{kind=link}
Within the good outdated days, databases had a comparatively easy job: assist with the month-to-month billing, ship some reviews, perhaps reply some advert hoc queries. Databases have been vital, however they weren’t in fixed demand.
Right this moment the image is completely different. Databases are sometimes tasked with powering enterprise operations and hyperscale on-line providers. The stream of transactions is incessant, and response occasions must be near-instantaneous. On this new paradigm, companies aren’t simply knowledgeable by their database—they’re basically constructed on it. Choices are made, methods are drafted, and providers are customized in actual time based mostly on huge streams of information.
Relational databases sit on the epicenter of this seismic shift. Their function transcends storage. It extends to processing advanced transactions, implementing enterprise logic, and serving real-time analytical insights. The structured nature of relational databases, coupled with the innate capability to make sure the atomicity, consistency, isolation, and sturdiness (ACID) of transactions, makes them indispensable in a world the place knowledge kinds the core of enterprise methods.
To satisfy the calls for of recent purposes, relational databases want a radically new structure. The should be designed from the bottom as much as deal with voluminous knowledge and transaction masses, resist various kinds of failure, and performance seamlessly throughout occasions of peak demand with out handbook intervention or patchwork scaling methods.
This structure should be intrinsically scalable and dependable. These two qualities can’t be bolted on. They need to be elementary to the design. Scalability permits the database to effectively accommodate fluctuating workloads. Reliability ensures constant efficiency, stopping knowledge loss or downtime that might critically impinge enterprise operations or decision-making.
TiDB is a chief instance of this new database structure. It’s an open-source distributed SQL database designed for probably the most demanding purposes, scaling out to deal with knowledge volumes as much as a petabyte in dimension. On this article we’ll discover the architectural options that give TiDB its scalability and reliability.
 PingCAP
PingCAPTiDB design fundamentals
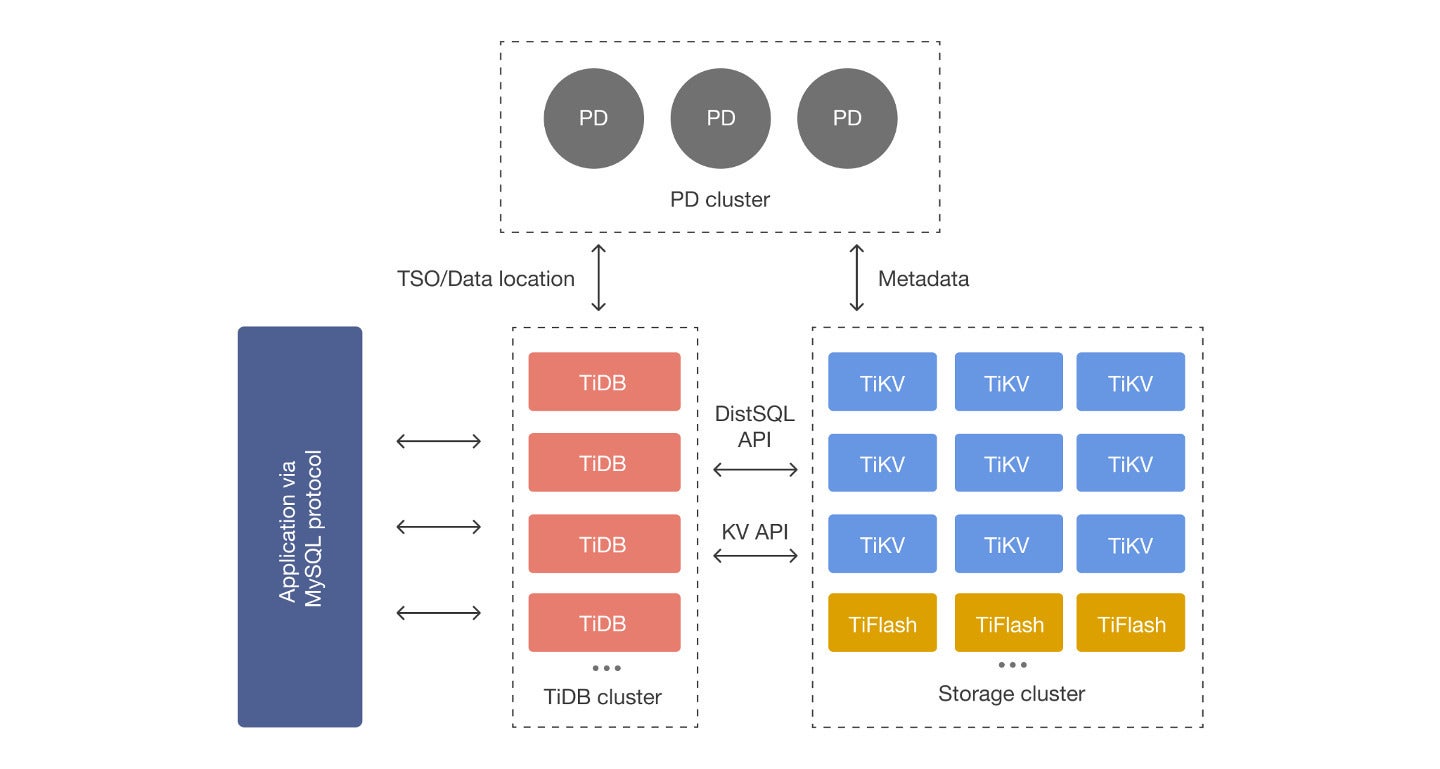
A cornerstone of TiDB’s structure is its decoupling of storage and compute. Every of these two elements can scale independently, guaranteeing optimum useful resource allocation and efficiency at the same time as knowledge wants evolve. This permits organizations to take advantage of environment friendly use of their {hardware}, enhancing cost-effectiveness and operational effectivity.
One other key design aspect is TiDB’s assist for native horizontal scaling, or scale-out. Conventional transactional databases battle with growing knowledge volumes and question masses. The best resolution is to scale up—mainly, to modify to extra highly effective {hardware}. Nonetheless, there are limitations on the {hardware} of a single machine. TiDB robotically scales out to accommodate development in transactions and knowledge volumes. By including new nodes to the system, TiDB retains efficiency and availability constant, at the same time as knowledge and consumer calls for enhance.
One other profit to native horizontal scaling is that it eliminates the necessity for advanced, disruptive sharding operations. The concept behind sharding is to hurry up transactions and enhance reliability by splitting the database into smaller, extra manageable chunks, saved in separate database situations on separate bodily media. In apply, sustaining a sharded system includes untold hours of handbook work to maintain every of the shards in optimum situation. Native horizontal scaling eliminates this burden. The database grows as wanted, permitting it to handle surprising spikes in demand—say, a surge in e-commerce visitors on Black Friday.
 PingCAP
PingCAPTiKV is TiDB’s distributed, transactional, key-value storage engine. TiKV shops knowledge in key-value format. It will probably cut up the information into small chunks robotically and unfold the chunks among the many nodes in accordance with the workload, accessible disk area, and different components. TiDB leverages the Raft consensus algorithm in its replication mannequin to make sure robust consistency and excessive availability for the information chunks.
The Raft algorithm and replication in TiDB
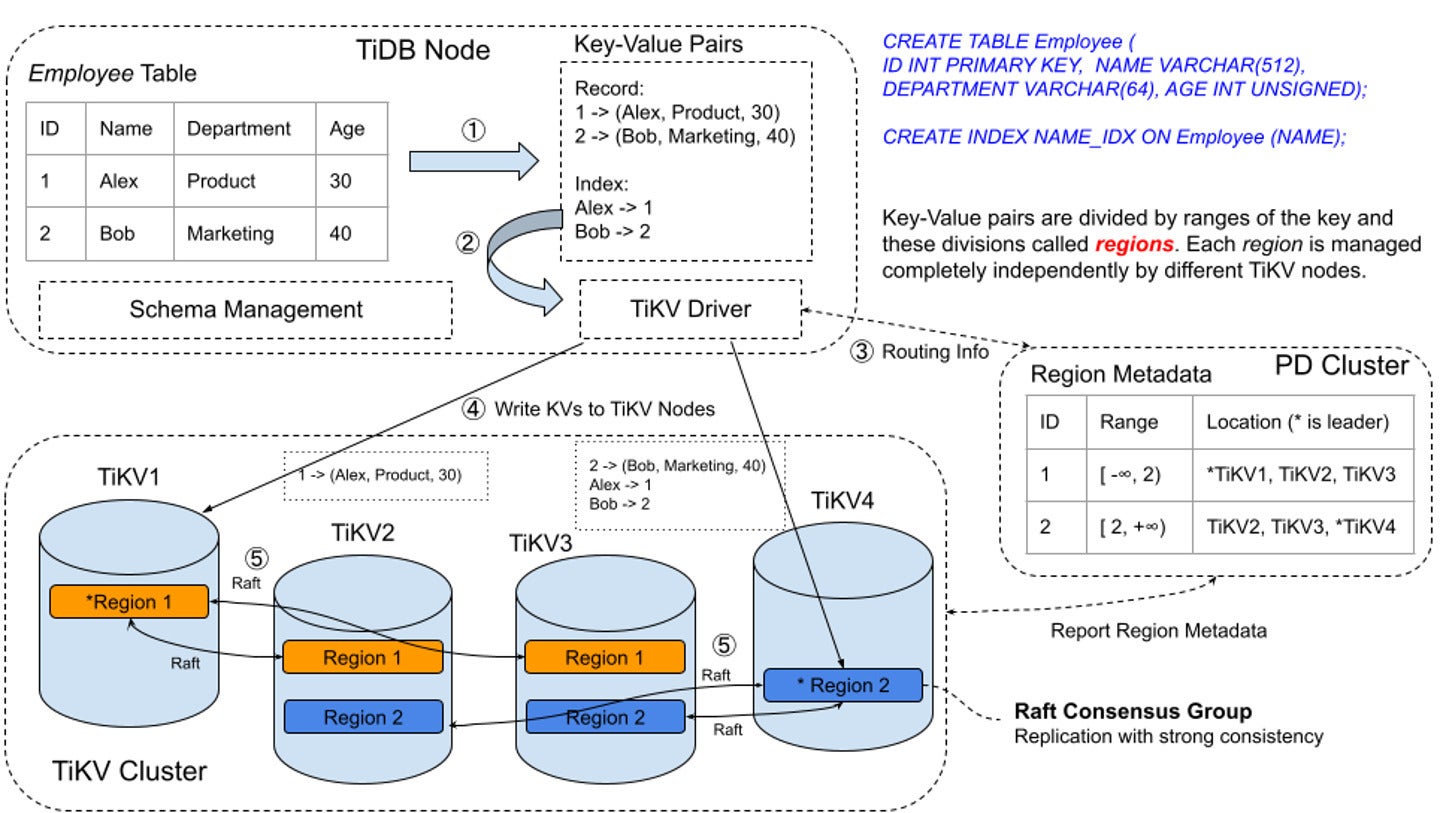
The Raft consensus algorithm is one other vital constructing block in TiDB’s structure. TiDB makes use of Raft to handle the replication and consistency of information, guaranteeing the information behaves as if it have been saved on a single machine though it’s distributed throughout a number of nodes.
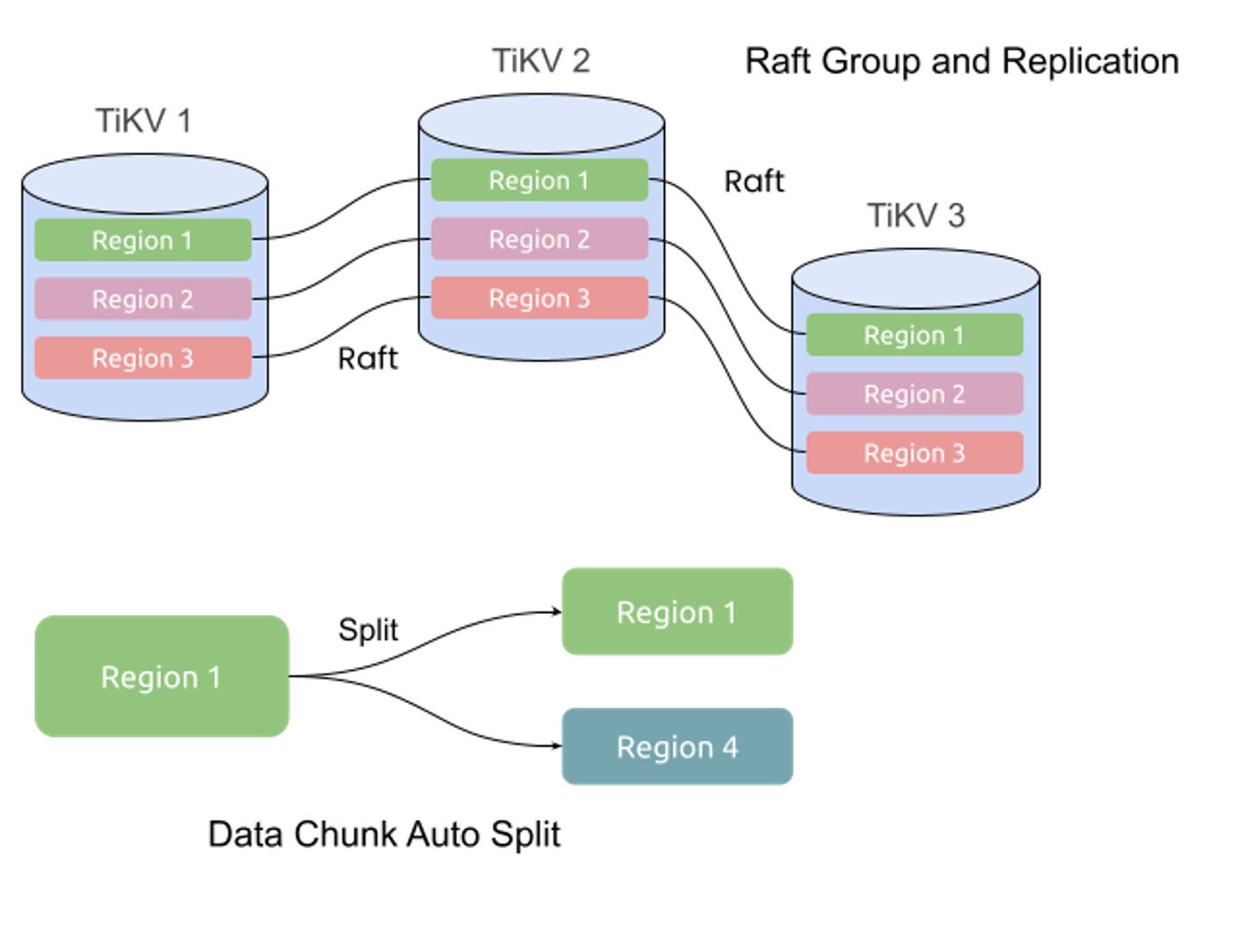
Right here’s the way it works. TiDB breaks down knowledge into small chunks referred to as areas. Every area acts as a Raft group, and might be cut up into a number of areas as knowledge volumes and workloads change. When knowledge is written to the TiDB cluster, it’s written to the chief node of the area. The Raft protocol ensures the information is replicated to follower nodes by way of log replication, sustaining knowledge consistency throughout a number of replicas.
Initially, when a TiDB cluster is small, knowledge is contained inside a single area. Nonetheless, as extra knowledge is added, TiDB robotically splits the area into a number of areas, permitting the cluster to scale horizontally. This course of is named auto-sharding, and it’s essential to making sure that TiDB can deal with massive quantities of information effectively.
 PingCAP
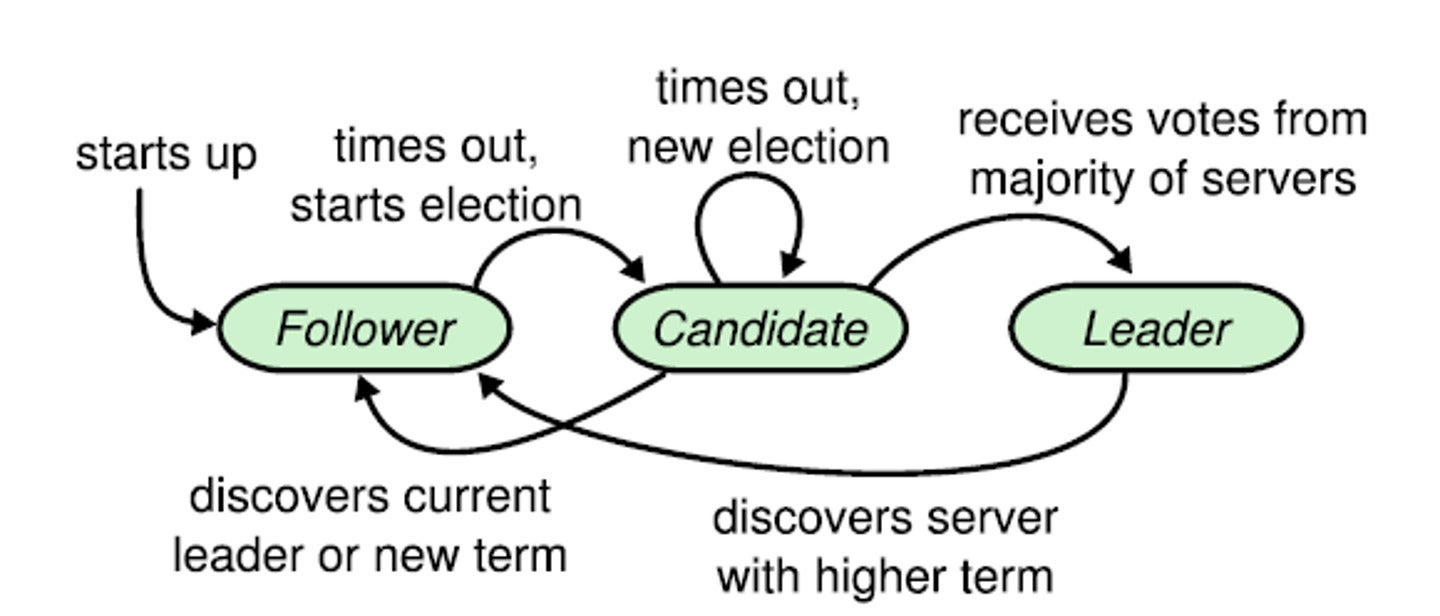
PingCAPIf the chief fails, Raft ensures that one of many followers might be elected as the brand new chief, guaranteeing excessive availability. Raft additionally offers robust consistency, guaranteeing that each duplicate holds the identical knowledge at any given time. This permits TiDB to copy knowledge constantly throughout all nodes, making it resilient to node failures and community partitions.
 PingCAP
PingCAPOne of many key advantages of TiDB’s auto-split and merge mechanism is that it’s fully clear to the purposes utilizing the database. The database robotically reshards knowledge and redistributes it throughout your complete cluster, negating the necessity for handbook sharding schemes. This results in each lowered complexity and lowered potential for human error, whereas additionally releasing up useful developer time.
By implementing the Raft consensus algorithm and knowledge chunk auto-split, TiDB ensures strong knowledge consistency and excessive availability whereas offering scalability. This seamless mixture permits companies to deal with deriving actionable insights from their knowledge, relatively than worrying in regards to the underlying complexities of information administration in distributed environments.
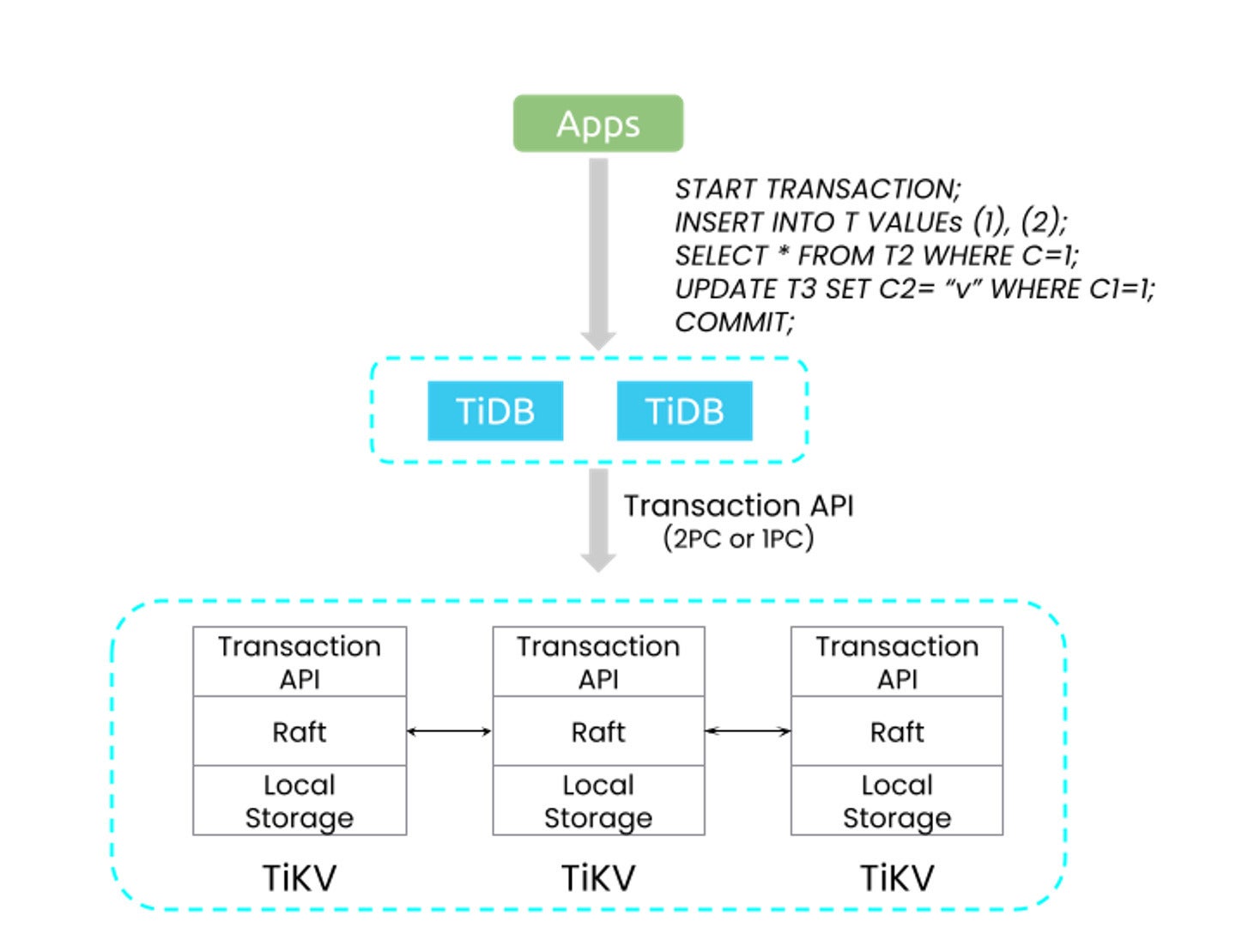
Distributed transactions in TiDB
One other constructing block of TiDB’s distributed structure is distributed transactions, sustaining the important ACID (atomicity, consistency, isolation, and sturdiness) properties elementary to relational databases. This functionality ensures that operations on knowledge are reliably processed and the integrity of information is upheld throughout a number of nodes within the cluster.
 PingCAP
PingCAPTiDB’s native assist for distributed transactions is clear to purposes. When an utility performs a transaction, TiDB robotically takes care of distributing the transaction throughout the concerned nodes. There’s no want for builders to write down advanced, error-prone, distributed transaction management logic within the utility layer. Furthermore, TiDB employs robust consistency, which means the database ensures that each learn receives the newest write, or an error within the case of ongoing conflicting transactions.
As a result of distributed transactions are natively supported by the TiKV storage engine, each node within the SQL layer can operate as each a reader and a author. This design eliminates the necessity for a chosen main node for writes, thereby enhancing the database’s horizontal scalability and eliminating potential bottlenecks or single factors of failure. It is a vital benefit in contrast with methods that obtain scale by leveraging separate nodes to scale reads, whereas nonetheless utilizing a single node to write down. By eliminating the single-writer subject, TiDB achieves orders-of-magnitude larger TPS.
In discussing scalability, it’s crucial to look past knowledge volumes and queries per second (QPS). Additionally vital is the power to deal with unpredictable workloads and implement clever scheduling. TiDB is designed to anticipate and adapt to various workload varieties and sudden demand surges. Its scheduling algorithms dynamically allocate assets, optimize job administration, and forestall efficiency bottlenecks, guaranteeing constant and environment friendly operation.
TiDB’s method to scalability can also be evident in its dealing with of large-scale database operations. TiDB’s structure streamlines database definition language (DDL) duties, which are sometimes a bottleneck in massive, advanced methods. This ensures that at the same time as a TiDB database grows, operations like schema modifications carry out effectively.
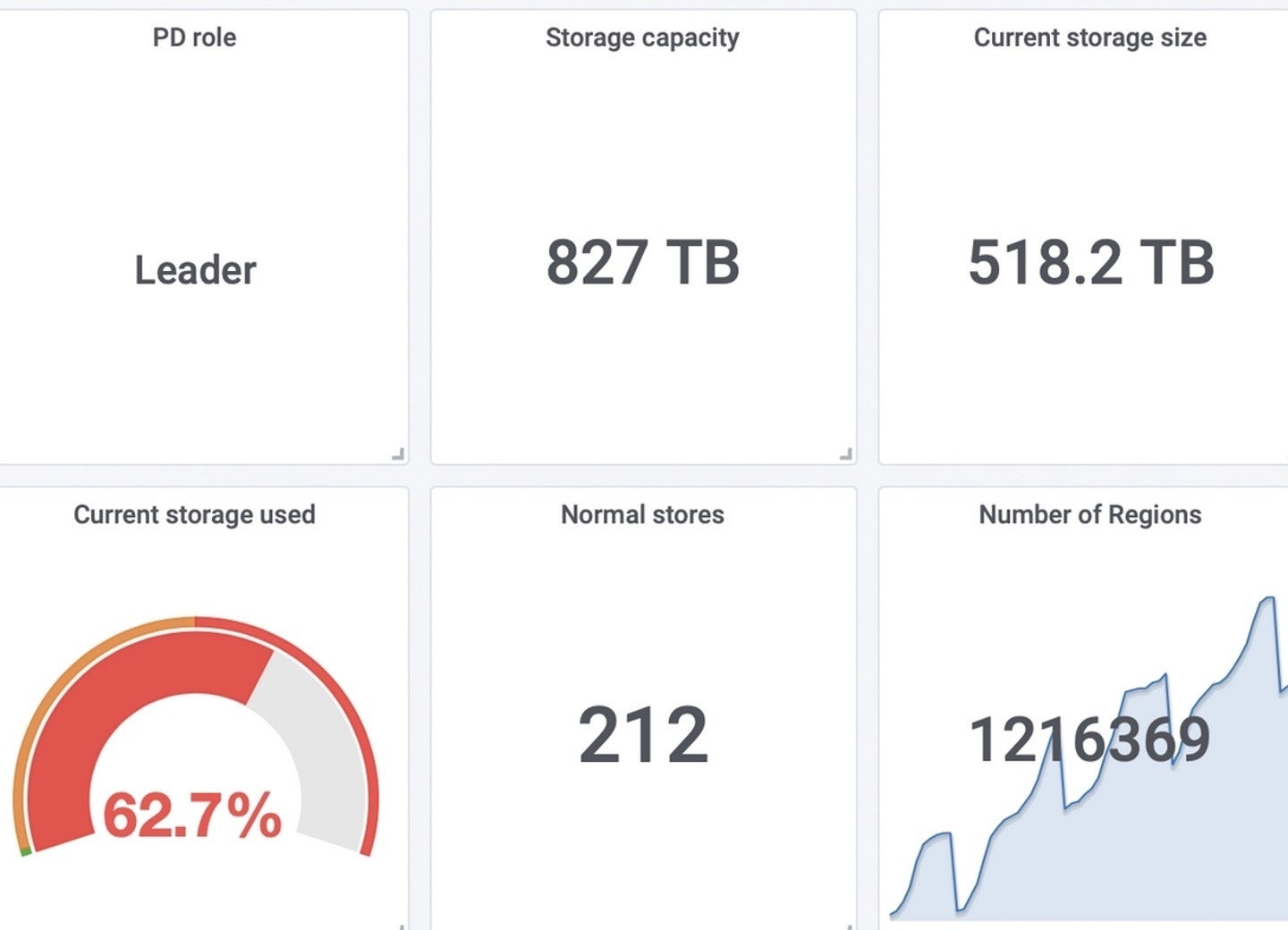
Right here I’ll level you to 2 real-world examples of TiDB scalability. The primary instance reveals a single TiDB cluster managing 500TB of information, encompassing 1.3 trillion information. The diagram beneath is the screenshot of the TiDB cluster monitoring dashboard.
 PingCAP
PingCAPThe second instance, from Flipkart, the biggest e-commerce firm in India, reveals a TiDB cluster scaling to 1 million QPS. In contrast with Flipkart’s earlier resolution, TiDB achieves higher efficiency and reduces cupboard space by 82%.
Reliability in TiDB
Functions and providers depend upon uninterrupted operation and strong knowledge safety. With out them, customers will shortly lose religion within the utility of the database system and its output.
TiDB presents native assist for top availability to attenuate downtime for vital purposes and providers. It additionally offers options and instruments for fast restoration of information within the occasion of a serious outage.
Replication and duplicate placement
We now have mentioned how TiDB makes use of the Raft algorithm to realize robust, constant replication. The placement of replicas might be outlined in varied methods relying on the topology of the community and the kinds of failures customers wish to guard in opposition to.
Typical situations supported by TiDB embody:
- Working completely different servers inside a single rack to mitigate server failures
- Working completely different servers on completely different racks inside a knowledge heart to mitigate rack energy and community failures
- Working completely different servers in completely different availability zones (AZ) to mitigate zone outages
With a knowledge placement scheduling framework, TiDB can assist the wants of various knowledge methods.
Auto-healing
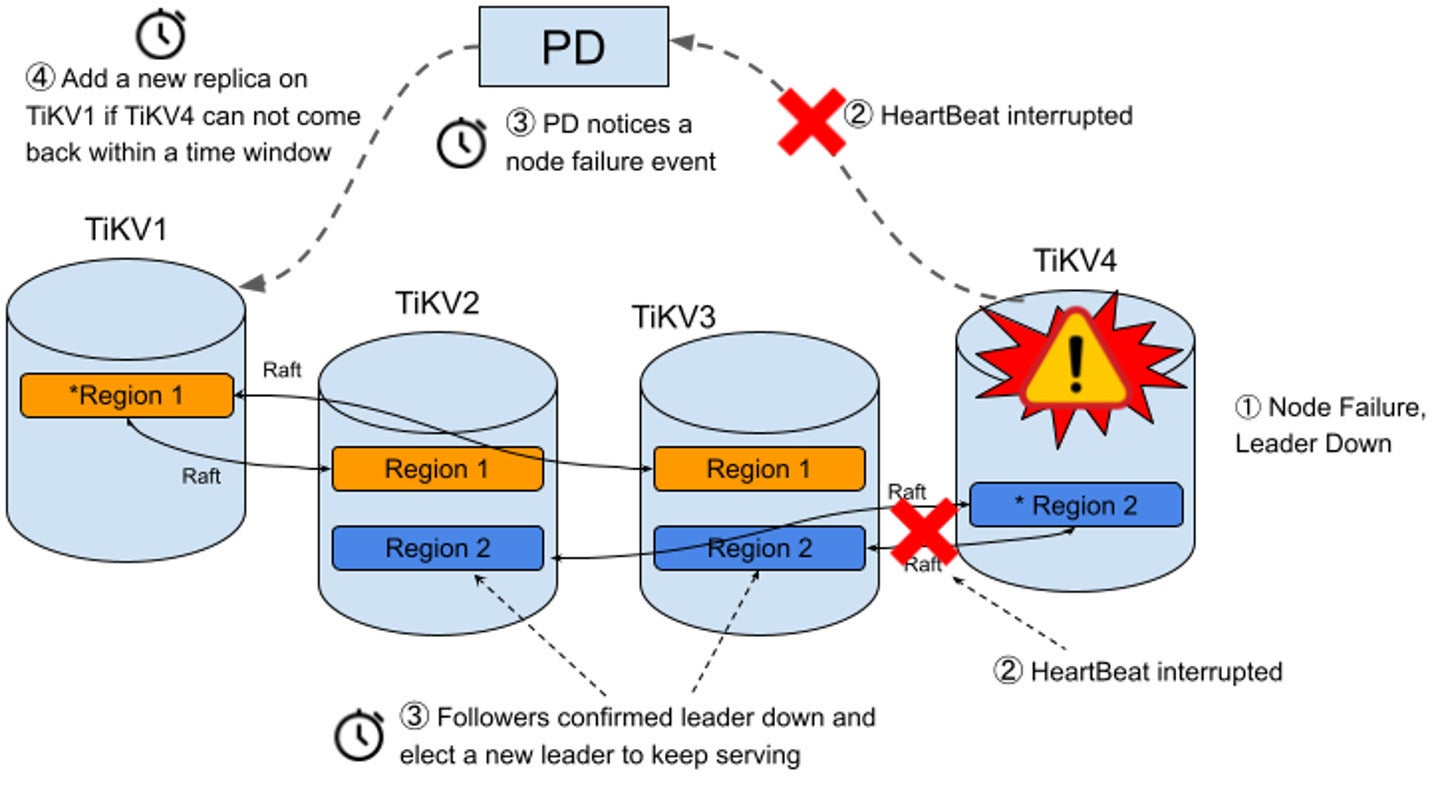
For brief-term failures, similar to a server restart, TiDB makes use of Raft to proceed seamlessly so long as a majority of replicas stay accessible. Raft ensures {that a} new “chief” for every group of replicas is elected if the previous chief fails in order that transactions can proceed. Affected replicas can rejoin their group as soon as they’re again on-line.
For longer-term failures (the default timeout is half-hour), similar to a zone outage or a server taking place for an prolonged time frame, TiDB robotically rebalances replicas from the lacking nodes, leveraging unaffected replicas as sources. By utilizing capability data from the storage nodes, TiDB identifies new areas within the cluster and re-replicates lacking replicas in a distributed style, utilizing all accessible nodes and the mixture disk and community bandwidth of the cluster.
 PingCAP
PingCAPCatastrophe restoration
Along with Raft, TiDB offers a variety of instruments and options for catastrophe restoration together with knowledge mirroring, fast error rectification, steady knowledge backups, and full-scale restoration.
- TiCDC (change knowledge seize): TiCDC mirrors modifications in actual time from the first database to at least one downstream, facilitating a primary-secondary replication setup. Within the occasion of a main server failure, TiCDC ensures minimal knowledge loss, as transactions are frequently replicated. This technique not solely aids in catastrophe restoration but additionally helps in balancing masses and offloading learn operations. The reside mirroring of information modifications is especially essential for purposes requiring excessive availability, because it ensures the secondary setup can promptly take over with little to no downtime.
- Flashback: TiDB’s Flashback function offers safety from one of the unpredictable causes of catastrophe: human error. Flashback permits the database to be restored to a selected cut-off date throughout the rubbish assortment (GC) lifetime, so errors similar to unintended knowledge deletion or faulty updates might be swiftly rectified with out in depth downtime, sustaining operational continuity and consumer belief.
- PiTR (point-in-time restoration): PiTR frequently backs up knowledge modifications, enabling restoration of the cluster to a selected cut-off date. That is essential not just for catastrophe restoration, but additionally for enterprise audits, providing the power to evaluate historic knowledge states. PiTR offers a further layer of information safety, preserving enterprise continuity and aiding with regulatory compliance.
- Full Backup and Restore: Along with the aforementioned instruments for particular use instances, TiDB is supplied with a complete Full Backup and Restore function, which offers the means to rebuild your complete cluster if obligatory. In catastrophic failure situations, the place knowledge buildings are compromised or a good portion of information is corrupted, a full backup is indispensable. It ensures providers might be restored to normalcy within the shortest time attainable, offering a sturdy security internet for worst-case situations.
A database designed for change
The enterprise world revolves round knowledge. The worldwide surge in on-line monetary transactions, fueled by enterprise fashions like pay-as-you-go, has created an unprecedented demand for efficiency, together with the reassurance that that efficiency might be there when it’s wanted.
A distributed SQL database is what you get if you redesign relational databases across the concept of change. As the muse for enterprise purposes, databases should be capable to adapt to the surprising, whether or not it’s surprising development, surprising visitors, or surprising catastrophes.
All of it comes again to scale and reliability, the capability to carry out and the belief in efficiency. Scale provides customers the power to make issues the world has by no means seen earlier than. Reliability provides them the religion that what they construct will preserve working. It’s what turns a prototype right into a worthwhile enterprise. And on the coronary heart of the enterprise, behind the acquainted SQL interface, is a brand new structure for a world the place knowledge is paramount.
Li Shen is senior vice chairman at PingCAP, the corporate behind TiDB.
—
New Tech Discussion board offers a venue for expertise leaders—together with distributors and different outdoors contributors—to discover and focus on rising enterprise expertise in unprecedented depth and breadth. The choice is subjective, based mostly on our decide of the applied sciences we imagine to be vital and of best curiosity to InfoWorld readers. InfoWorld doesn’t settle for advertising and marketing collateral for publication and reserves the fitting to edit all contributed content material. Ship all inquiries to doug_dineley@foundryco.com.
Copyright © 2024 IDG Communications, Inc.