
{kind=link}
Convey this venture to life
Introduction
YOLO-World a SOTA mannequin joins the YOLO collection, now whats new if we ask! This new mannequin can carry out object detection on (allegedly) any object with out the necessity to prepare the mannequin. Now that is one thing new and unimaginable!
With Paperspace get entry to the highly effective GPUs, we get a good FPS when working with real-time object detection. GPUs, reminiscent of NVIDIA with CUDA, work with optimized libraries and frameworks particularly designed for deep studying duties. These libraries leverage the parallel structure of GPUs and provide environment friendly implementations of widespread deep studying operations, additional enhancing efficiency.
In purposes the place real-time object detection is required, reminiscent of autonomous automobiles or surveillance techniques, GPUs are important. Their parallel processing capabilities allow quick inference speeds, permitting the mannequin to course of and analyze video streams in real-time.
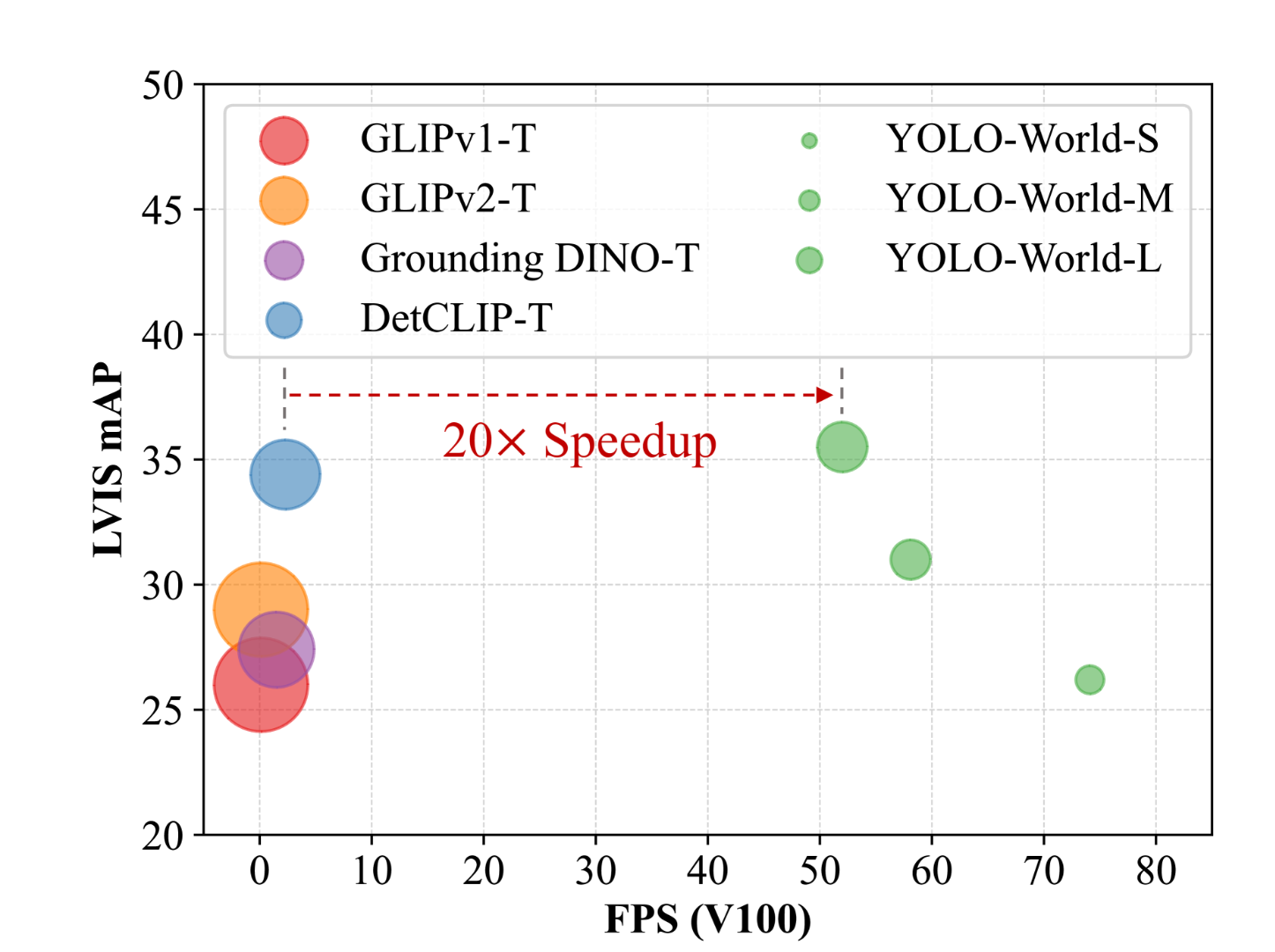
On this article, let’s dig into YOLO-World, a groundbreaking zero-shot object detector that boasts a exceptional 20-fold pace enhancement in comparison with its predecessors. We’ll discover its structure, dissect the first elements contributing to its distinctive pace, and most significantly, we’ll undergo the method of working the mannequin on Paperspace Platform to investigate each photographs and movies.
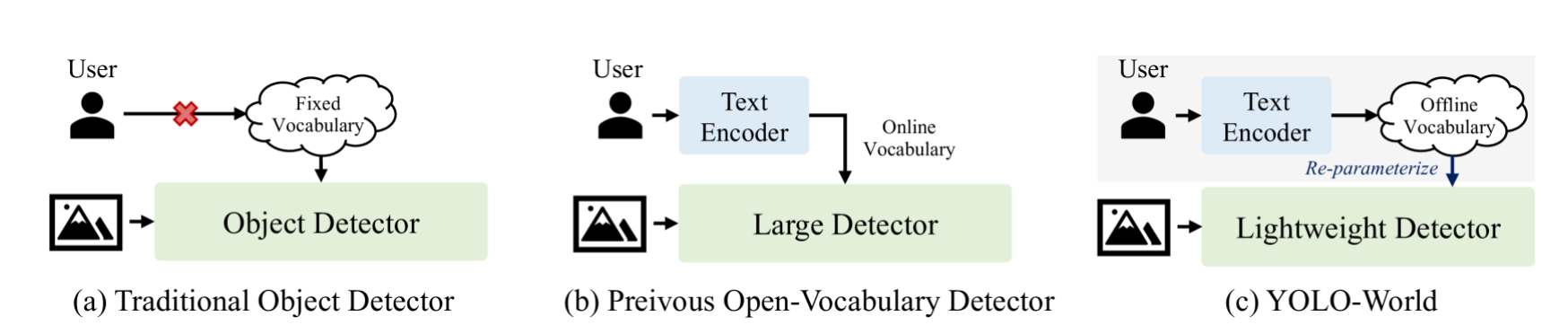
What’s new in YOLO-World
If we discuss conventional object detection fashions like Sooner R-CNN, Single Shot Detectors (SSD), or YOLO for that matter, these fashions are confined to detecting objects inside the predefined classes (such because the 80 classes within the COCO dataset). It is a side of all supervised studying fashions. Not too long ago, researchers have turned their consideration in direction of growing open-vocabulary fashions. These fashions intention to handle the necessity for detecting new objects with out the need of making new datasets, a course of which is each time-consuming and dear.
The YOLO-World Mannequin presents a cutting-edge, real-time technique constructed upon Ultralytics YOLOv8, revolutionizing Open-Vocabulary Detection duties. This development permits for the identification of assorted objects in photographs utilizing descriptive texts. With diminished computational necessities but sustaining top-tier efficiency, YOLO-World proves to be adaptable throughout a big selection of vision-based purposes.
In case you are involved in different fashions in YOLO collection, we encourage our readers to checkout our blogs in YOLO and object detection.
Mannequin Structure
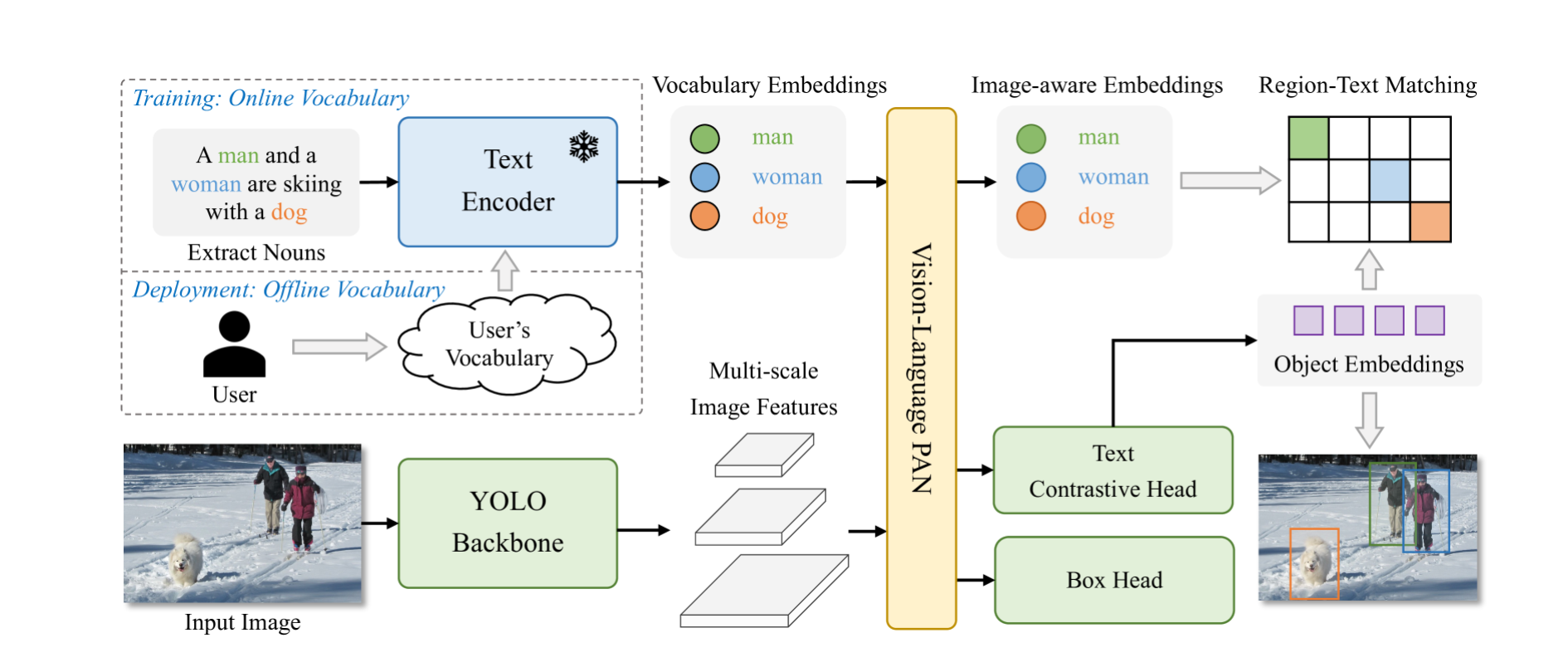
The structure of the YOLO-World consists of a YOLO detector, a Textual content Encoder, and a Re-parameterizable Imaginative and prescient-Language Path Aggregation Community (RepVL-PAN).
YOLO-World primarily builds upon YOLOv8, which features a Darknet spine serving because the picture encoder, a path aggregation community (PAN) for producing multi-scale function pyramids, and a head for each bounding field regression and object embeddings.
The detector captures multi-scale options from the enter picture, a textual content encoder to transform the textual content into embeddings, makes use of a community for multi-level fusion of picture options and textual content embeddings, and incorporates a customized community for a similar objective.
Utilizing a lighter and sooner CNN community as its spine is among the causes for YOLO-World’s pace. The second is prompt-then-detect paradigm. As an alternative of encoding your immediate every time you run inference, YOLO-World makes use of Clip to transform the textual content into embeddings. These embeddings are then cached and reused, bypassing the necessity for real-time textual content encoding.
YOLO-World achieves its pace by two principal methods. Firstly, it adopts a lighter and sooner CNN community as its spine. Secondly, it employs a “prompt-then-detect” paradigm. In contrast to conventional strategies that encode textual content prompts every time throughout inference, YOLO-World makes use of Clip to transform textual content into embeddings. These embeddings are cached and reused, eliminating the necessity for real-time textual content encoding, thereby enhancing pace and effectivity.
Now allow us to bounce to the coding half and take a look at the mannequin utilizing the Paperspace Platform. The hyperlink to the pocket book is supplied with this text, we extremely advocate to take a look at the pocket book and check out the mannequin. Click on the hyperlink and try to be redirected to the Paperspace Platform.
Code Demo
Convey this venture to life
Allow us to begin by checking the working GPU
!nvidia-smi
Now that we’ve got the confirmed output that CUDA session has GPU assist, it is time to set up the mandatory libraries.
!pip set up -U ultralyticsAs soon as the requirement is happy, transfer to the following step of importing the libraries
import ultralytics
ultralytics.__version__Output-
‘8.1.28’
from ultralytics import YOLOWorld
# Initialize a YOLO-World mannequin
mannequin = YOLOWorld('yolov8s-world.pt') # or choose yolov8m/l-world.pt for various sizes
# Execute inference with the YOLOv8s-world mannequin on the required picture
outcomes = mannequin.predict('canine.png',save=True)
# Present outcomes
outcomes[0].present()
Now, if we would like the mannequin to foretell sure objects within the picture with out coaching we will try this by merely passing the argument on “mannequin.set_classes()” operate.
Allow us to use the identical picture and attempt to predict the backpack, a truck and a automobile which is within the background.
# Outline customized courses
mannequin.set_classes(["backpack", "car","dog","person","truck"])
# Execute prediction for specified classes on a picture
outcomes = mannequin.predict('/notebooks/information/canine.jpg', save=True)
# Present outcomes
outcomes[0].present()
Subsequent, allow us to attempt to experiment with one other picture and right here we’ll predict solely a pair of sneakers.
# Outline customized courses
mannequin.set_classes(["shoes"])
# Execute prediction for specified classes on a picture
outcomes = mannequin.predict('/notebooks/information/Two-dogs-on-a-walk.jpg', save=True)
# Present outcomes
outcomes[0].present()
Object Detection utilizing a video
Allow us to now check out the ‘yolov8s-world.pt’ mannequin to detect objects in a video. We’ll execute the next code to hold out the item detection utilizing a saved video.
!yolo detect predict mannequin=yolov8s-world.pt supply="/content material/pexels-anthony-shkraba-8064146 (1440p).mp4"This code block will generate a “runs” folder in your present listing. Inside this folder, you will discover the video saved within the “predict” subfolder, which itself resides inside the “detect” folder.
Accessible Fashions
Please discover the desk under which has a particulars of the fashions which can be found and the duties they assist.
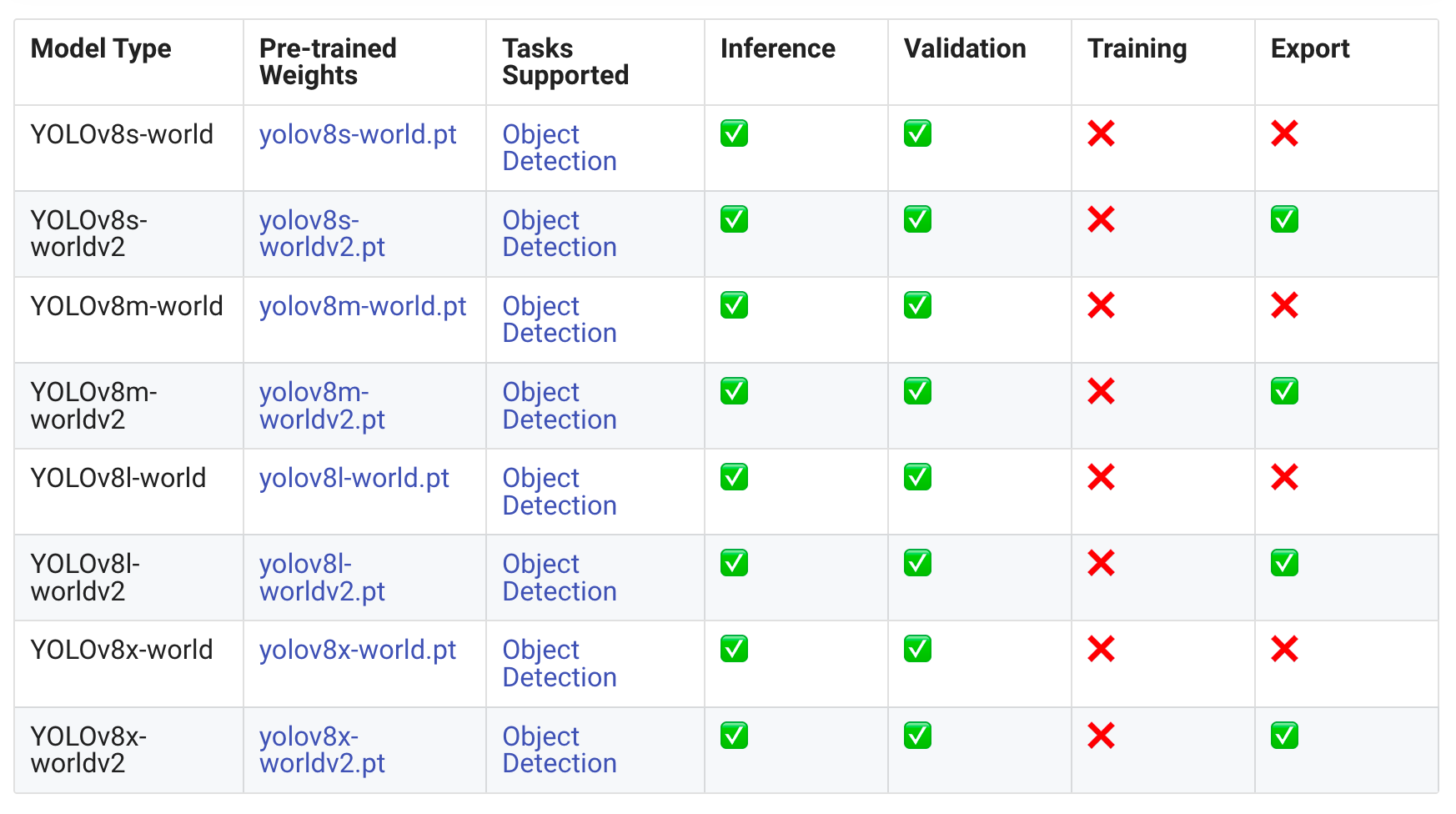
Ultralytics provides a Python API and CLI instructions designed for user-friendly growth, simplifying the event course of.
Detection Capabilitites with Outlined Classes
We tried the mannequin’s detection capabilities with our outlined classes. Listed below are few photographs that we tried YOLOV8m. Please be happy to attempt different fashions from YOLO-World.


Conclusion
On this article we introduce YOLO-World, a complicated real-time detector aiming to boost effectivity and open-vocabulary functionality in sensible settings. This strategy is a novel addition to the standard YOLO architectures to assist open-vocabulary pre-training and detection, using RepVL-PAN to combine imaginative and prescient and language data successfully. Our experiments with totally different photographs demonstrates YOLO-World’s superior pace and efficiency, showcasing the advantages of vision-language pre-training on compact fashions. We envision YOLO-World as a brand new benchmark for real-world open-vocabulary detection duties.