
{kind=link}
LLaVA-1.5 was launched as an open-source, multi-modal language mannequin on October fifth, 2023. This was nice information for AI builders as a result of they may now experiment and innovate with multi-modals that may deal with several types of data, not simply phrases, utilizing a very open-sourced mannequin.
This text will present the potential of the LLaVA mannequin on Paperspace Gradient. Paperspace acts because the engine for offering the computing energy – for anybody seeking to dive into the world of superior AI while not having to buy and setup their very own GPU powered machine.
This text explores the LLaVA1.5 mannequin with a code demo. Completely different experimental examples are proven with outcomes.vThis article may even discover the most recent LLaVA fashions AI builders can use for creating their purposes.
Multimodality with LLaVA
Introduction to Multimodality
In keeping with Grand View Analysis the worldwide multimodal AI market dimension was estimated at USD 1.34 billion in 2023 and is projected to develop at a compound annual progress price (CAGR) of 35.8% from 2024 to 2030.
A multimodal LLM, or multimodal Massive Language Mannequin, is an AI mannequin designed to grasp and course of data from numerous knowledge modalities, not simply textual content. This implies it will probably deal with a symphony of knowledge sorts, together with textual content, photos, audio, video
Conventional language AI fashions typically concentrate on processing textual knowledge. Multimodality breaks free from this limitation, enabling fashions to investigate photos and movies, and course of audio.
Use circumstances of Multi-models
- Writing tales based mostly on photos
- Enhanced robotic management with simultaneous voice instructions (audio) and visible suggestions (digital camera)
- Actual-time fraud detection by analyzing transaction knowledge (textual content) and safety footage (video)
- Analyze buyer critiques (textual content, photos, movies) for deeper insights and inform product improvement.
- Superior climate forecasting by combining climate knowledge (textual content) with satellite tv for pc imagery (photos).
Introduction to LLaVA
The total type of LLaVA is Massive Language and Imaginative and prescient Assistant. LLaVA is an open-source mannequin that was developed by the high quality tuning LLaMA/Vicuna utilizing multimodal instruction-following knowledge collected by GPT. The transformer structure serves as the muse for this auto-regressive language mannequin. LLaVA-1.5 achieves roughly SoTA efficiency on 11 benchmarks, with simply easy modifications to the unique LLaVA, using all public knowledge.
LLaVA fashions are designed for duties like video query answering, picture captioning, or producing artistic textual content codecs based mostly on complicated photos. They require substantial computational sources to course of and combine data throughout totally different modalities. H100 GPUs can cater to those demanding computations.
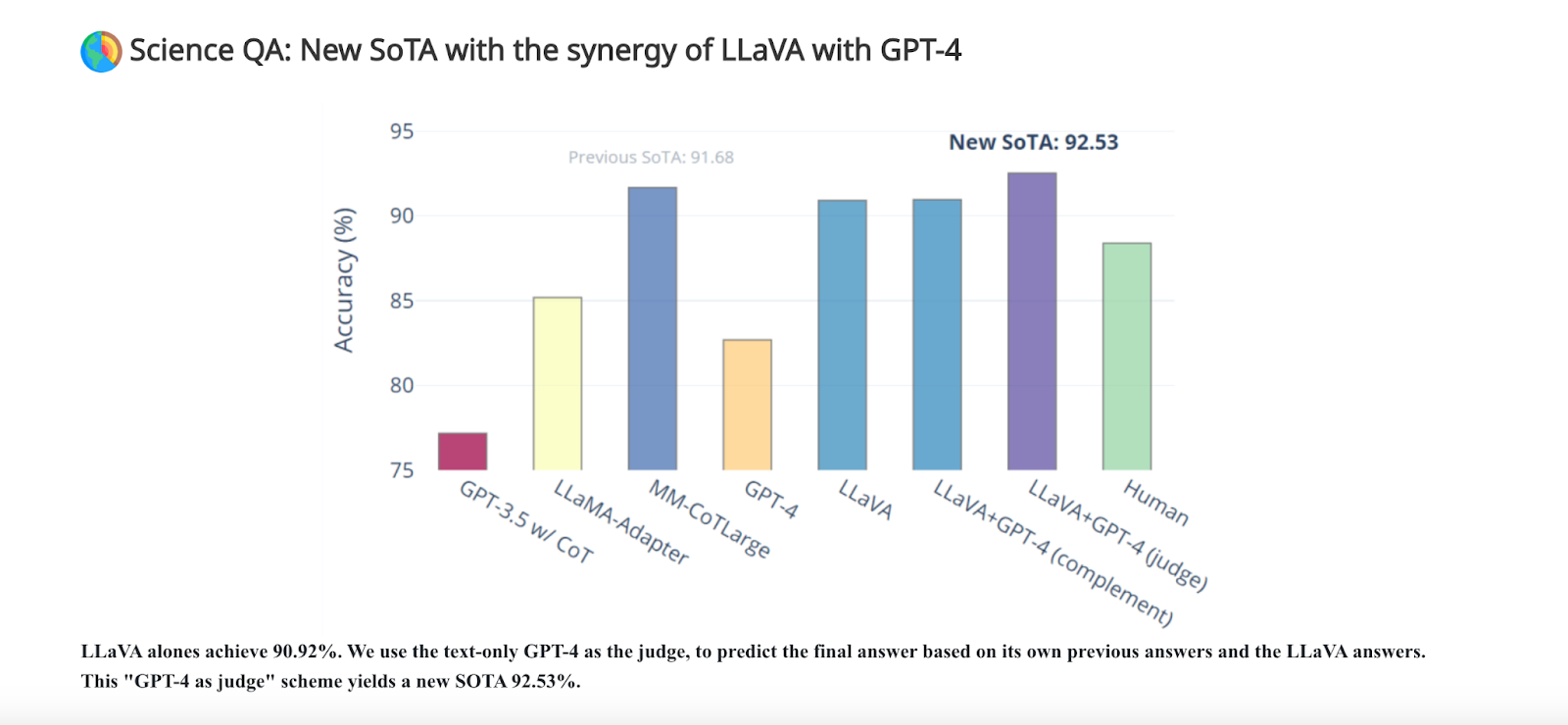
LLaVA alone demonstrates spectacular multimodal chat skills, typically exhibiting the behaviors of multimodal GPT-4 on unseen photos/directions, and yields a 90.92% accuracy rating on an artificial multimodal instruction-following dataset. However when LLaVA is mixed with GPT-4 then its giving the best efficiency compared to different fashions.
There are different LLaVA fashions on the market. We now have listed few of open-source fashions that may be tried:
- LLaVA-HR-It’s a high-resolution MLLM with robust efficiency and noteworthy effectivity. LLaVA-HR drastically outperforms LLaVA-1.5 on a number of benchmarks.
- LLaVA-NeXT- This mannequin improved reasoning, OCR, and world information. LLaVA-NeXT even exceeds Gemini Professional on a number of benchmarks.
- MoE-LLaVA (Combination of Consultants for Massive Imaginative and prescient-Language Fashions) – It is a novel strategy that tackles a big problem on the earth of multimodal AI – coaching large LLaVA fashions (Massive Language and Imaginative and prescient Assistants) effectively.
- Video-LLaVA – Video LLaVA builds upon the muse of Massive Language Fashions (LLMs), similar to Cava, and extends their capabilities to the realm of video.Video-LLaVA additionally outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively.
- LLaVA-RLHF – It’s the open-source RLHF-trained giant multimodal mannequin for general-purpose visible and language understanding. It achieved the spectacular visible reasoning and notion capabilities mimicking spirits of the multimodal GPT-4. It’s claimed that this mannequin yielded 96.6% (v.s. LLaVA’s 85.1%) relative rating in contrast with GPT-4 on an artificial multimodal instruction.
The LLaVA fashions talked about above would require GPUs in the event that they should be educated and high quality tuned. Attempt NVIDIA H100 GPUs on Paperspace. Discuss to our specialists.
Output Examples Tried with LLaVA Mannequin
We examined LLaVA 1.5 on totally different prompts and acquired the next outcomes.
Take a look at #1: Insightful Clarification
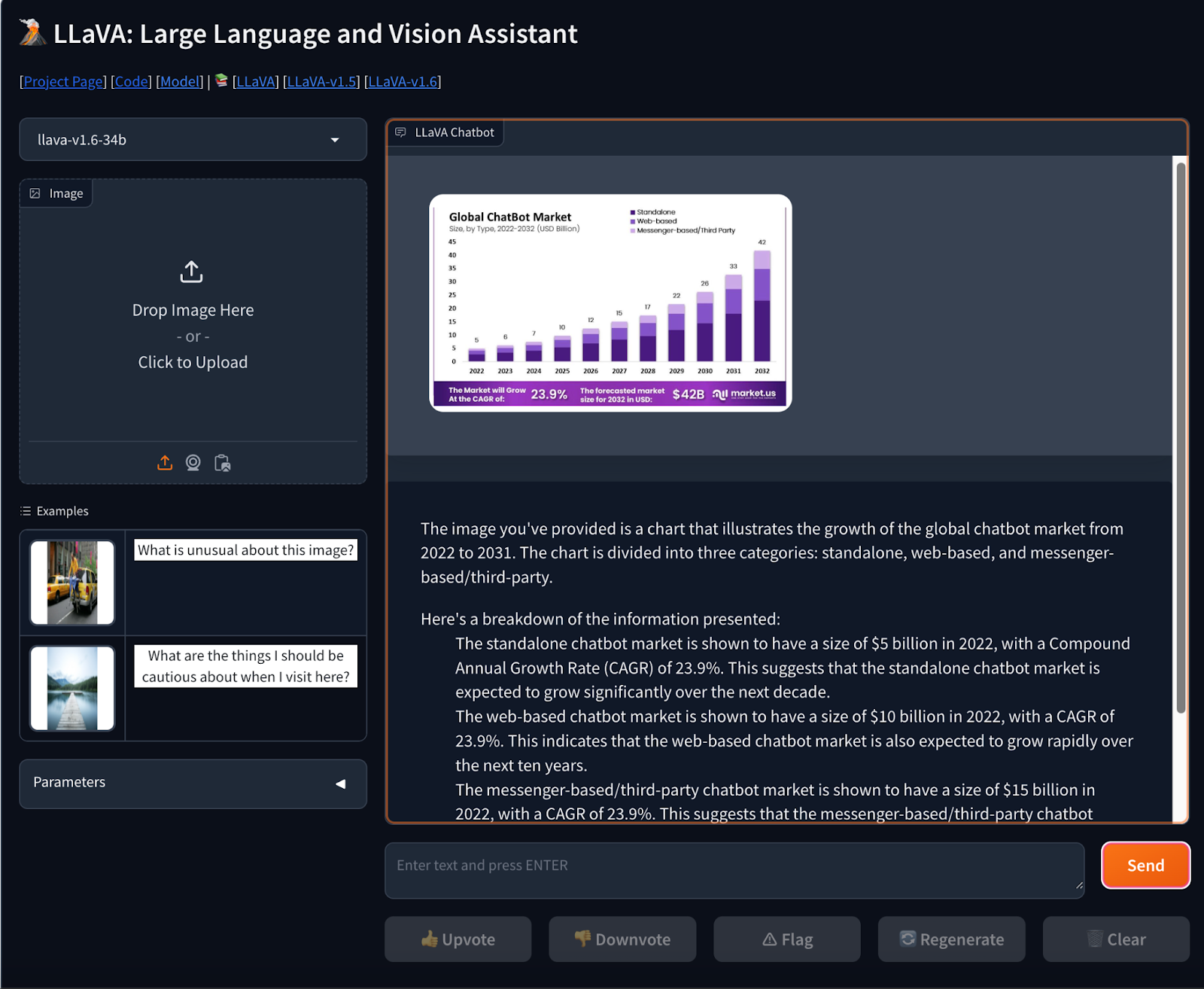
Immediate- Give an insightful rationalization of this picture.
We examined the talents of LLaVA 1.5 by giving a picture which represents the World chatbot market. This mannequin has given full insightful details about the breakdown of the chatbot market as proven within the determine above.
To additional check LLaVA-1.5’s picture understanding skills.
Take a look at #2: Picture Understanding
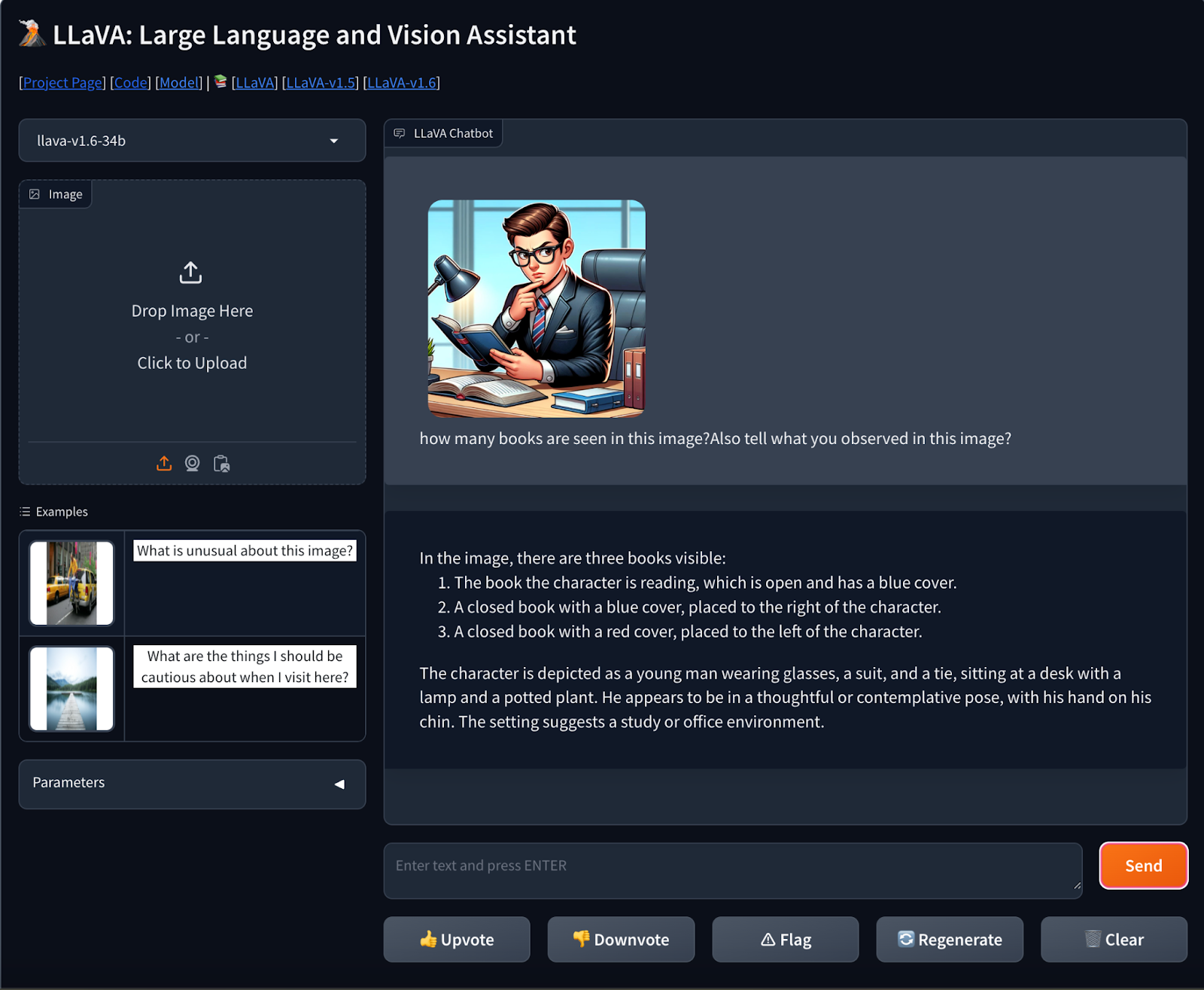
Immediate- what number of books are seen on this picture?Additionally inform what you noticed on this picture?
The mannequin given the proper reply concerning the variety of books and in addition the picture was described precisely whereas focussing on minute particulars.
Take a look at #3: Zero Shot Object Detection
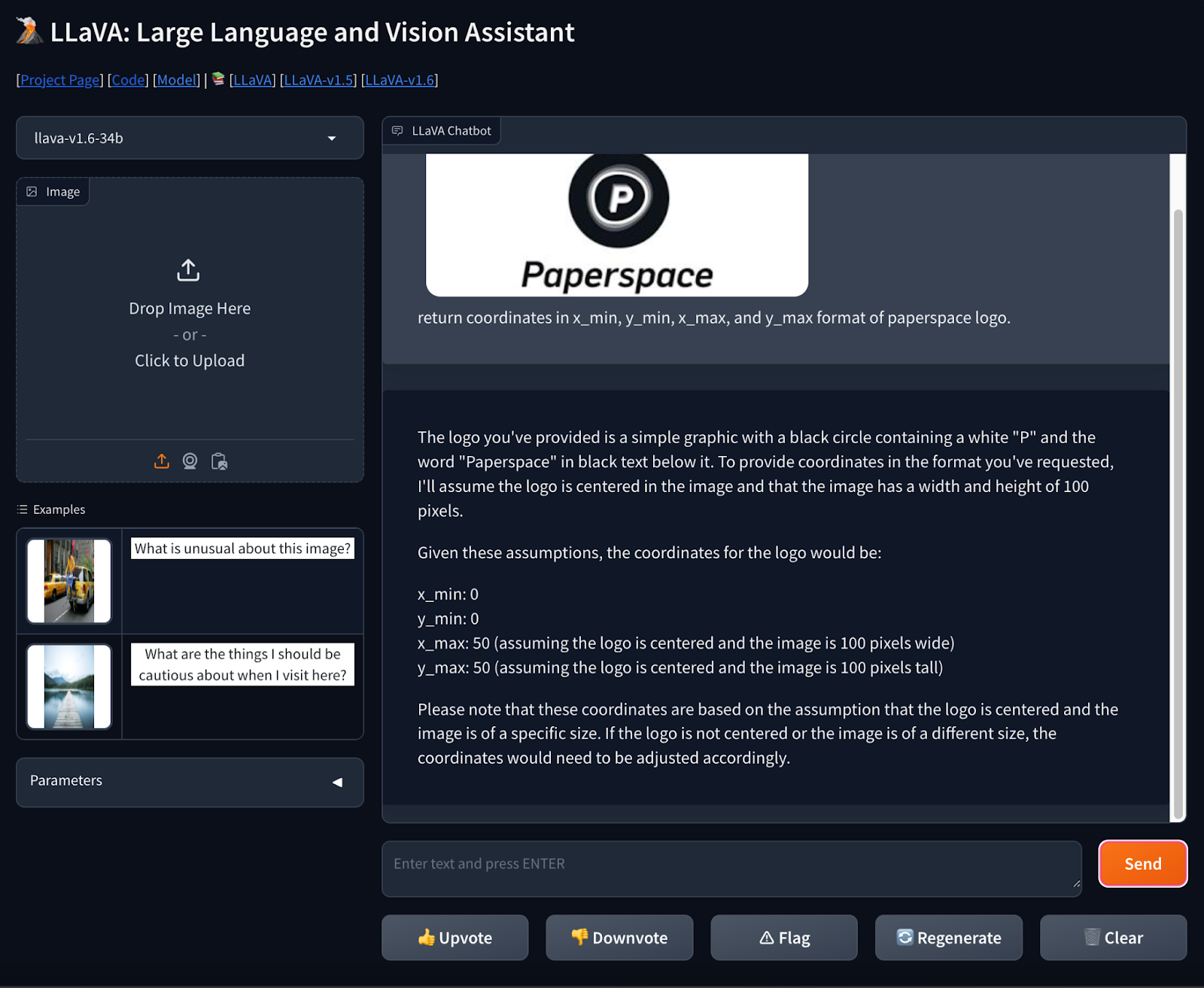
Immediate- Return the coordinates of Paperspace emblem in x_min, y_min, x_max, and y_max format.
The mannequin has returned the coordinates by taking the idea that the brand is centered and given the reply as proven above within the picture. The reply was passable.
Making Multimodality Accessible with Paperspace Gradient
Demo
We now have carried out LLaVA-1.5 (7 Billion parameter) on this demo. Begin the Gradient Pocket book by selecting the GPU. Choose the prebuilt template for the challenge, and set the machine’s auto shutdown time.
Putting in Dependencies
!pip set up python-dotenv
!pip set up python-dotenv transformers torch
!pip set up transformers
from dotenv import load_dotenv
from transformers import pipeline
load_dotenv() # take surroundings variables from .env.
import os
import pathlib
import textwrap
from PIL import Picture
import torch
import requestsThis consists of os for interacting with the working system, pathlib for filesystem paths, textwrap for textual content wrapping and filling, PIL.Picture for opening, manipulating, and saving many various picture file codecs, torch for deep studying, and requests for making HTTP requests.
Load surroundings variables
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text",
mannequin=model_id,
model_kwargs={})
The load_dotenv() operate name masses surroundings variables from a .env file situated in the identical listing as your script. Delicate data, like an API key (api_key), is accessed with os.getenv(“hf_v”). Right here now we have not proven the total HuggingFace API key due to safety causes.
retailer API keys individually?
- Create a hidden file named .env in your challenge listing.
- Add this line to .env: API_KEY=YOUR_API_KEY_HERE (substitute along with your precise key).
- Write load_dotenv(); api_key = os.getenv(“API_KEY”)
Setting Up the Pipeline: The pipeline operate from the transformers library is used to create a pipeline for the “image-to-text” job. This pipeline is a ready-to-use software for processing photos and producing textual content descriptions.
3. Picture URL and Immediate
image_url = "https://encrypted-tbn0.gstatic.com/photos?q=tbn:ANd9GcTdtdz2p9Rh46LN_X6m5H9M5qmToNowo-BJ-w&usqp=CAU"
picture = Picture.open(requests.get(image_url, stream=True).uncooked)
picture
prompt_instructions = """
Act as an professional author who can analyze an imagery and clarify it in a descriptive approach, utilizing as a lot element as doable from the picture.The content material needs to be 300 phrases minimal. Reply to the next immediate:
""" + input_textpicture = Picture.open(requests.get(image_url, stream=True).uncooked) fetches the picture from the URL and opens it utilizing PIL. Write the immediate and what kind of rationalization is required and set the phrase restrict.
4. Output
immediate = "USER: <picture>n" + prompt_instructions + "nASSISTANT:"
print(outputs[0]["generated_text"])🖌️
Project As now we have talked about above that there are different LLaVA fashions accessible.So strive Paperspace Gradient to coach and high quality tune these newest LLaVA fashions based on the required use circumstances and see the outputs. Attempt to do efficiency comparability analysis on totally different fashions utilizing the above code.
Closing Ideas
This text explored the potential of LLaVA-1.5, showcasing its means to investigate photos and generate insightful textual content descriptions. We delved into the code used for this demonstration, offering a glimpse into the internal workings of those fashions. We additionally highlighted the provision of varied superior LLaVA fashions like LLaVA-HR and LLaVA-NeXT, encouraging exploration and experimentation.
The way forward for multimodality is brilliant, with steady developments in basis imaginative and prescient fashions and the event of much more highly effective LLMs. Paperspace Gradient stands able to empower researchers, builders, and fans to be on the forefront of those developments.
Be a part of the multimodality revolution on Paperspace Gradient. Experiment and unlock the potential of LLaVA and different cutting-edge LLMs.
Attempt H100 GPUs on Paperspace.
Additionally strive Free GPUs.