{kind=link}
Editor’s word: This publish is a part of our AI Decoded collection, which goals to demystify AI by making the know-how extra accessible, whereas showcasing new {hardware}, software program, instruments and accelerations for RTX PC and workstation customers.
If AI is having its iPhone second, then chatbots are certainly one of its first in style apps.
They’re made attainable due to massive language fashions, deep studying algorithms pretrained on huge datasets — as expansive because the web itself — that may acknowledge, summarize, translate, predict and generate textual content and different types of content material. They will run domestically on PCs and workstations powered by NVIDIA GeForce and RTX GPUs.
LLMs excel at summarizing massive volumes of textual content, classifying and mining information for insights, and producing new textual content in a user-specified type, tone or format. They will facilitate communication in any language, even past ones spoken by people, similar to pc code or protein and genetic sequences.
Whereas the primary LLMs dealt solely with textual content, later iterations had been skilled on different kinds of information. These multimodal LLMs can acknowledge and generate pictures, audio, movies and different content material kinds.
Chatbots like ChatGPT had been among the many first to carry LLMs to a client viewers, with a well-recognized interface constructed to converse with and reply to natural-language prompts. LLMs have since been used to assist builders write code and scientists to drive drug discovery and vaccine growth.
However the AI fashions that energy these features are computationally intensive. Combining superior optimization methods and algorithms like quantization with RTX GPUs, that are purpose-built for AI, helps make LLMs compact sufficient and PCs highly effective sufficient to run domestically — no web connection required. And a brand new breed of light-weight LLMs like Mistral — one of many LLMs powering Chat with RTX — units the stage for state-of-the-art efficiency with decrease energy and storage calls for.
Why Do LLMs Matter?
LLMs will be tailored for a variety of use circumstances, industries and workflows. This versatility, mixed with their high-speed efficiency, gives efficiency and effectivity positive aspects throughout just about all language-based duties.
LLMs are extensively utilized in language translation apps similar to DeepL, which makes use of AI and machine studying to supply correct outputs.
Medical researchers are coaching LLMs on textbooks and different medical information to boost affected person care. Retailers are leveraging LLM-powered chatbots to ship stellar buyer help experiences. Monetary analysts are tapping LLMs to transcribe and summarize incomes calls and different essential conferences. And that’s simply the tip of the iceberg.
Chatbots — like Chat with RTX — and writing assistants constructed atop LLMs are making their mark on each side of information work, from content material advertising and marketing and copywriting to authorized operations. Coding assistants had been among the many first LLM-powered functions to level towards the AI-assisted way forward for software program growth. Now, initiatives like ChatDev are combining LLMs with AI brokers — good bots that act autonomously to assist reply questions or carry out digital duties — to spin up an on-demand, digital software program firm. Simply inform the system what sort of app is required and watch it get to work.
Be taught extra about LLM brokers on the NVIDIA developer weblog.
Simple as Putting Up a Dialog
Many individuals’s first encounter with generative AI got here by means of a chatbot similar to ChatGPT, which simplifies using LLMs by means of pure language, making consumer motion so simple as telling the mannequin what to do.
LLM-powered chatbots may also help generate a draft of promoting copy, supply concepts for a trip, craft an e-mail to customer support and even spin up authentic poetry.
Advances in picture era and multimodal LLMs have prolonged the chatbot’s realm to incorporate analyzing and producing imagery — all whereas sustaining the splendidly easy consumer expertise. Simply describe a picture to the bot or add a photograph and ask the system to investigate it. It’s chatting, however now with visible aids.
Future developments will assist LLMs develop their capability for logic, reasoning, math and extra, giving them the power to interrupt advanced requests into smaller subtasks.
Progress can be being made on AI brokers, functions able to taking a posh immediate, breaking it into smaller ones, and interesting autonomously with LLMs and different AI programs to finish them. ChatDev is an instance of an AI agent framework, however brokers aren’t restricted to technical duties.
For instance, customers might ask a private AI journey agent to e book a household trip overseas. The agent would break that process into subtasks — itinerary planning, reserving journey and lodging, creating packing lists, discovering a canine walker — and independently execute them so as.
Unlock Private Knowledge With RAG
As highly effective as LLMs and chatbots are for basic use, they’ll turn into much more useful when mixed with a person consumer’s information. By doing so, they may also help analyze e-mail inboxes to uncover developments, comb by means of dense consumer manuals to search out the reply to a technical query about some {hardware}, or summarize years of financial institution and bank card statements.
Retrieval-augmented era, or RAG, is among the best and handiest methods to hone LLMs for a selected dataset.
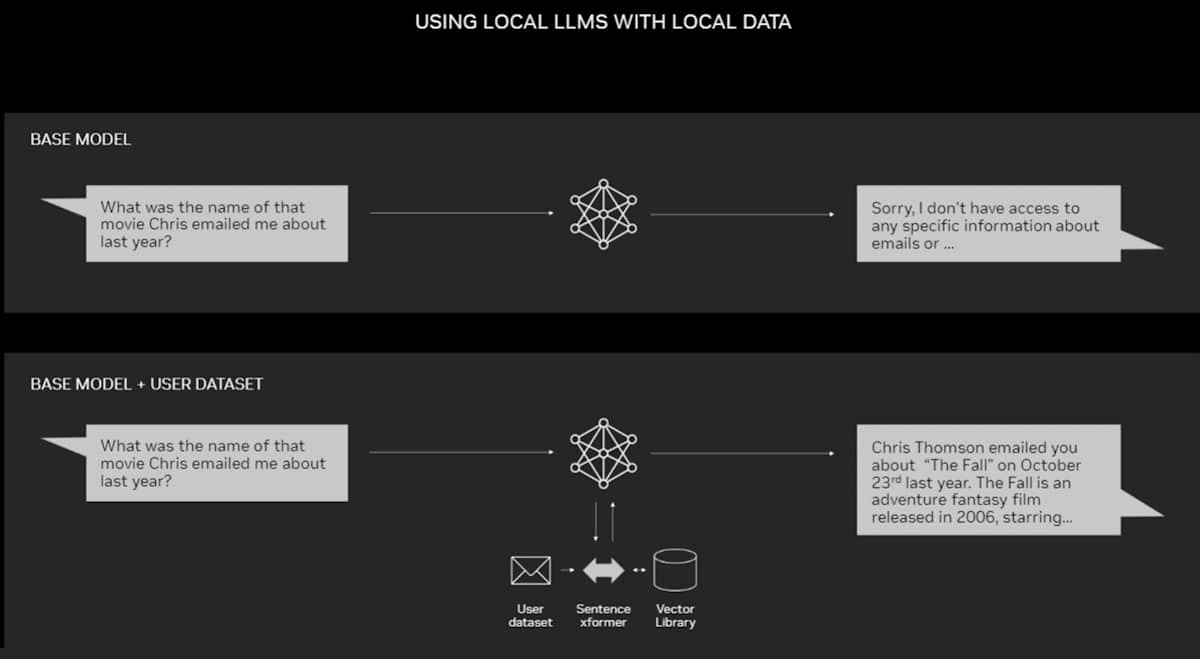
RAG enhances the accuracy and reliability of generative AI fashions with info fetched from exterior sources. By connecting an LLM with virtually any exterior useful resource, RAG lets customers chat with information repositories whereas additionally giving the LLM the power to quote its sources. The consumer expertise is so simple as pointing the chatbot towards a file or listing.
For instance, a typical LLM could have basic information about content material technique greatest practices, advertising and marketing techniques and primary insights into a selected trade or buyer base. However connecting it by way of RAG to advertising and marketing belongings supporting a product launch would enable it to investigate the content material and assist plan a tailor-made technique.
RAG works with any LLM, as the appliance helps it. NVIDIA’s Chat with RTX tech demo is an instance of RAG connecting an LLM to a private dataset. It runs domestically on programs with a GeForce RTX or NVIDIA RTX skilled GPU.
To study extra about RAG and the way it compares to fine-tuning an LLM, learn the tech weblog, RAG 101: Retrieval-Augmented Technology Questions Answered.
Expertise the Velocity and Privateness of Chat with RTX
Chat with RTX is an area, personalised chatbot demo that’s simple to make use of and free to obtain. It’s constructed with RAG performance and TensorRT-LLM and RTX acceleration. It helps a number of open-source LLMs, together with Meta’s Llama 2 and Mistral’s Mistral. Help for Google’s Gemma is coming in a future replace.
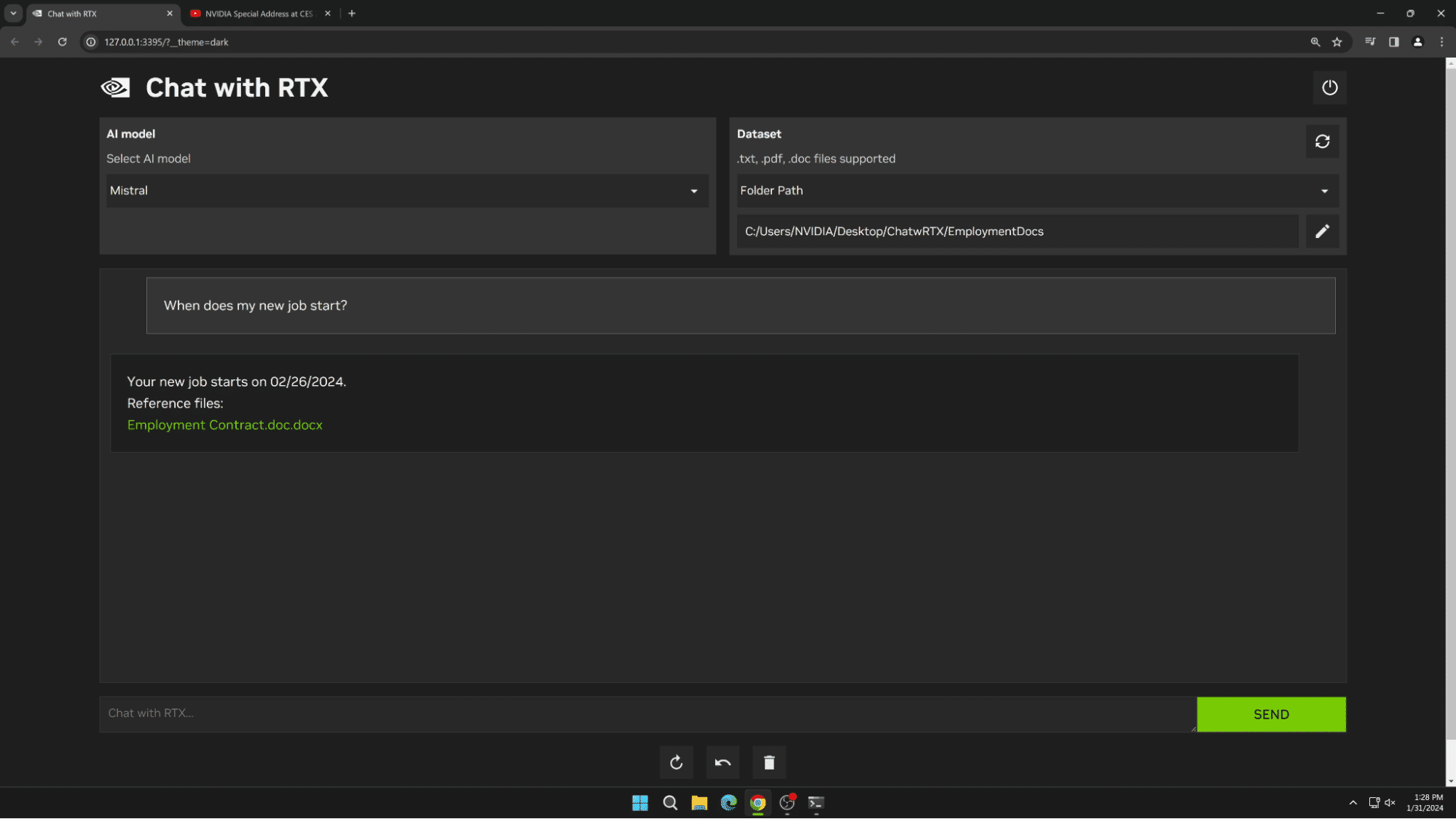
Customers can simply join native information on a PC to a supported LLM just by dropping information right into a folder and pointing the demo to that location. Doing so allows it to reply queries with fast, contextually related solutions.
Since Chat with RTX runs domestically on Home windows with GeForce RTX PCs and NVIDIA RTX workstations, outcomes are quick — and the consumer’s information stays on the system. Quite than counting on cloud-based companies, Chat with RTX lets customers course of delicate information on an area PC with out the necessity to share it with a 3rd social gathering or have an web connection.
To study extra about how AI is shaping the longer term, tune in to NVIDIA GTC, a world AI developer convention working March 18-21 in San Jose, Calif., and on-line.