{kind=link}
Introduction
How does your telephone predict your subsequent phrase, or how does a web-based device fine-tune your emails effortlessly? The powerhouse behind these conveniences are Giant Language Fashions. However what precisely are these LLMs, and why are they changing into a scorching matter of dialog?
The worldwide marketplace for these superior methods hit a whopping $4.35 billion in 2023 and is predicted to continue to grow at a fast 35.9% yearly from 2024 to 2030. One huge cause for this surge? LLMs can be taught and adapt themselves with none human supervision. It’s fairly spectacular stuff! However with all of the hype, it’s pure to have questions. Whether or not you’re a scholar, an expert, or somebody who loves exploring digital improvements, this text solutions all of your widespread questions round LLMs.
Why ought to I find out about LLMs?
Most of us are interacting with the under screens virtually every day, aren’t we?

And, I typically use it for taking assist for numerous duties like:
- Re-writing my emails
- Take a begin on my preliminary ideas on any potential concepts
- Have additionally experimented with an concept that these instruments could be my mentor or coach as nicely?
- Taking abstract for analysis paper and larger paperwork as nicely. And there’s a lengthy listing.
However, are you aware how these instruments are capable of remedy all several types of issues? I believe most of us know the reply. Sure, it’s utilizing “Giant Language Fashions (LLMs)”.
There are broadly 4 kinds of customers of LLMs or Generative AI.
- Person: Work together with above screens and get their responses.
- Tremendous Person: Generate extra out of those instruments by making use of the appropriate strategies. They will generate responses primarily based on their requirement by giving the appropriate context or data often known as immediate.
- Developer: Construct or modify these LLMs for his or her particular want utilizing strategies like RAG or Positive-tuning.
- Researcher: Innovate and construct advanced variations of LLMs.
I believe all consumer varieties ought to have a broad understanding about “What’s LLM?” nonetheless for consumer class two, three and 4, for my part it’s a should to know. And, as you progress in the direction of the Tremendous Person, Developer and Researcher class, it’ll begin changing into extra important to have a deeper understanding about LLMs.
You may as well observe Generative ai studying path for all consumer classes.
Generally identified LLMs are GPT 3, GPT 3.5, GPT 4, Palm, Palm 2, Gemini, Llama, Llama 2 and lots of others. Let’s perceive what LLM is.
What’s a Giant Language Mannequin (LLM)?
Let’s break down what Giant Language Fashions into “Giant” and “Language Fashions”. Language fashions assign possibilities to teams of phrases in sentences primarily based on how possible these phrase combos happen within the language.
Contemplate these sentences
- Sentence 1: “You might be studying this text”,
- Sentence 2: “Are we studying article this?” and,
- Sentence 3: “Most important article padh raha hoon” (in Hindi).
The language mannequin assigns the very best chance to the primary sentence (round 85%) as it’s extra prone to happen in English. The second sentence, deviating from grammatical sequence, will get a decrease chance (35%), and the third, being in a special language, receives the bottom chance (2%). And that is what precisely these language fashions do.

The language fashions assign the upper chance to the group of phrases, which is extra prone to happen within the language primarily based on the information they’ve seen up to now. These fashions work by predicting the subsequent almost definitely phrase to happen following the earlier phrases. Now that the language mannequin is evident, you’ll be asking what’s “Giant” right here?
Prior to now, fashions have been skilled on small datasets with fewer parameters (weights and biases of the neural community). Fashionable LLMs are 2000 occasions bigger, with billions of parameters. Researchers discovered that rising mannequin dimension and coaching information makes these fashions smarter and approaching human-level intelligence.

So, a big language mannequin is one with an infinite variety of parameters, skilled on web scale datasets. Not like common language fashions, LLMs not solely be taught language possibilities but additionally acquire clever properties. They turn into methods that may suppose, innovate, and talk like people.
For example, GPT-3, with 175 billion parameters, can carry out duties past predicting the subsequent phrase. It positive aspects emergent properties throughout coaching, permitting it to unravel numerous duties, even ones it wasn’t explicitly skilled for, like machine translation, summarization, translation, classification and lots of extra.
How can I construct purposes utilizing LLM?
Now we have lots of of LLM-driven purposes. A number of the commonest examples embrace GitHub Copilot, a broadly used device amongst builders. GitHub Copilot streamlines coding processes, with greater than 37,000 companies and one in each three Fortune 500 firms adopting it. This highly effective device enhances developer productiveness by over 50%.

One other one is Jasper.AI. It transforms content material creation. With this LLM-powered assistant, customers can generate high-quality content material for blogs and e-mail campaigns immediately and successfully.

Chat PDF introduces a singular method to work together with PDF paperwork, permitting customers to have conversations about analysis papers, blogs, books, and extra. Think about importing your favourite e book and interesting whereas interacting in chat format.

There are 4 completely different strategies to construct LLM purposes:
- Immediate Engineering: Immediate engineering is like giving clear directions to LLM or generative AI primarily based instruments to get correct responses.
- Retrieval-Augmented Technology (RAG): On this methodology, we mix information from exterior sources with LLM to get a extra correct and related end result.
- Positive-Tuning Fashions: On this methodology, we personalized a pre-trained LLM for a website particular activity. For instance: Now we have wonderful tuned “Llama 2” on code associated information to construct “Code Llama” and “Code Llama” outperforms “Llama 2” on coding associated duties as nicely.
- Coaching LLMs from Scratch: On this methodology, we wish LLMs like GPT-3.5, Llama, Falcon and so forth. In easy phrases, right here we prepare a language mannequin on a big quantity of information.
What’s Immediate Engineering?
We get responses from ChatGPT-like instruments by giving textual enter. This enter is named “Immediate”.
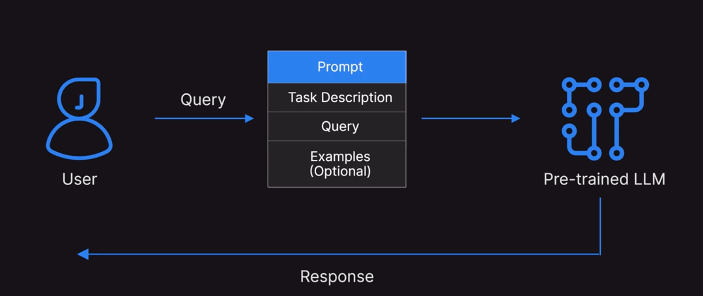
We regularly observe that response adjustments in the event you change our enter. And, primarily based on the standard of enter or immediate we get higher and related responses. Penning this high quality immediate to get desired response is named Immediate Engineering. And, Immediate Engineering is an iterative course of. We first write a immediate after which have a look at the response and publish that we modify or add extra context to enter and be extra particular to get the specified response.
Sorts of Immediate Engineering
Zero Shot Prompting
In my opinion, all of us have already used this methodology of prompting. Right here we’re simply attempting to get a response from LLM primarily based on its current information.

Few pictures Prompting
On this method, we offer a couple of examples to LLM earlier than on the lookout for a response.

You may examine the end result with zero shot and few pictures prompting.
Chain of ideas Prompting
In easy phrases, Chain-of-Thought (CoT) prompting is a technique used to assist language fashions to unravel tough issues. On this methodology, we aren’t solely offering examples but additionally break down the thought course of step-by-step. Take a look at the under instance:
What’s RAG and the way is it completely different from Immediate Engineering?
What do you suppose? Will you get the appropriate reply to all of your questions from ChatGPT or related instruments? No, due to just one cause. LLM behind ChatGPT isn’t skilled on the dataset that has the appropriate reply to your query or question.
Presently ChatGPT information base is restricted until January 2022, and in the event you ask any query past this timeline chances are you’ll get an invalid or non-relevant consequence.
Equally, in the event you ask questions associated to non-public data particular to enterprise information, you’ll once more get an invalid or non-relevant response.
Right here, RAG involves rescue you!
It helps us to mix information from exterior sources with LLM to get a extra correct and related end result.
Take a look at the under picture the place it follows the next steps to supply a related and legitimate response.
- Person Question first goes to a RAG primarily based system the place it fetches related data from exterior information sources.
- It combines Person question with related data from exterior supply and ship it to LLM
- Step 3: LLM generates responses primarily based on each information of LLM and information from exterior information sources.

At a excessive degree, you’ll be able to say that RAG is a way that mixes immediate engineering with content material retrieval from exterior information sources to enhance the efficiency and relevance of LLMs.
What’s fine-tuning of LLMs and what are the benefits of fine-tuning a LLM over a RAG primarily based system?
Let’s perceive a enterprise case. We need to work together with LLM for queries associated to the pharma area. LLMs like GPT 3.5, GPT 4, Llama 2 and others can reply to common queries and should reply to Pharma associated queries as nicely however do these LLMs have adequate data to supply the appropriate response? My view is, if they don’t seem to be skilled on Pharma associated information, then they will’t provide the proper response.
On this case, we will have a RAG primarily based system the place we will have Pharma information as an exterior supply and we will begin querying with it. Nice. This can undoubtedly offer you a greater response. What if we need to deliver massive quantity data associated to pharma area within the RAG system right here we’ll battle.
In a RAG primarily based system, we will deliver lacking information via exterior information sources. Now the query is how a lot data you’ll be able to have as an exterior supply. It’s restricted and as you enhance the scale of exterior information sources, efficiency typically decreases.
Second problem is retrieving the appropriate paperwork from an exterior supply can also be a activity and we’ve got to be correct to get the appropriate response and we’re bettering on this half day-on-day.
We are able to remedy this problem utilizing the Positive-tuning LLM methodology. Positive-tuning helps us customise a pre-trained LLM for a website particular activity. For instance: Now we have wonderful tuned “Llama 2” on code associated information to construct “Code Llama” and “Code Llama” outperforms “Llama 2” on coding associated duties as nicely.

For Positive-tuning, we observe under steps:
- Take a pre-trained LLM (Like Llama 2) and parameters
- Retrain the parameters of a pre-trained mannequin on area particular dataset. This can give us Finetuned LLM retrained on area particular information
- Now, consumer can work together with Finetuned LLM.

Broadly, there are two strategies of wonderful tuning LLMs.
- Full Positive-tuning: Retrain all parameter of pre-trained LLM results in extra time and extra computation
- Parameter Environment friendly Positive-Tuning (PEFT): Fraction of parameters skilled on our area particular dataset.There are completely different strategies for PEFT.
Ought to we think about coaching a LLM from scratch?
Let’s first perceive what can we imply by “Coaching LLM from scratch” publish that we are going to have a look at why we must always think about it as an possibility?
Coaching LLM from scratch refers to constructing the pre-trained LLMs just like the GPT-3, GPT-3.5, GPT-4, Llama-2, Falcon and others. The method of coaching LLM from scratch can also be known as pre-training. Right here we prepare LLM on the large scale of web information with coaching goal is to foretell the subsequent phrase of their textual content.

Coaching your individual LLMs offers you greater efficiency to your particular area. It’s a difficult activity. Let’s discover these challenges individually.
- Firstly, a considerable quantity of coaching information is required. Few examples like GPT-2, utilized 4.5 GBs of information, whereas GPT-3 employed a staggering 517 GBs.
- Second is compute energy. It calls for important {hardware} assets, notably a GPU infrastructure. Right here is a few examples:
- Llama-2 was skilled on 2048 A100 80 GB GPUs with a coaching time of roughly 21 days for 1.4 trillion tokens or one thing like that.

Researchers have calculated that GPT-3 was skilled utilizing 1024 A100 80 GB GPUs for as little as 34 days

Think about, if we’ve got to coach GPT-3 on a single V100 Nvidia GPU. Are you able to guess the time
it might take to coach it? Coaching GPT-3 with 175 billion parameters would require about 355 years to coach.
This clearly reveals that we would wish a parallel and distributed structure for coaching these fashions. And, on this methodology the fee incurred may be very excessive in comparison with Positive tunning, RAG and different strategies.
Above all, you additionally want a Gen AI scientist who can prepare LLM from scratch successfully.
So, earlier than going forward with fascinated by constructing your individual LLM, I’d suggest you to suppose a number of occasions earlier than going forward with this selection as a result of it’ll require following:
- Hundreds of thousands of {dollars}
- Gen AI Scientist
- Large dataset with top quality (essential)
Now coming to the important thing benefits of coaching your individual LLMs:
- Having the area particular aspect improves the efficiency of the area associated duties
- It additionally permits you an independence.
- You aren’t sending your information via API out of your server.
Conclusion
Via this text, we’ve uncovered the layers of LLMs, revealing how they work, their purposes, and the artwork of leveraging them for inventive and sensible functions. But, as complete as our exploration has been, it feels we’re solely scratching the floor.
So, as we conclude, let’s view this not as the top however as an invite to proceed exploring, studying, and innovating with LLMs. The questions answered on this article present a basis, however the true journey lies within the questions which can be but to ask. What new purposes will emerge? How will LLMs proceed to evolve? And the way will they additional change our interplay with know-how?
The way forward for LLMs is sort of a large, unexplored map, and it’s calling us to be the explorers. There are not any limits to the place we will go from right here.
Should you’ve bought questions effervescent up, concepts you’re itching to share, or only a thought that’s been nagging at you, drop it within the feedback.
Let’s hold the dialog going!
I’m a Enterprise Analytics and Intelligence skilled with deep expertise within the Indian Insurance coverage trade. I’ve labored for numerous multi-national Insurance coverage firms in final 7 years.