Introduction
On this article, we are going to discover what’s speculation testing, specializing in the formulation of null and different hypotheses, establishing speculation exams and we are going to deep dive into parametric and non-parametric exams, discussing their respective assumptions and implementation in python. However our predominant focus will likely be on non-parametric exams just like the Mann-Whitney U check and the Kruskal-Wallis check. By the top, you’ll have a complete understanding of speculation testing and the sensible instruments to use these ideas in your individual statistical analyses.
Studying Targets
- Perceive the ideas of speculation testing, together with the formulation of null and different hypotheses.
- Establishing Speculation Check.
- Understanding about Parametric Check and its sorts.
- Understanding about Non Parametric Check and its sorts together with its implementations.
- Distinction between Parametric and Non Parametric.
What’s Speculation Testing ?
Speculation is a declare made by an individual /group. The declare is normally about inhabitants parameters akin to imply or proportion and we search proof from a pattern for the assist of the declare.
Speculation testing, generally known as significance testing, is a technique for confirming a declare or speculation a couple of parameter in a inhabitants utilizing knowledge measured in a pattern. Utilizing this technique, we discover a number of theories by figuring out the potentiality that, had the inhabitants parameter speculation been true, a pattern statistic might need been chosen.
Speculation testing entails formulation of two hypotheses:
- Null speculation (H0)
- Various speculation (H1)
Null speculation : It’s normally a speculation of no distinction and normally denoted by H0. In keeping with R.A Fisher , null speculation is the speculation which is examined for potential rejection beneath the belief that it’s true (Ref Fundamentals of Mathematical Statistics).
Various speculation: Any speculation which is complementary to the null speculation is known as an alternate speculation, normally denoted by H1.
The target of speculation testing is to both reject or retain a null speculation to determine a statistically important relationship between two variables (normally one unbiased and one dependent variable, i.e. normally one is the trigger and one is the impact) .
Establishing Speculation Check
- Describe the speculation in phrases or make a declare.
- Based mostly on declare outline null and different hypotheses.
- Determine the kind of speculation check applicable for the above declare.
- Determine the check statistics for use for testing the validity of the null speculation.
- Determine the factors for rejection and retention of null speculation. That is known as significance worth historically denoted by image α (alpha).
- Calculate the p-value which is the conditional chance of observing the check statistic worth when the null speculation is true. In easy phrases, p-value is the proof in assist of the null speculation.
Parametric and Non parametric check
Non-parametric statistical exams don’t depend on assumptions concerning the parameters of the inhabitants distributions from which the info are sampled, whereas parametric statistical exams do.
Parametric Exams
Most statistical exams are carried out utilizing a set of assumptions as their basis. The evaluation might yield deceptive or utterly false conclusions when sure assumptions are violated.
Usually the assumptions are:
- Normality: The sampling distribution of parameters to be examined follows a regular (or at the very least symmetric) distribution.
- Homogeneity of variances: The variance of the info is identical throughout completely different teams except we’re testing for inhabitants means coming from two completely different populations.
Among the parametric check are :
- Z-test : Check for inhabitants imply or variance or proportion when the inhabitants customary deviation is thought.
- Scholar’s t-test: Check for inhabitants imply or variance or proportion when the inhabitants customary deviation will not be identified.
- Paired t-test: Used to match the technique of two associated teams or situations.
- Evaluation of Variance (ANOVA): Used to match means throughout three or extra unbiased teams.
- Regression evaluation: Used to evaluate the connection between a number of unbiased variables and a dependent variable.
- Evaluation of Covariance (ANCOVA): Extends ANOVA by incorporating further covariates into the evaluation.
- Multivariate Evaluation of Variance (MANOVA): Extends ANOVA to evaluate variations in a number of dependent variables throughout teams.
Now let’s deep dive into Non parametric check.
Non parametric check
For the primary time, Wolfowitz used the time period “non-parametric” in 1942. To grasp the concept of nonparametric statistics, one should first have a primary understanding of parametric statistics, which now we have simply mentioned. A parametric check requires a pattern that follows a particular distribution(normally regular). Moreover, nonparametric exams are unbiased of parametric assumptions like normality.
Non parametric exams (often known as distribution free exams since they don’t have assumptions concerning the distribution of the inhabitants). Non parametric exams suggest that the exams should not based mostly on the assumptions that the info is drawn from a chance distribution outlined by way of parameters akin to imply, proportion and customary deviation.
Nonparametric exams are used when both:
- The check will not be concerning the inhabitants parameter akin to imply or proportion.
- The strategy doesn’t require assumptions about inhabitants distribution (akin to inhabitants follows a traditional distribution).
Sorts of Non Parametric Exams
Now let’s talk about the idea and process for doing Chi-Sq. check, Mann-Whitney check, Wilcoxon Signed Rank check , and Kruskal-Wallis exams :
Chi-Sq. Check
To find out whether or not the affiliation between two qualitative variables is statistically important, one should conduct a check of significance known as the Chi-Sq. Check.
There are two predominant forms of Chi-Sq. exams:
Chi-Sq. Goodness-of-Match
Use the goodness-of-fit check to determine whether or not a inhabitants with an unknown distribution “suits” a identified distribution. On this case there will likely be a single qualitative survey query or a single end result of an experiment from a single inhabitants. Goodness-of-Match is often used to see if the inhabitants is uniform (all outcomes happen with equal frequency), the inhabitants is regular, or the inhabitants is identical as one other inhabitants with a identified distribution. The null and different hypotheses are:
- H0: The inhabitants suits the given distribution.
- Ha: The inhabitants doesn’t match the given distribution.
Let’s Perceive this with a instance
| Day | Monday | Tuesday | Wednesday | Thrusday | Friday | Saturday | Sunday |
| Variety of Breakdowns | 14 | 22 | 16 | 18 | 12 | 19 | 11 |
The desk exhibits the variety of breakdowns in an element. On this instance solely a single variable is there and now we have to find out whether or not the noticed distribution (given within the desk) suits anticipated Distribution or not.
For this the null speculation and different speculation will likely be formulated as:
- H0:Breakdowns are uniformly distributed.
- Ha: Breakdowns should not uniformly distributed.
And diploma of freedom will likely be n-1 (on this case n=7 ,so df = 7-1=6)
Anticipated worth will likely be= (14+22+16+18+12+19+11)/7=16
| Day | Monday | Tuesday | Wednesday | Thrusday | Friday | Saturday | Sunday |
| Variety of Breakdowns (noticed) | 14 | 22 | 16 | 18 | 12 | 19 | 11 |
| anticipated | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
| (observed-expected) | -2 | 6 | 0 | 2 | -4 | 3 | -5 |
| (observed-expected)^2 | 4 | 36 | 0 | 4 | 16 | 9 | 25 |
Utilizing this system Calculate Chi-square
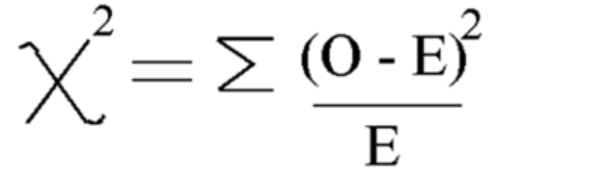
Chi-square = 5.875
And diploma of freedom is = n-1=7-1=6
Now let’s see the important worth from chi sq. distribution desk at 5 % degree of significance
So the important worth is 12.592
For the reason that Chi-Sq. calculated worth is lower than the important worth , we settle for the null speculation and may conclude that the breakdowns are uniformly distributed.
Chi-Sq. Independence of Check
Use the check for independence to determine whether or not two variables (elements) are unbiased or dependent, i.e. whether or not these two variables have a major affiliation relationship between them or not . On this case there will likely be two qualitative survey questions or experiments and a contingency desk will likely be constructed. The objective is to see if the 2 variables are unrelated (unbiased) or associated (dependent). The null and different hypotheses are:
- H0: The 2 variables (elements) are unbiased.
- Ha: The 2 variables (elements) are dependent.
Let’s take an instance
Instance by which we wish to examine if gender and most popular colour of blouse have been unbiased. This implies we wish to discover out if an individual’s gender influences their colour alternative. We carried out a survey and arranged the info within the desk.
This desk is noticed values:
| Black | White | Pink | Blue | |
| Male | 48 | 12 | 33 | 57 |
| Feminine | 34 | 46 | 42 | 26 |
Now first formulate null and different hypotheses
- H0: Gender and most popular shirt colour are unbiased
- Ha: Gender and most popular shirt colour should not unbiased
For calculating Chi-squared check statistics we have to calculate the anticipated worth. So, add all of the rows and columns and general totals:
| Black | White | Pink | Blue | Whole | |
| Male | 48 | 12 | 33 | 57 | 150 |
| Feminine | 34 | 46 | 42 | 26 | 148 |
| Whole | 82 | 58 | 75 | 83 | 298 |
After this we will calculate the anticipated worth desk from the above desk for every entry utilizing this system = (row complete * column complete)/general complete
Anticipated worth Desk:
| Black | White | Pink | Blue | |
| Male | 41.3 | 29.2 | 37.8 | 41.8 |
| Feminine | 40.7 | 28.8 | 37.2 | 41.2 |
Now calculate Chi sq. worth utilizing the system for chi-Sq. Check:
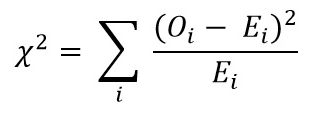
- Oi = Noticed Worth
- Ei = Anticipated Worth
The worth which we get is: Χ2 = 34.9572
Calculate Diploma of Freedom
DF=(variety of row-1)*(variety of column-1)
Now discover and examine the important worth to chi-square check statistic worth:
To do that you possibly can search for diploma of freedom and the importance degree (alpha) from the chi-square distribution desk
At alpha =0.050, we are going to get important worth= 7.815
Since chi-square> important worth
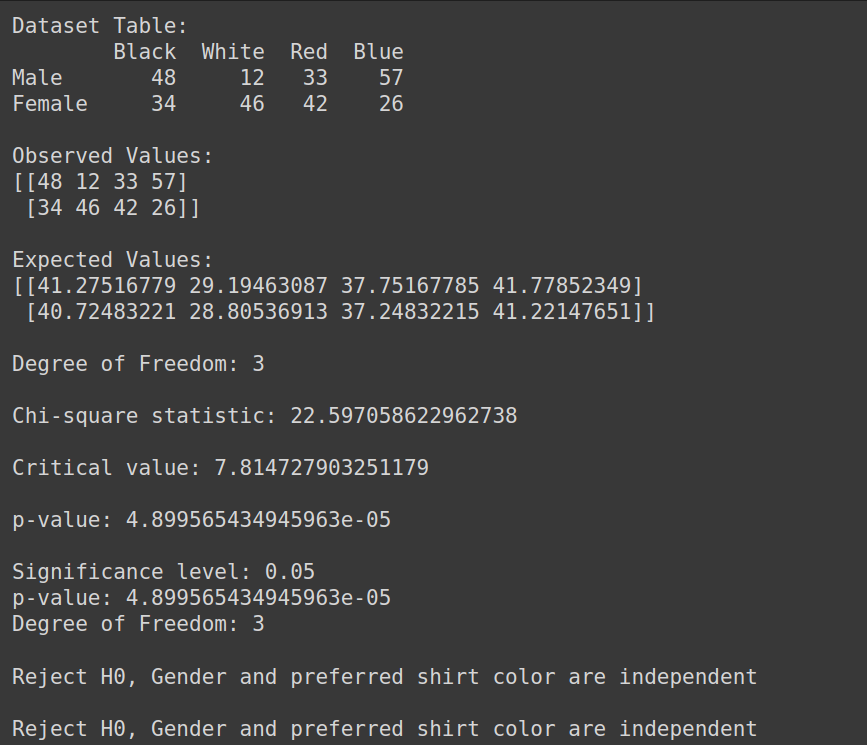
Due to this fact, we reject the null speculation and we will conclude that gender and most popular shirt colour should not unbiased.
Implementation of Chi- Sq.
Now , Let’s see the implementation of Chi- Sq. utilizing some actual life instance in python:
- H0: Gender and most popular shirt colour are unbiased
- Ha: Gender and most popular shirt colour should not unbiased
Creating Dataset:
import pandas as pd
from scipy.stats import chi2_contingency
from scipy.stats import chi2
# Given dataset
df_dict = {
'Black': [48, 34],
'White': [12, 46],
'Pink': [33, 42],
'Blue': [57, 26]
}
dataset_table = pd.DataFrame(df_dict, index=['Male', 'Female'])
print("Dataset Desk:")
print(dataset_table)
print()
# Noticed Values
Observed_Values = dataset_table.values
print("Noticed Values:")
print(Observed_Values)
print()
# Carry out chi-square check
val = chi2_contingency(dataset_table)
Expected_Values = val[3]
print("Anticipated Values:")
print(Expected_Values)
print()
# Diploma of Freedom
no_of_rows = len(dataset_table.iloc[0:2, 0])
no_of_columns = 4
ddof = (no_of_rows - 1) * (no_of_columns - 1)
print("Diploma of Freedom:", ddof)
print()
# Chi-square statistic
chi_square = sum([(o - e) ** 2. / e for o, e in zip(Observed_Values, Expected_Values)])
chi_square_statistic = chi_square[0] + chi_square[1]
print("Chi-square statistic:", chi_square_statistic)
print()
# Crucial worth
alpha = 0.05
critical_value = chi2.ppf(q=1-alpha, df=ddof)
print('Crucial worth:', critical_value)
print()
# p-value
p_value = 1 - chi2.cdf(x=chi_square_statistic, df=ddof)
print('p-value:', p_value)
print()
# Significance degree
print('Significance degree:', alpha)
print('p-value:', p_value)
print('Diploma of Freedom:', ddof)
print()
# Speculation testing
if chi_square_statistic >= critical_value:
print("Reject H0, Gender and most popular shirt colour are unbiased")
else:
print("Fail to reject H0, Gender and most popular shirt colour should not unbiased")
print()
if p_value <= alpha:
print("Reject H0, Gender and most popular shirt colour are unbiased")
else:
print("Fail to reject H0, Gender and most popular shirt colour should not unbiased")
Output:
Mann- Whitney U Check
The Mann-Whitney U check serves because the non-parametric different to the unbiased pattern t-test. It compares two pattern means from the identical inhabitants, figuring out if they’re equal. This check is often used for ordinal knowledge or when assumptions of the t-test should not met.
The Mann-Whitney U check ranks all values from each teams collectively, then sums the ranks for every group. It calculates the check statistic, U, based mostly on these ranks. The U-statistic is in comparison with a important worth from a desk or calculated utilizing an approximation. If the U-statistic is lower than the important worth, the null speculation is rejected.
That is completely different from parametric exams just like the t-test, which examine means and assume a traditional distribution. The Mann-Whitney U check as a substitute compares ranks and doesn’t require the belief of a traditional distribution.
Understanding the Mann-Whitney U check may be troublesome as a result of the outcomes are introduced in group rank variations relatively than group imply variations.
Method for Mann-Whitney Check:
U= min(U1,U2)
Right here,
- U= Mann-Whitney U Check
- n1= pattern measurement one
- n2= pattern measurement two
- R1= Rank of the pattern measurement one
- R2= Rank of pattern measurement 2
So, let’s perceive this with a brief instance:
Suppose we wish to examine the effectiveness of two completely different Therapy strategies (Technique A and Technique B) in enhancing sufferers’ well being. We have now the next knowledge:
- Technique A: 3,4,2,6,2,5
- Technique B: 9,7,5,10,6,8
Right here, we will see that the info will not be usually distributed, and the pattern sizes are small.
Implementation of Mann-Whitney U check
Now, let’s carry out the Mann-Whitney U check:
However first let’s formulate the Null and Various speculation
- H0: There isn’t a distinction between the Rank of every therapy
- Ha: There’s a distinction between the Rank of every therapy
Mix all of the therapies: 3,4,2,6,2,5,9,7,5,10,6,8
Sorted knowledge : 2,2,3,4,5,5,6,6,7,8,9,10
Rank of sorted knowledge: 1,2,3,4,5,6,7,8,9,10,11,12
- Rating the Knowledge Individually:
- Technique A: 3(3),4(4),2(1.5),6(7.5),2(1.5),5(5.5)
- Technique B: 9(11),7(9),5(5.5),10(12),6(1.5),8(10)
- Calculating sum of rank):
- R1: 3+4+1.5+7.5+1.5+5.5=23
- R2: 11+9+5.5+12+1.5+10=55
Now calculate the statistic worth utilizing this system:
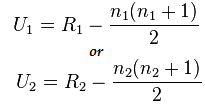
Right here n1=6 and n2=6
And the worth after calculation for U1=2 and for U2= 34
Calculating U statistic :
Us= min(U1,U2)= min(2,34)= 2
From Mann-Whitney Desk we will discover the important worth
On this case Crucial Worth will likely be 5
Since Uc= 5 which is larger than Us at 5% degree of significance .So, we reject H0
Therefore we will conclude that there’s a distinction between the Rank of every therapy.
Implementation with python
from scipy.stats import mannwhitneyu, norm
import numpy as np
TreatmentA = np.array([3,4,2,6,2,5])
TreatmentB = np.array([9,7,5,10,6,8])
# Carry out Mann-Whitney U check
U_statistic, p_value = mannwhitneyu(TreatmentA, TreatmentB)
# Print the end result
print(f'The U-statistic is {U_statistic:.2f} and the p-value is {p_value:.4f}')
if p_value < 0.05:
print("Reject Null Speculation: There's a important distinction between the Rank of every therapy.")
else:
print("Fail to Reject Null Speculation: Fail to Reject Null Speculation: There isn't a sufficient proof to conclude that there's distinction between the Rank of every therapy")Output:

Kruskal –Wallis Check
Kruskal –Wallis Check is used with a number of teams. It’s the non-parametric and a precious different to a one-way ANOVA check when the normality and equality of variance assumptions are violated. Kruskal –Wallis Check compares medians of greater than two unbiased teams.
It exams the Null Speculation when okay unbiased samples (okay>=3) are drawn from a inhabitants with equivalent distributions, with out requiring the situation of normality for the populations.
Assumptions:
Guarantee there are at the very least three independently drawn random samples. Every pattern has at the very least 5 observations, n>=5
Take into account an instance the place we wish to decide if the finding out approach utilized by three teams of scholars impacts their examination scores. We will use the Kruskal-Wallis Check to investigate the info and assess whether or not there are statistically important variations in examination scores among the many teams.
Formulate the null speculation for this as:
- H0: There isn’t a distinction in examination scores among the many three teams of scholars.
- Ha: There’s a distinction in examination scores among the many three teams of scholars.
Wilcoxon Signed Rank Check
Wilcoxon Signed Rank Check (often known as Wilcoxon Matched Pair Check) is the non-parametric model of dependent pattern t-test or paired pattern t-test. Signal check is the opposite nonparametric different to the paired pattern t-test. It’s used when the variables of curiosity are dichotomous in nature (akin to Male and Feminine, Sure and No). Wilcoxon Signed Rank Check can also be a nonparametric model for one pattern t-test. Wilcoxon Signed Rank Check compares the medians of the teams beneath two conditions (paired samples) or it compares the median of the group with hypothesized median (one pattern).
Let’s perceive this with an instance suppose now we have knowledge on the every day cigarette consumption of people who smoke earlier than and after collaborating in a 8-week program and we wish to decide if there’s a important distinction in every day cigarette consumption earlier than and after this system then we are going to use this check
The speculation formulation for this will likely be
- H0: There isn’t a distinction in every day cigarette consumption earlier than and after this system.
- Ha: There’s a distinction in every day cigarette consumption earlier than and after this system
Check for Normality
Allow us to now talk about Normality exams:
Shapiro Wilk check
The Shapiro-Wilk check assesses whether or not a given pattern of knowledge comes from a usually distributed inhabitants. It’s one of the generally used exams for checking normality. The check is especially helpful when coping with comparatively small pattern sizes.
Within the Shapiro-Wilk check:
- Null Speculation : The pattern knowledge comes from a inhabitants that follows a traditional distribution.
- Various Speculation : The pattern knowledge doesn’t come from a inhabitants that follows a traditional distribution.
The check statistic generated by the Shapiro-Wilk check measures the discrepancy between the noticed knowledge and the anticipated knowledge beneath the belief of normality. If the p-value related to the check statistic is lower than a selected significance degree (e.g., 0.05), we reject the null speculation, indicating that the info should not usually distributed. If the p-value is larger than the importance degree, we fail to reject the null speculation, suggesting that the info might comply with a traditional distribution.
First Let’s Create a dataset for these check you should utilize any dataset of your alternative:
import pandas as pd
# Create the dictionary with the offered knowledge
knowledge = {
'inhabitants': [6.1101, 5.5277, 8.5186, 7.0032, 5.8598],
'revenue': [17.5920, 9.1302, 13.6620, 11.8540, 6.8233]
}
# Create the DataFrame
df = pd.DataFrame(knowledge)
response_var=df['profit']
Right here, a pattern for working Shapiro -Wilk check on python:
from scipy.stats import shapiro
stat, p_val = shapiro(response_var)
print(f'Shapiro-Wilk Check: Statistic={stat} p-value={p_val}')
if p_val > alpha:
print('Knowledge seems to be regular (fail to reject H0)')
else:
print('Knowledge seems to be regular (fail to reject H0)')Output:

This check is most applicable for comparatively small pattern sizes( n=< 50-2000) because it turns into much less dependable with bigger pattern sizes.
Anderson-Darling
It assesses whether or not a given pattern of knowledge comes from a specified distribution, akin to the traditional distribution. It’s much like the Shapiro-Wilk check however is extra delicate particularly for smaller pattern sizes.
It fits a number of distributions, together with the traditional distribution, for circumstances the place the parameters of the distribution are unknown.
Right here, Python code for Implementing it:
from scipy.stats import anderson
response_var = knowledge['profit']
alpha = 0.05
# Anderson-Darling Check
end result = anderson(response_var)
print(f'Anderson statistics: {end result.statistic:.3f}')
if end result.statistic > end result.critical_values[-1]:
p_value = 0.0 # The p-value is actually 0 if the statistic exceeds the most important important worth
else:
p_value = end result.significance_level[result.statistic < result.critical_values][-1]
print("P-value:", p_value)
if p_value < alpha:
print("Reject null speculation: Knowledge doesn't look usually distributed")
else:
print("Fail to reject null speculation: Knowledge seems to be usually distributed")Output:

Jarque-Bera Check
The Jarque-Bera check assesses whether or not a given pattern of knowledge comes from a usually distributed inhabitants. It’s based mostly on the skewness and kurtosis of the info.
Right here’s the implementation of Jarque-Bera Check in Python with pattern knowledge:
from scipy.stats import jarque_bera
# Performing Jarque-Bera check
test_statistic, p_value = jarque_bera(response_var)
print("Jarque-Bera Check Statistic:", test_statistic)
print("P-value:", p_value)
# Deciphering outcomes
alpha = 0.05
if p_value < alpha:
print("Reject null speculation: Knowledge doesn't look usually distributed")
else:
print("Fail to reject null speculation: Knowledge seems to be usually distributed")Output:

| Class | Parametric Statistical Strategies | Non- parametric StatisticalStrategies |
| correlation | Pearson Product Second Coefficient of Correlation (r) | Spearman Rank Coefficient Correlation (Rho), Kendall‟s Tau |
| Two teams, unbiased measures | Impartial t-test | Mann-Whitney U check |
| Greater than two teams, unbiased measures | One-way ANOVA | Kruskal-Wallis a technique ANOVA |
| Two teams, repeated measures | Paired t-test | Wilcoxon matched pair signed rank check |
| Greater than two teams, repeated measures | One-way, repeated measures ANOVA | Friedman’s two method Evaluation of Variance |
Conclusion
Speculation testing is crucial for evaluating claims about inhabitants parameters utilizing pattern knowledge. Parametric exams depend on particular assumptions and are appropriate for interval or ratio knowledge, whereas non-parametric exams are extra versatile and relevant to nominal or ordinal knowledge with out strict distributional assumptions. Exams akin to Shapiro-Wilk and Anderson-Darling assess normality, whereas Chi-square and Jarque-Bera consider goodness of match. Understanding the variations between parametric and non-parametric exams is essential for choosing the suitable statistical method. Total, speculation testing gives a scientific framework for making data-driven choices and drawing dependable conclusions from empirical proof.
Able to grasp superior statistical evaluation? Enroll in our BlackBelt Knowledge Evaluation course right now! Achieve experience in speculation testing, parametric and non-parametric exams, Python implementation, and extra. Elevate your statistical expertise and excel in data-driven decision-making. Be part of now!
Continuously Requested Questions
A. Parametric exams make assumptions concerning the inhabitants distribution and parameters, akin to normality and homogeneity of variance, whereas non-parametric exams don’t depend on these assumptions. Parametric exams have extra energy when assumptions are met, whereas non-parametric exams are extra sturdy and relevant in a wider vary of conditions, together with when knowledge are skewed or not usually distributed.
A. The chi-square check is used to find out whether or not there’s a important affiliation between two categorical variables. It generally analyzes categorical knowledge and exams hypotheses concerning the independence of variables in contingency tables.
A. The Mann-Whitney U check compares two unbiased teams when the dependent variable is ordinal or not usually distributed. It assesses whether or not there’s a important distinction between the medians of the 2 teams.
A. The Shapiro-Wilk check assesses whether or not a pattern comes from a usually distributed inhabitants. It exams the null speculation that the info comply with a traditional distribution. If the p-value is lower than the chosen significance degree (e.g., 0.05), we reject the null speculation, concluding that the info should not usually distributed.