
{kind=link}
Trendy software program functions are underpinned by a big and rising net of APIs, microservices, and cloud companies that have to be extremely out there, fault tolerant, and safe. The underlying networking expertise should assist all of those necessities, after all, but in addition explosive progress.
Sadly, the earlier era of applied sciences are too costly, brittle, and poorly built-in to adequately clear up this problem. Mixed with non-optimal organizational practices, regulatory compliance necessities, and the necessity to ship software program quicker, a brand new era of expertise is required to handle these API, networking, and safety challenges.
CAKES is an open-source software networking stack constructed to combine and higher clear up these challenges. This stack is meant to be coupled with fashionable practices like GitOps, declarative configuration, and platform engineering. CAKES is constructed on the next open-source applied sciences:
- C – CNI (container community interface) / Cilium, Calico
- A – Ambient Mesh / Istio
- Ok – Kubernetes
- E – Envoy / API gateway
- S – SPIFFE / SPIRE
On this article, we discover why we want CAKES and the way these applied sciences match collectively in a contemporary cloud setting, with a give attention to rushing up supply, lowering prices, and enhancing compliance.
Why CAKES?
Current expertise and group constructions are impediments to fixing the issues that come up with the explosion in APIs, the necessity for iteration, and an elevated velocity of supply. Greatest-of-breed applied sciences that combine nicely with one another, which are primarily based on fashionable cloud ideas, and which have been confirmed at scale are higher outfitted to deal with the challenges we see.
Conway’s regulation strikes once more
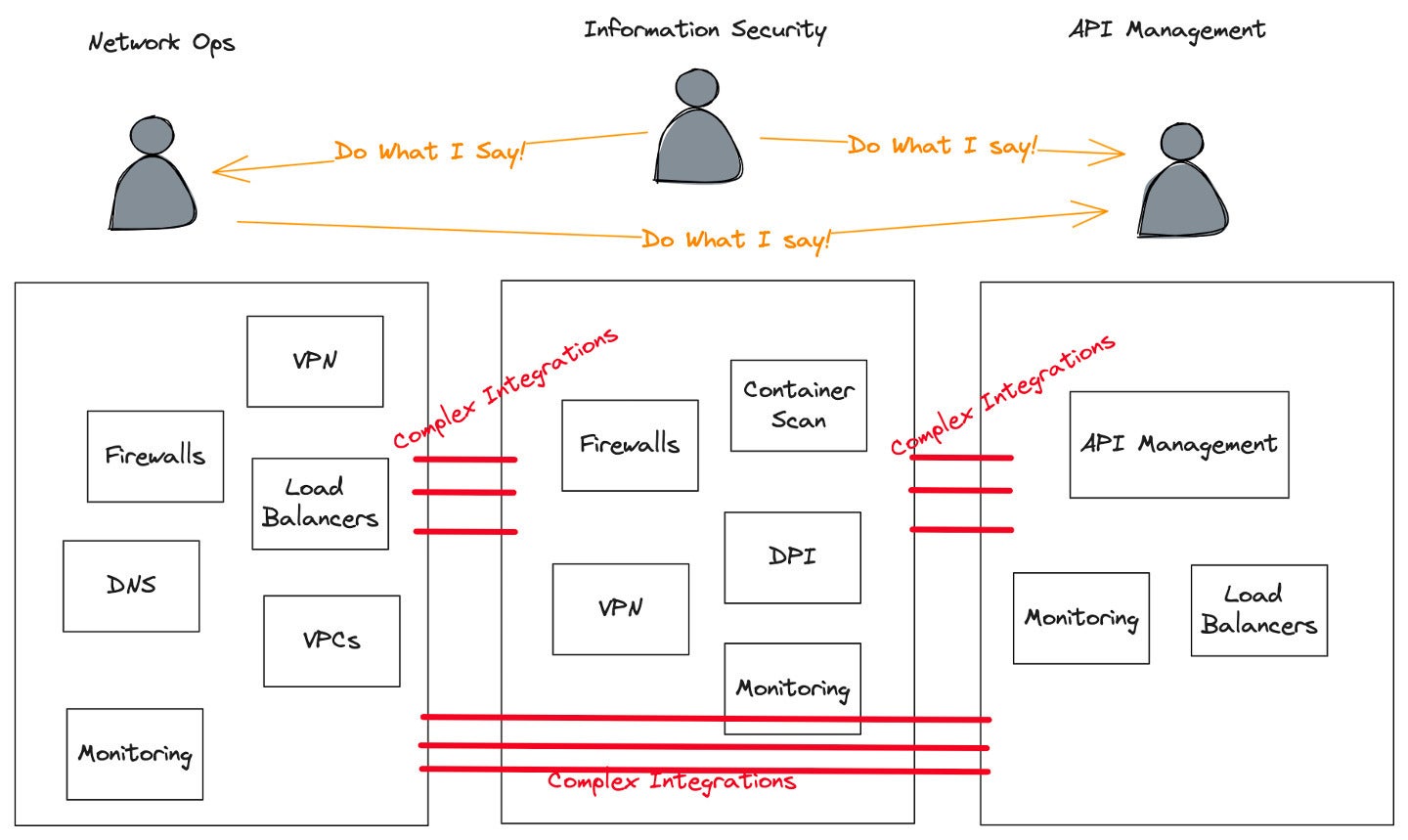
A serious problem in enterprises immediately is maintaining with the networking wants of recent architectures whereas additionally protecting current expertise investments operating easily. Massive organizations have a number of IT groups answerable for these wants, however at occasions, the knowledge sharing and communication between these groups is lower than supreme. These answerable for connectivity, safety, and compliance sometimes reside throughout networking operations, data safety, platform/cloud infrastructure, and/or API administration. These groups typically make choices in silos, which causes duplication and integration friction with different components of the group. Oftentimes, “integration” between these groups is thru ticketing techniques.
For instance, a networking operations staff typically oversees expertise for connectivity, DNS, subnets, micro-segmentation, load balancing, firewall home equipment, monitoring/alerting, and extra. An data safety staff is normally concerned in coverage for compliance and audit, managing net app firewalls (WAF), penetration testing, container scanning, deep packet inspection, and so forth. An API administration staff takes care of onboarding, securing, cataloging, and publishing APIs.
If every of those groups independently picks the expertise for his or her silo, then integration and automation shall be gradual, brittle, and costly. Adjustments to coverage, routing, and safety will reveal cracks in compliance. Groups could turn out to be confused about which expertise to make use of, as inevitably there shall be overlap. Lead occasions for modifications in assist of app developer productiveness will get longer and longer. Briefly, Conway’s regulation, which states that an organizational system typically finish ups just like the communication construction of that group, rears its ugly head.
 Solo.io
Solo.ioDetermine 1. Expertise silos result in fragmented expertise decisions, costly and brittle integrations, and overlap
Sub-optimal organizational practices
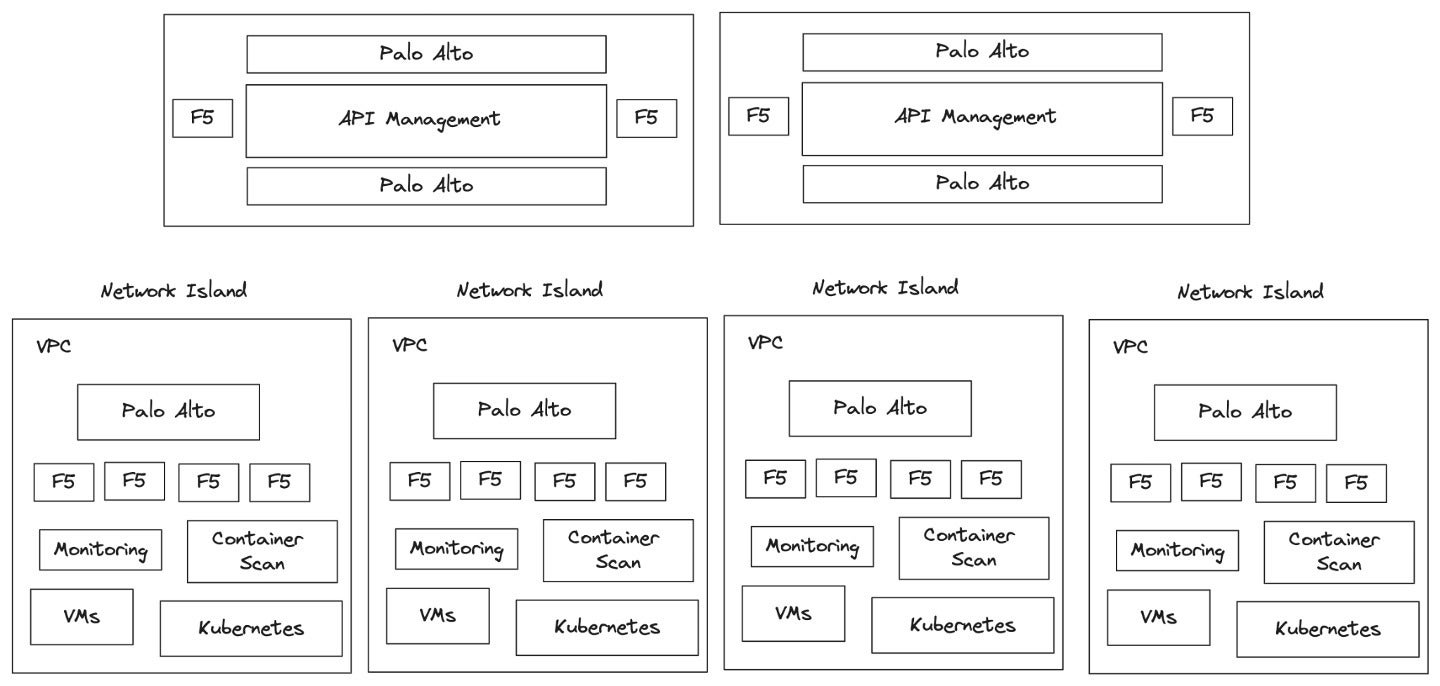
Conway’s regulation isn’t the one concern right here. Organizational practices on this space might be sub-optimal. Implementations on a use-case-by-use-case foundation lead to many remoted “community islands” inside a company as a result of that’s how issues “have at all times been achieved.”
For instance, a brand new line of enterprise spins up, which is able to present companies to different components of the enterprise and devour companies from different components. The modus operandi is to create a brand new VPC (digital non-public cloud), set up new F5 load balancers, new Palo Alto firewalls, create a brand new staff to configure and handle it, and many others. Doing this use case by use case causes a proliferation of those community islands, that are tough to combine and handle.
As time goes on, every staff solves challenges of their environments independently. Little by little, these community islands begin to transfer away from one another. For instance, we at Solo.io have labored with massive monetary establishments the place it’s widespread to seek out dozens if not lots of of those drifting community islands. Organizational safety and compliance necessities turn out to be very tough to maintain constant and auditable in an setting like that.
 Solo.io
Solo.ioDetermine 2. Current practices result in costly duplication and complexity.
Outdated networking assumptions and controls
Lastly, the assumptions we’ve made about perimeter community safety and the controls we use to implement safety coverage and community coverage are not legitimate. We’ve historically assigned numerous belief to the community perimeter and “the place” companies are deployed inside community islands or community segments. The “perimeter” deteriorates as we punch extra holes within the firewall, use extra cloud companies, and deploy extra APIs and microservices on premises and in public clouds (or in a number of public clouds as demanded by laws). As soon as a malicious actor makes it previous the perimeter, they’ve lateral entry to different techniques and may get entry to delicate knowledge. Safety and compliance insurance policies are sometimes primarily based on IP addresses and community segments, that are ephemeral and might be reassigned. With fast modifications within the infrastructure, “coverage bit rot” occurs rapidly and unpredictably.
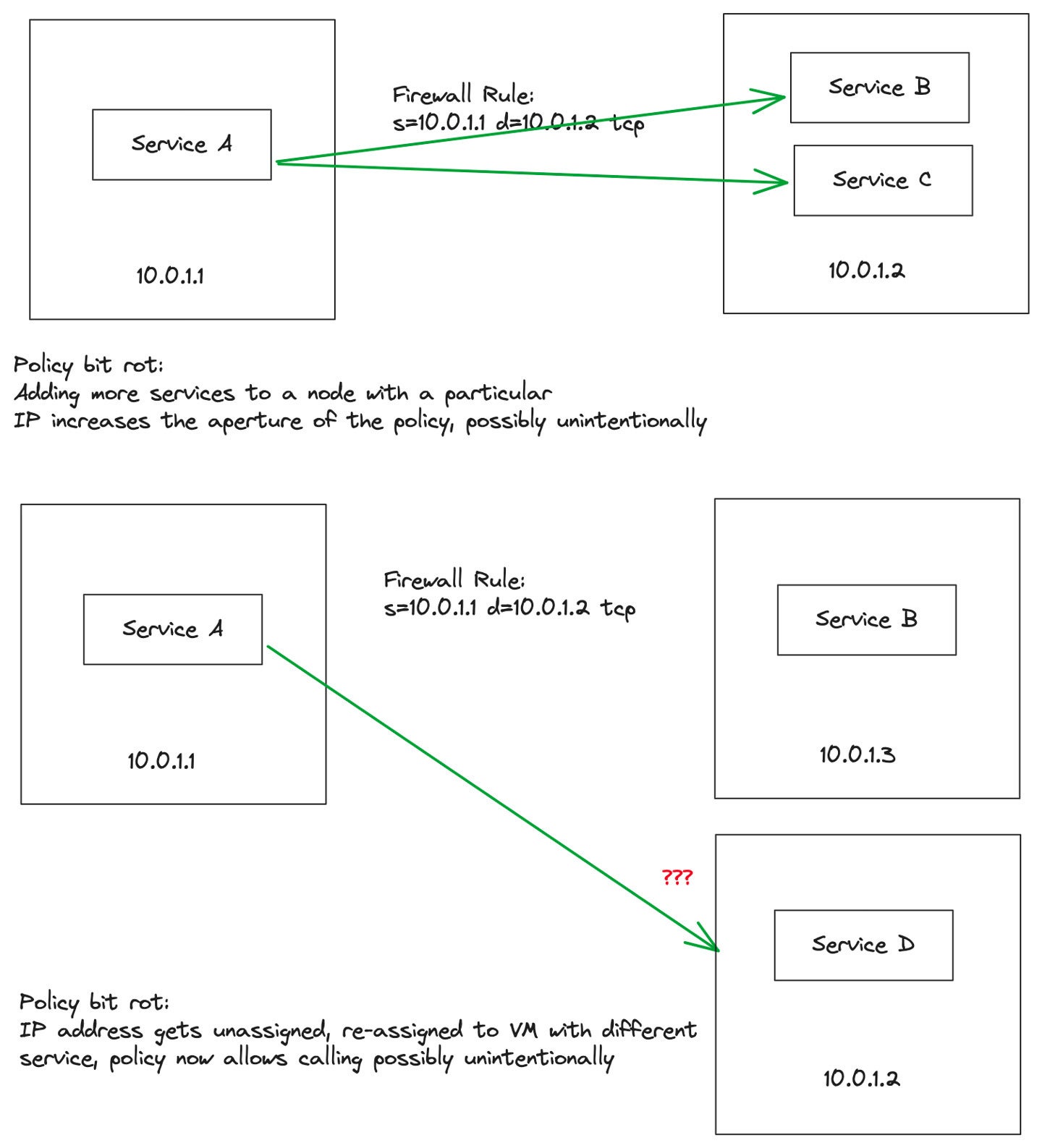
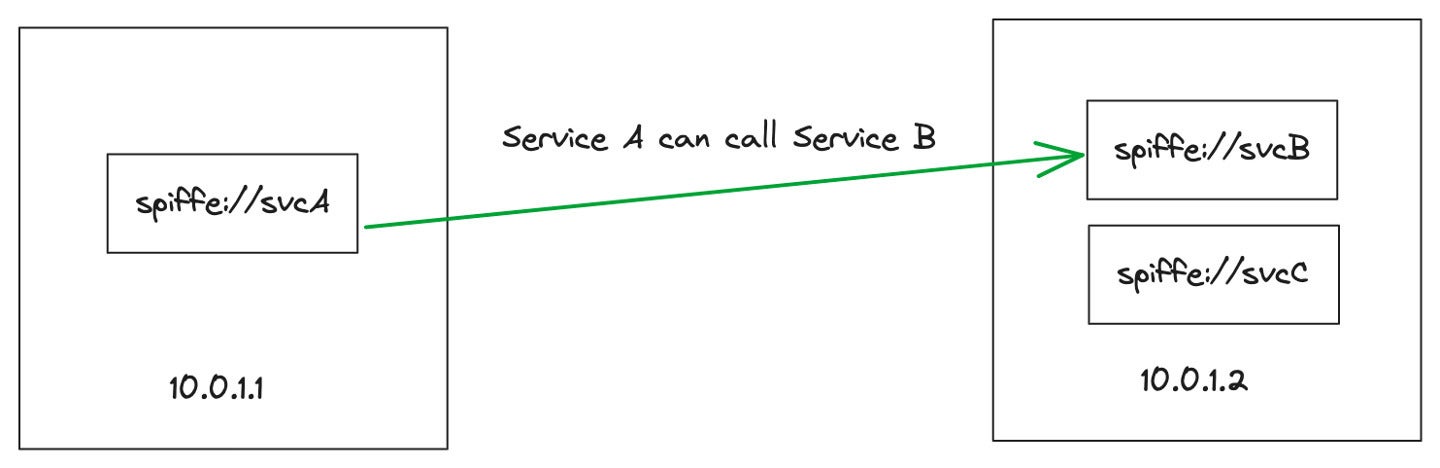
Coverage bit rot occurs once we intend to implement a coverage, however due to a change in complicated infrastructure and IP-based networking guidelines, the coverage turns into skewed or invalid. Let’s take a easy instance of service A operating on VM 1 with IP deal with 10.0.1.1 and repair B operating on VM 2 with IP deal with 10.0.1.2. We are able to write a coverage that claims “service A ought to be capable of speak to service B” and implement that as firewall guidelines permitting 10.0.1.1 to speak to 10.0.1.2.
 Solo.io
Solo.ioDetermine 3. Service A calling Service B on two completely different VMs with IP-based coverage.
Two easy issues may occur right here to rot our coverage. First, a brand new Service C may very well be deployed to VM 2. The consequence, which will not be meant, is that now service A can name service C. Second, VM 2 may turn out to be unhealthy and recycled with a brand new IP deal with. The outdated IP deal with may very well be re-assigned to a VM 3 with Service D. Now service A can name service D however doubtlessly not service B.
 Solo.io
Solo.ioDetermine 4. Coverage bit rot can occur rapidly and go undetected when counting on ephemeral networking controls.
The earlier instance is for a quite simple use case, however when you prolong this to lots of of VMs with lots of if not hundreds of complicated firewall guidelines, you possibly can see how modifications to environments like this may get skewed. When coverage bit rot occurs, it’s very obscure what the present coverage is until one thing breaks. However simply because site visitors isn’t breaking proper now doesn’t imply that the coverage posture hasn’t turn out to be susceptible.
Conway’s regulation, complicated infrastructure, and outdated networking assumptions make for a pricey quagmire that slows the velocity of supply. Making modifications in these environments results in unpredictable safety and coverage impacts, makes auditing tough, and undermines fashionable cloud practices and automation. For these causes, we want a contemporary, holistic strategy to software networking.
A greater strategy to software networking
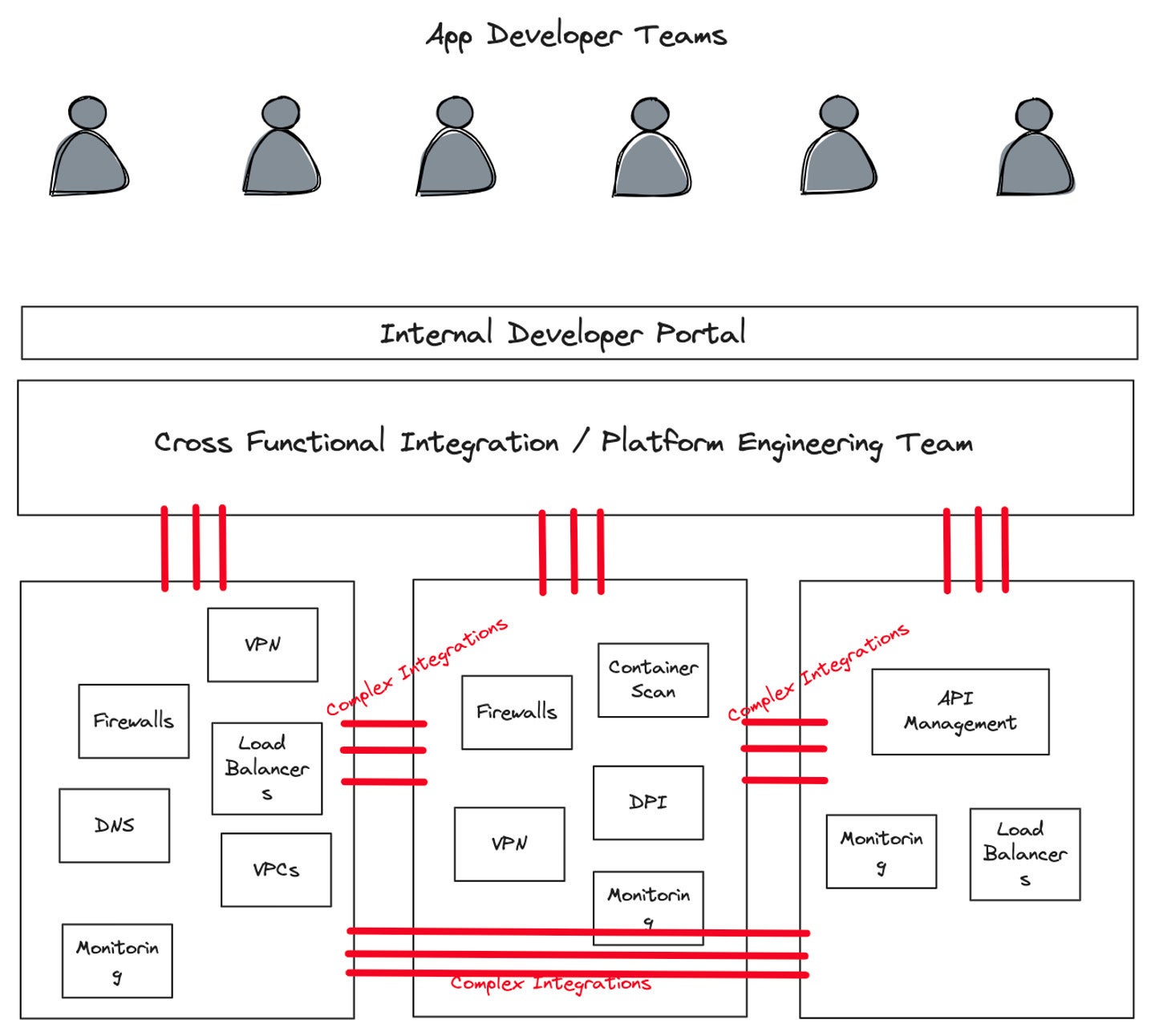
Expertise alone gained’t clear up a few of the organizational challenges mentioned above. Extra just lately, the practices which have shaped round platform engineering seem to provide us a path ahead. Organizations that put money into platform engineering groups to automate and summary away the complexity round networking, safety, and compliance allow their software groups to go quicker.
Platform engineering groups tackle the heavy lifting round integration and honing in on the best consumer expertise for the group’s builders. By centralizing widespread practices, taking a holistic view of a company’s networking, and utilizing workflows primarily based on GitOps to drive supply, a platform engineering staff can get the advantages of greatest practices, reuse, and economic system of scale. This improves agility, reduces prices, and permits app groups to give attention to delivering new worth to the enterprise.
 Solo.io
Solo.ioDetermine 5. A platform engineering staff abstracts away infrastructure complexity and presents a developer expertise to software developer groups by way of an inner developer portal.
For a platform engineering staff to achieve success, we have to give them instruments which are higher outfitted to reside on this fashionable, cloud-native world. When fascinated about networking, safety, and compliance, we ought to be pondering when it comes to roles, obligations, and coverage that may be mapped on to the group.
We must always keep away from counting on “the place” issues are deployed, what IP addresses are getting used, and what micro-segmentation or firewall guidelines exist. We must always be capable of rapidly have a look at our “meant” posture and simply examine it to current deployment or coverage. It will make auditing less complicated and compliance simpler to make sure. How can we obtain it? We want three easy however highly effective foundational ideas in our instruments:
- Declarative configuration
- Workload identification
- Customary integration factors
Declarative configuration
Intent and present state are sometimes muddied by complexities of a company’s infrastructure. Attempting to wade by way of hundreds of traces of firewall guidelines primarily based on IP addresses and community segmentation and perceive intent might be practically not possible. Declarative configuration codecs assist clear up this.
As a substitute of hundreds of crucial steps to attain a desired posture, declarative configuration permits us to very clearly state what the intent or the tip state of the system ought to be. We are able to have a look at the reside state of a system and examine it with its meant state rather more simply with declarative configuration than making an attempt to reverse engineer by way of complicated steps and guidelines. If the infrastructure modifications we will “recompile” the declarative coverage to this new goal, which permits for agility.
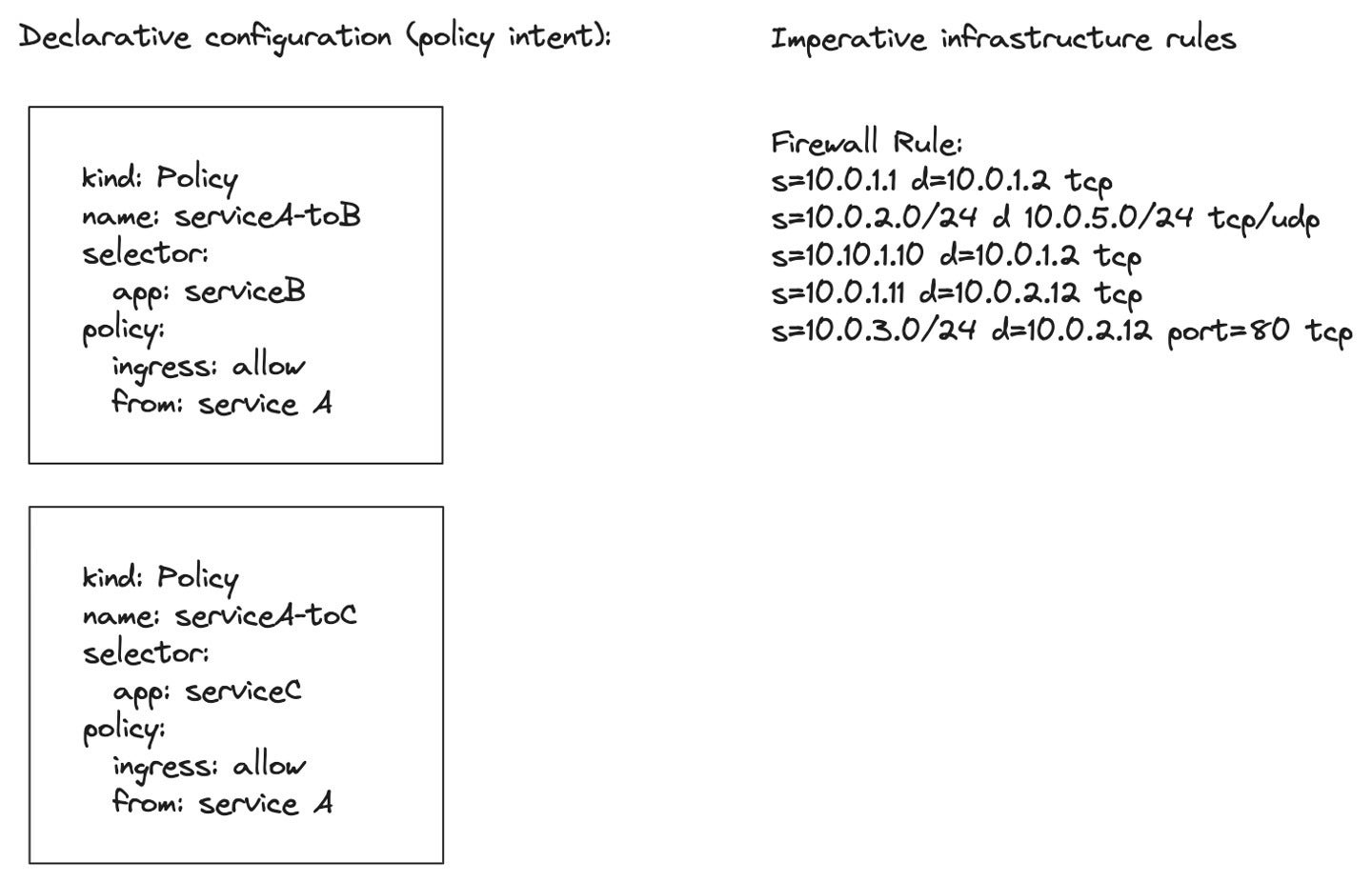 Solo.io
Solo.ioDetermine 6. Declare what, not how.
Writing community coverage as declarative configuration isn’t sufficient, nevertheless. We’ve seen massive organizations construct good declarative configuration fashions, however the complexity of their infrastructure nonetheless results in complicated guidelines and brittle automation. Declarative configuration ought to be written when it comes to sturdy workload identification that’s tied to companies mapped to group construction. This workload identification is unbiased of the infrastructure, IP addresses, or micro-segmentation. Workload identification helps scale back coverage bit rot, reduces configuration drift, and makes it simpler to purpose in regards to the meant state of the system and the precise state.
Workload identification
Earlier strategies of constructing coverage primarily based on “the place” workloads are deployed are too prone to “coverage bit rot.” Constructs like IP addresses and community segments usually are not sturdy, that’s, they’re ephemeral and might be modified, reassigned, or usually are not even related. Adjustments to those constructs can nullify meant coverage. We have to establish workloads primarily based on what they’re, how they map inside the organizational construction, and accomplish that independently of the place they’re deployed. This decoupling permits meant coverage to withstand drift when the infrastructure modifications, is deployed over hybrid environments, or experiences faults/failures.
 Solo.io
Solo.ioDetermine 7. Sturdy workload identification ought to be assigned to workloads at startup. Insurance policies ought to be written when it comes to sturdy identification no matter the place workloads are deployed.
With a extra sturdy workload identification, we will write authentication and authorization insurance policies with declarative configuration which are simpler to audit and that map clearly to compliance necessities. A high-level compliance requirement comparable to “take a look at and developer environments can not work together with manufacturing environments or knowledge” turns into simpler to implement. With workload identification, we all know which workloads belong to which environments as a result of it’s encoded of their workload identification.
Most organizations have already got current investments in identification and entry administration techniques, so the final piece of the puzzle right here is the necessity for traditional integration factors.
Customary integration factors
An enormous ache level in current networking and safety implementations is the costly integrations between techniques that weren’t meant to work nicely collectively or that expose proprietary integration factors. A few of these integrations are closely UI-based, that are tough to automate. Any system constructed on declarative configuration and robust workload identification may also have to combine with different layers within the stack or supporting expertise.