
{kind=link}
Deliver this venture to life
The promise of Massive Language Mannequin’s is changing into more and more extra obvious, and their use an increasing number of prevalent, because the expertise continues to enhance. With the discharge of LLaMA 3, we’re lastly beginning to see Open Supply language fashions getting fairly shut in high quality to the walled backyard releases which have dominated the scene for the reason that launch of ChatGPT.
One of many extra attractive use circumstances for these fashions is as a writing support. Whereas even the perfect LLMs are topic to hallucinations and assured misunderstandings, the utility of with the ability to quickly generate writing materials on any well-known matter is beneficial for a large number of causes. Because the scope of those LLM fashions coaching knowledge will increase in robustness and measurement, this potential solely grows.
The most recent and most fun functions that reap the benefits of this potential is Stanford OVAL’s STORM pipeline. STORM (Synthesis of Subject Outlines by means of Retrieval and Multi-perspective Query Asking) fashions enact a pre-writing stage utilizing a group of numerous skilled brokers that simulate conversations in regards to the matter with each other, after which combine the collated info into an overview that holistically considers the brokers perspective. This enables STORM to then use the define to generate a full Wikipedia-like article from scratch on practically any matter. STORM impressively outperforms Retrieval Augmented Technology primarily based article turbines when it comes to group and protection of the fabric.
On this article, we’re going to present how you can use STORM with VLLM hosted HuggingFace fashions to generate articles utilizing Paperspace Notebooks. Comply with alongside to get a brief overview of how STORM works earlier than leaping into the coding demo. Use the hyperlink on the prime of the web page to immediately launch this demo in a Paperspace Pocket book.
What does STORM do?
STORM is a pipeline which makes use of a sequence of LLM brokers with the Wikipedia and You.com search APIs to generate Wikipedia like articles on any topic, in prime quality. To attain this, the pipeline first searches Wikipedia for pertinent articles associated to a submitted matter and extracts their desk of contents to generate a novel define on the subject. The data from these is then used to arrange a sequence of subject-master, conversational brokers to shortly prime an knowledgeable Wikipedia author. The knowledgeable author then writes the article utilizing the define as a scaffold.
How does STORM work?
To start out, STORM makes use of the you.com search API to entry the Wikipedia articles for the LLM. To get began with STORM, be sure you setup your API key and add it to secrets and techniques.toml within the Pocket book. For the LLM author brokers, we’re going to leverage VLLM to run fashions downloaded to the cache from HuggingFace.co. Particularly, we’re going to be utilizing Mistral’s Mistral-7B-Instruct-v0.2.

From the STORM article, here’s a high-level overview of various approaches to the problem of producing Wikipedia-like articles. To do that, most approaches use a method referred to as pre-writing. That is the invention stage the place the LLM will get parses by means of materials for the subject collectively from separate sources.
The primary they thought of might be probably the most direct and apparent: an LLM agent generates a considerable amount of questions and queries the mannequin with every. They’re then recorded and ordered by the agent with subheaders to create the define.
The second methodology they talked about is Perspective-Guided Query Asking. This course of includes the mannequin first discovering numerous views thorugh evaluation of various, however related, Wiipedia articles. The LLM is then personified by these views, which permits for a extra correct formation of the direct prompting questions that may generate the article define.
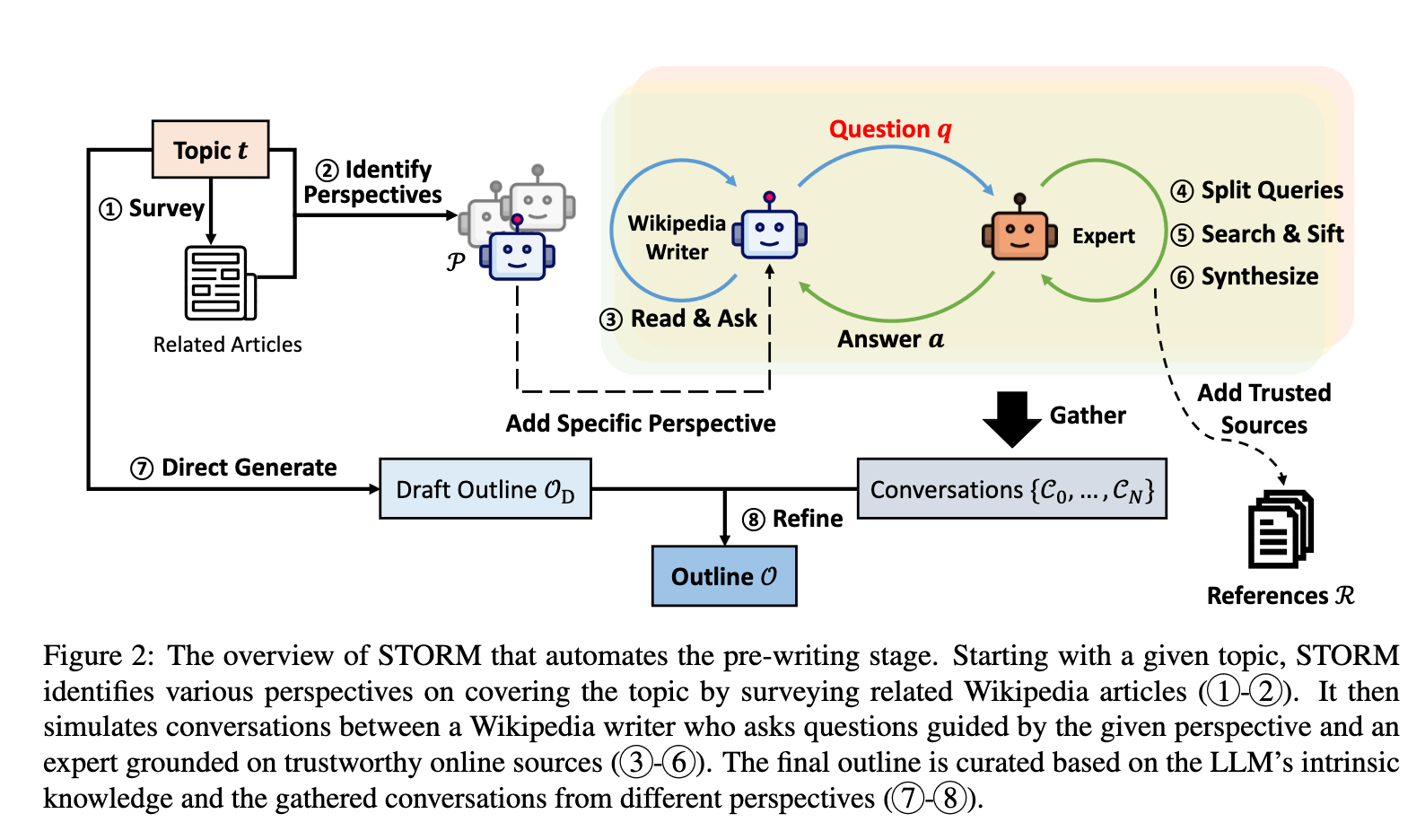
The third methodology is the one developed for the STORM launch: Conversational Query Asking. This methodology includes an augmented type of Perspective-Guided Query Asking. The pipeline surveys “prompts an LLM to generate an inventory of associated matters and subsequently extracts the tables of contents from their corresponding Wikipedia articles, if such articles might be obtained by means of Wikipedia API” (Supply). The articles are then used to every present a set variety of views to converse with the subject skilled as Wikipedia author agent. For every perspective, the Wikipedia author and the subject skilled simulate a dialog. After a set variety of interactions, a topic-relevant query is generated with the context of the angle and dialog historical past. The query is damaged down into uncomplicated search phrases, and the search outcomes are used to exclude untrustworthy sources from being thought of. The reliable search outcomes are then synthesized collectively to generate the ultimate reply to the query. The ultimate question-answer interplay is then collated in a reference information for the LLM to reference through the writing stage. The ultimate define makes use of the intrinsic information to piece collectively the gathered information from the references into a top quality article.
After the pre-writing stage is accomplished and earlier than writing, the LLM is first prompted to generate a generic define for the article from the subject. This generic define is then used together with the enter matter once more and the simulated conversations to generate an improved define from the unique. That is then used throughout writing to information the Wikipedia author. The article is generated piece by piece from every part of the define. The ultimate outputs are concatenated to generate the total article.
Run STORM on Paperspace
Deliver this venture to life
To run STORM on Paperspace, there are a pair issues we have to deal with first. To start out, it’s endorsed that now we have a Professional or Progress account to reap the benefits of working the GPUs for under the price of the membership.
To really run the demo, we’re going to want to enroll in the You.com leverage the Internet+Information Search API. Use the hyperlink to enroll in the free trial, and get your API key. Save the important thing for later.
As soon as now we have taken care of that preparation, we will spin up our Pocket book. We suggest the Free-A6000 or Free-A100-80G GPUs for working STORM, in order that we will get our leads to an inexpensive time-frame and keep away from out of reminiscence errors. You need to use the Run on Paperspace hyperlink to do all of the setup immediately and run it on an A100-80G, or use the unique Github repo because the workspace URL throughout Pocket book creation.
As soon as your Pocket book has spun up, open up STORM.ipynb to proceed with the demo.
Organising the demo
Demo setup may be very simple. We have to set up VLLM and the necessities for STORM to get began. Run the primary code cell, or paste this right into a corresponding terminal with out the exclamation marks at the beginning of every line.
!git pull
!pip set up -r necessities.txt
!pip set up -U huggingface-hub anthropic
!pip uninstall jax jaxlib tensorflow -y
!pip set up vllm==0.2.7This course of might take a second. As soon as it’s completed, run the next code cell to log in to HuggingFace.co to get your API entry tokens. The token might be entry or created utilizing the hyperlink given to you by the output. Merely copy and paste it into the cell supplied within the output so as to add your token.
import huggingface_hub
huggingface_hub.notebook_login()With that full, we can have entry to any HuggingFace mannequin we need to use. We will change this by modifying the mannequin id within the run_storm_wiki_mistral.py file on line 35 within the mistral_kwargs variable, and in addition altering the mannequin ID we name for the VLLM shopper.
Working the VLLM Shopper
To run STORM, the python script depends on API calls to enter and obtain outputs from the LLM. By default, this was set to make use of OpenAI. Previously few days, they’ve added performance to allow DSPY VLLM endpoints to work with the script.
To set this up, all we have to do is run the following code cell. This can launch Mistral as an interactive API endpoint that we will instantly chat with.
!python -m vllm.entrypoints.openai.api_server --port 6006 --model 'mistralai/Mistral-7B-Instruct-v0.2'As soon as the API has launched, we will run STORM. Use the following part to see how you can configure it.
Working STORM
Now that the whole lot is ready up, all that’s left for us to do is run STORM. For this demo, we’re going to use their instance run_storm_wiki_mistral.py. Paste the next command right into a terminal window.
python examples/run_storm_wiki_mistral.py
--url "http://localhost"
--port 6006
--output-dir '/notebooks/outcomes/'
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleFrom right here, you’ll be requested to enter a subject of your alternative. That is going to be the topic of our new article. We examined ours with the inputted matter “NVIDIA GPUs”. You’ll be able to learn a pattern part from our generated article beneath. As we will see, the formatting mimics that of Wikipedia articles completely. This matter is probably going one which was not closely coated within the authentic mannequin coaching, contemplating the ironic nicheness of the subject material, so we will assume that the right info offered within the generated textual content was all ascertained by means of the STORM analysis process. Let’s have a look.
## Ampere Structure (2020)
Ampere is the newer of the 2 architectures and is employed within the newest technology of NVIDIA graphics playing cards, together with the RTX 30 Sequence [6]. It affords as much as 1.9X Efficiency per Watt enchancment over the Turing structure [6]. One other welcome boost to the Ampere is the help for HDMI 2.1, which helps ultra-high decision and refresh charges of 8K@60Hz and 4K@120Hz [6].
Each Turing and Ampere architectures share some similarities. They're employed within the newest technology of NVIDIA graphics playing cards, with Turing serving the RTX 20 Sequence and Ampere serving the RTX 30 Sequence [6]. Nonetheless, Ampere comes with some newer options and enhancements over the Turing GPU structure [6].
[6] The Ampere structure affords as much as 1.9X Efficiency per Watt enchancment over the Turing structure. One other welcome boost to the Ampere is the help for HDMI 2.1 which helps the ultra-high decision and refresh charges that are 8K@60Hz and 4K@120Hz.
[7] Search for new functions constructed from scratch on GPUs reasonably than porting of present giant simulation functions.
[8] In 2007, NVIDIA’s CUDA powered a brand new line of NVIDIA GPUs that introduced accelerated computing to an increasing array of commercial and scientific functions.
[1] Opens parallel processing capabilities of GPUs to science and analysis with the disclosing of CUDA® structure.
[9] RAPIDS, constructed on NVIDIA CUDA-X AI, leverages greater than 15 years of NVIDIA® CUDA® growth and machine studying experience.
[10] Modeling and simulation, the convergence of HPC and AI, and visualization are relevant in a variety of industries, from scientific analysis to monetary modeling.
[11] PhysX is already built-in into among the hottest sport engines, together with Unreal Engine (variations 3 and 4), Unity3D, and Stingray.
[12] NVIDIA Omniverse™ is an extensible, open platform constructed for digital collaboration and real-time bodily correct simulation.As we will see, this can be a fairly spectacular distillation of the accessible info. Whereas there are some smaller errors concerning the specifics of this extremely advanced and technical topic, the pipeline nonetheless was practically fully correct with its generated textual content with regard to the fact of the topic.
Closing ideas
The functions for STORM we displayed on this article are really astounding. There’s a lot potential for supercharging instructional and dry content material creation processes by means of functions of LLMs reminiscent of this. We can not wait to see how this evolves even additional because the related applied sciences enhance.