
{kind=link}
Carry this challenge to life
Gone are the times when interacting with PDFs was cumbersome and time-consuming. Customers needed to open the paperwork manually utilizing software program like Adobe Reader and skim by your entire doc or use important search features to search out particular data. However now chatting with an AI assistant is easy with the mixing of LangChain. Customers can add PDFs to a LangChain enabled LLM software and obtain correct solutions inside seconds, by a course of known as Optical character recognition (OCR).
This advantages companies requiring personalized interplay with firm insurance policies, paperwork, or experiences. It may well even assist researchers and college students to establish the necessary elements and keep away from studying the entire e book or analysis paper.
This text will discover the idea of PDF chats utilizing LLM and in addition present the demo of constructing PDF AI Chatbot.Combine the ability of LangChain with Paperspace Gradient and redefine the capabilities of chatbots and AI in managing PDF content material. RAG (Retrieval Augmented Technology) strategies may also be built-in together with it.
Introduction to PDF Analyser
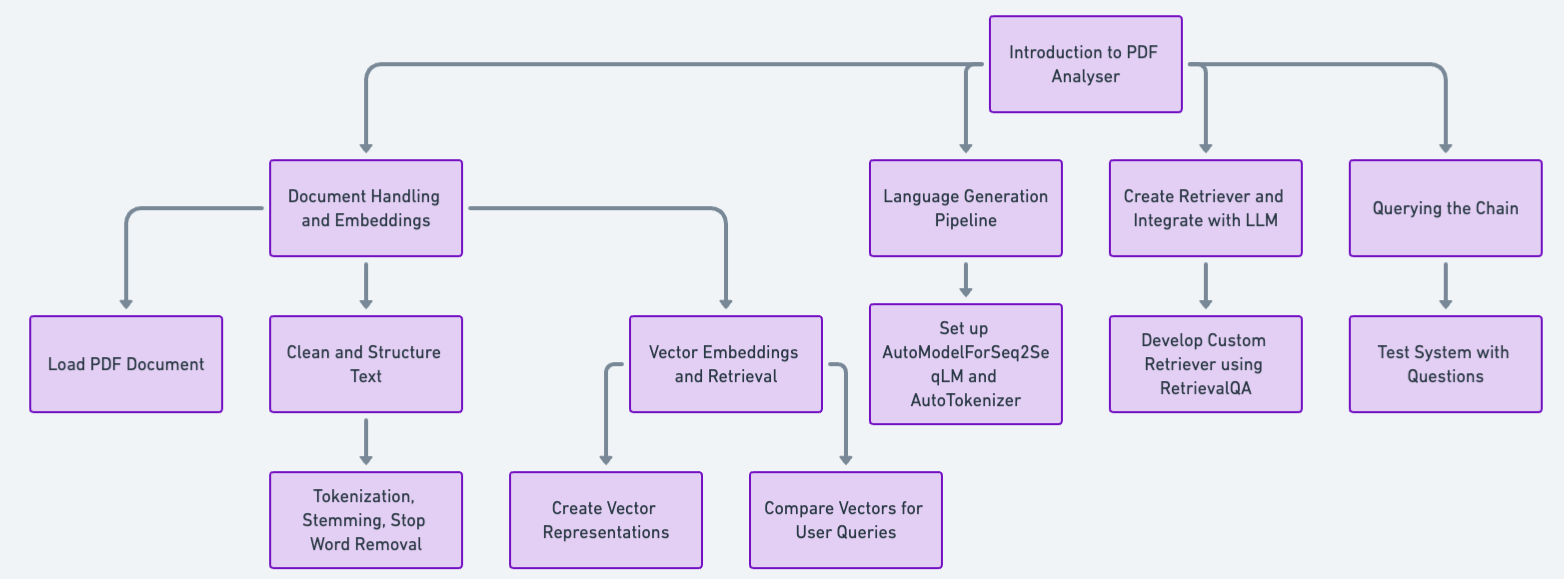
- Doc Dealing with and Embeddings: Load the PDF doc utilizing an appropriate loader like PyPDFLoader. Clear and construction the textual content knowledge (eradicating headers/footers, dealing with particular characters, and segmenting textual content into paragraphs or sections). It may additionally contain tokenization (breaking textual content into phrases), stemming/lemmatization (decreasing phrases to their root kind), or cease phrase removing (eliminating frequent phrases like “the ” or “a ”) at this step.
- Vector Embeddings and Retrieval: This includes creating vector representations of the textual content chunks extracted from the PDFs. These vectors seize the semantic which means and relationships between phrases. The chatbot generates a vector for the question and compares it with the saved doc vectors throughout consumer queries. Paperwork with the closest vector match are thought of probably the most related for the consumer’s query. Libraries like Gensim or Faiss can be utilized for this strategy.
- Language Technology Pipeline: Arrange the language era pipeline utilizing AutoModelForSeq2SeqLM and AutoTokenizer.
- Create a Retriever and Combine with LLM: Develop a customized retriever utilizing RetrievalQA to fetch related paperwork primarily based on queries.
- Querying the Chain: Take a look at the system by querying the chain with questions associated to the PDF content material.
Interacting with PDFs Immediately
Now, it’s extremely simple to know the contents of PDFs. Simply add the PDF to the LLM software and ask questions in regards to the content material within the PDF. It’s the identical as chatting with ChatGPT, however customers can add the PDFs immediately.
Custom-made Doc Dealing with
Companies can now customise the doc dealing with system for extra exact interactions with firm paperwork, insurance policies, or experiences in PDF format. An unlimited repository of PDF paperwork could be ready for workers, and LLMs could be skilled on it. Customers can merely add the doc and ask questions in plain language, “What are the corporate’s sick go away insurance policies?”, or the gross sales crew can shortly question up-to-date technical specs or product data from PDF catalogs or manuals.
Dynamic Content material Retrieval
RAG (Retrieval Augmented Technology) strategies can incorporate exterior knowledge in real-time. This implies companies with LLM powered functions can entry probably the most present data from the corporate database utilizing RAG strategies. This ensures that the generated responses are present and might help decision-making. Think about a gross sales crew asking a few product’s availability. To offer the newest inventory standing, the LLM not solely retrieves data from the PDF handbook but in addition accesses the corporate’s stock database.
Safe and Environment friendly Info Extraction
Confidentiality is essential in sectors like monetary providers and authorized providers. LLMs can preserve privateness and safety by offering data from delicate PDF paperwork with out exposing your entire context, guaranteeing solely licensed data is accessed.
Software in Data Bases
As new insurance policies or procedures are uploaded as PDFs, an LLM can scan and extract data from PDFs and replace the data base by updating FAQs accordingly. LangChain has inbuilt purposeful integrations with common storage options like Redis.
Improved Buyer Satisfaction
Clients can get customized interplay and fast entry to related data by integrating PDF interplay chatbots. For instance, a chatbot can information clients in assembling a chunk of furnishings from IKEA. It may well present step-by-step directions by referring to the PDF consumer handbook and guarantee a clean buyer buying expertise.
We’ve got tried a PDF interplay demo utilizing Langchain beneath. However why use Langchain?
Lanchain presents pre-built elements like retrieval programs, doc loaders, and LLM integration instruments. LangChain elements have already been examined to make sure efficient working with paperwork and alarms. It improves the general effectivity of the event course of and reduces the chance of errors.
Why use Paperspace Gradient for constructing a PDF Doc Interplay Software
Langchain presents a number of benefits, notably when mixed with Paperspace Gradient. This mix offers a strong and user-friendly platform for constructing LLM-powered functions that may work together with paperwork.
Simplified Growth
LangChain offers pre-built elements, streamlined workflows, and permits domain-specific customization. Paperspace additionally offers pre-built libraries like TensorFlow and PyTorch, that are extensively utilized in machine studying and pure language processing duties, pre-installed on their Notebooks. This enables builders to decide on and combine fashions with probably the most superior PDF evaluation and question-answering capabilities.
Integration with HuggingFace Hub
HuggingFace presents many open-source fashions. Integration with HuggingFace Hub with Paperspace permits implementation and fine-tuning of any mannequin on it in keeping with the use case. Paperspace additionally presents a user-friendly platform for deployment. Builders can share their skilled or fine-tuned fashions with others on the HuggingFace Hub immediately from their Paperspace workspace.
Demo Code
Carry this challenge to life
This demo used a pre-trained hugging face mannequin, ‘flan-t5-large’. Different open-source fashions, like FastChatT5 3b Mannequin and Falcon 7b Mannequin, may also be used for this. Begin the Gradient Pocket book by selecting the GPU and cloning the repository. This repository didn’t have necessities.txt, so the dependencies have been put in individually.
Mannequin and Doc Loading
Embedding_Model = "hkunlp/instructor-xl"
LLM_Model = "google/flan-t5-large"
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content material/langchain/qna_from_pdf_file_with_citation_using_local_Model/pdf_files/TRANSFORMERS.pdf") #path to PDF doc
paperwork = loader.load_and_split()
- ‘hkunlp/instructor-xl’ is the Embedding_Model, and ‘google/flan-t5-large’ is used as LLM_Model defines pre-trained fashions for textual content embedding and language era, respectively. This pre-trained mannequin is taken from HuggingFace.
- A PyPDFLoader masses the PDF file by giving the trail to the PDF doc. Right here, just one PDF doc is loaded. A number of PDF paperwork could be loaded into the folder, and a path to the folder may also be given.
- The
load_and_splitmethodology of the loader reads and splits the PDF content material into particular person sections or paperwork for processing.
Testing the Embeddings Mechanism
from langchain_community.embeddings import HuggingFaceInstructEmbeddings
instructor_embeddings = HuggingFaceInstructEmbeddings(model_name=Embedding_Model)
textual content = "It is a check doc."
query_result = instructor_embeddings.embed_query(textual content)Testing the embedding era course of is frequent observe earlier than integrating it into a bigger system, akin to a question-answering system that processes PDF paperwork. With the chosen embedding mannequin, an occasion of HuggingFaceInstructEmbeddings is created.
3. Language Technology Pipeline
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
tokenizer = AutoTokenizer.from_pretrained(LLM_Model)
mannequin = AutoModelForSeq2SeqLM.from_pretrained(LLM_Model, torch_dtype=torch.float32)
pipe = pipeline(
"text2text-generation",
mannequin=mannequin,
tokenizer=tokenizer,
max_length=512,
temperature=0,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)AutoTokenizer.from_pretrained(LLM_Model)-This convert textual content right into a format that the mannequin can perceive.
AutoModelForSeq2SeqLM.from_pretrained(LLM_Model, torch_dtype=torch.float32): This line of code is probably going utilized in a Python script using the Transformers library for Pure Language Processing (NLP) duties.AutoModelForSeq2SeqLM: This a part of the code refers to a pre-trained mannequin structure particularly designed for sequence-to-sequence studying duties. It is used for duties like machine translation, summarization, and textual content era..from_pretrained(LLM_Model): This part masses a pre-trained LLM (Massive Language Mannequin) from the transformers library’s mannequin hub.torch_dtype=torch.float32:torch.float32signifies that the mannequin will use 32-bit floating-point precision.pipe = pipeline: Creates a text-to-text era pipeline for producing textual content with the mannequin.
Parameters for the pipeline:
- mannequin, tokenizer: Specify the mannequin and tokenizer to make use of.
- max_length: Limits the utmost size of the generated textual content to 512 tokens.
- temperature (0): Controls randomness in era (0 means deterministic).
- top_p (0.95): Filters potential subsequent tokens for extra doubtless responses.
- repetition_penalty (1.15): Discourages repetitive textual content era.
4. Create a retriever from the index and combine it with LLM
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.paperwork import Doc
from typing import Record
class CustomRetriever(BaseRetriever):
def _get_relevant_documents(
self, question: str, *, run_manager: CallbackManagerForRetrieverRun
) -> Record[Document]:
return [Document(page_content=query)]
retriever = CustomRetriever()
retriever.get_relevant_documents("bar")
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
query = "clarify Energy Transformers?"This code retrieves related paperwork primarily based on a question and generates solutions to questions utilizing these paperwork. It integrates the retrieved part with a QA pipeline within the LangChain framework.
5. Question the Chain
query = "Very best transformers could be characterised as?"
generated_text = qa(query)
Generated_textqa(query) name in real-time or work together with the LangChain framework immediately and can generate the output.
💡
For integrating this chat function within the software, coaching and finetuning is required first. GPUs can fastrack that course of. For real-time chats with PDF paperwork, utilizing CPU might be inadequate as it would lead to prohibitively lengthy wait occasions for buyer responses. In that case additionally a high-power GPU might be wanted.
Closing Ideas
The fusion of LangChain, and Paperspace Gradient will assist growing chatbots for PDFs chatting. Integrating RAG strategies, will streamline chatbot conversations and guarantee safe and up-to-date data retrieval from PDF paperwork. The collaborative atmosphere offered by Paperspace Gradient presents a sturdy platform for coaching, deploying and managing LLMs. Extra enhancements might be made to the PDF evaluation. For instance, leveraging OCR know-how for scanning PDFs or handwritten paperwork successfully, telling in regards to the supply citations. So, the Paperspace platform is ideal for future improvements on this subject.
Dive into the world of superior PDF evaluation and chatbot interactions. Discover our pre-built templates, leverage the highly effective HuggingFace Hub integration, and experiment with the newest LLM fashions on the strong, scalable infrastructure offered by Paperspace Gradient.
Strive H100 GPUs on Paperspace.