utf-8"), indent=2)
Subsequent, open a terminal and run the under command
!llamafactory-cli practice train_llama3.jsonIt will begin the coaching course of.
- As soon as the mannequin coaching is accomplished, we will use the mannequin to deduce from. Allow us to strive doing that and examine how the mannequin works.
args = dict(
model_name_or_path="unsloth/llama-3-8b-Instruct-bnb-4bit", # Specifies the identify or path of the pre-trained mannequin for use for inference. On this case, it is set to "unsloth/llama-3-8b-Instruct-bnb-4bit".
#adapter_name_or_path="llama3_lora", # load the saved LoRA adapters
finetuning_type="lora", # Specifies the kind of fine-tuning. Right here, it is set to "lora" for LoRA adapters.
template="llama3", # Specifies the immediate template for use for inference. Right here, it is set to "llama3"
quantization_bit=4, # Specifies the variety of bits for quantization. On this case, it is set to 4
use_unsloth=True, # use UnslothAI's LoRA optimization for 2x sooner technology
)
json.dump(args, open("infer_llama3.json", "w", encoding="utf-8"), indent=2)
Right here, we outline our mannequin with the saved adapter, choose chat templates, and specify user-assistant interactions.
Subsequent, run the under code utilizing your terminal,
!llamafactory-cli chat infer_llama3.jsonWe suggest our customers to strive Llama-Manufacturing facility with any mannequin and experiment with the parameters.
Conclusion
Efficient fine-tuning has grow to be one of many necessity for giant language fashions (LLMs) to adapt itself for particular duties. Nonetheless, it requires some quantity of effort and is sort of difficult generally. With the introduction to LLama-Manufacturing facility, a complete framework that consolidates superior environment friendly coaching strategies customers can simply customise fine-tuning for over 100 LLMs with out coding necessities.
Many individuals at the moment are extra interested in giant language fashions (LLMs) will are inclined to get drawn to LLama-Manufacturing facility to see if they’ll alter their very own fashions. This helps the open-source group develop and grow to be extra lively. LLama-Manufacturing facility is changing into well-known and has even been highlighted in Superior Transformers3 as a number one software for fine-tuning LLMs effectively.
We hope that this text encourages extra builders to make use of this framework to create LLMs that may profit society. Keep in mind, it is essential to comply with the principles of the mannequin’s license when utilizing LLama-Manufacturing facility to fine-tune LLMs to stop any potential misuse.
With this we come to an finish of this text, we noticed how simple it’s these days to fine-tune any mannequin inside minutes. We are able to additionally use hugging face CLI to push this mannequin to hugging face hub.