{kind=link}
We run giant language mannequin (LLM) pretraining and finetuning end-to-end utilizing Paperspace by DigitalOcean’s multinode machines with H100 GPUs. 4 nodes of H100×8 GPUs present as much as 127 petaFLOPS of compute energy, enabling us to pretrain or finetune full-size state-of-the-art LLMs in only a few hours.
On this blogpost, we present how this course of proceeds in follow end-to-end, and the way you can also run your AI and machine studying on DigitalOcean.
In a earlier publish, we confirmed the right way to finetune MosaicML’s MPT-7B mannequin on a single A100-80G×8 node, strolling via the method whereas offering some context on LLMs, information preparation, licensing, mannequin analysis and mannequin deployment, alongside the same old coaching part.
Right here, we construct upon this to extend our mannequin dimension to MPT-30B, add mannequin pretraining with MPT-760m, and replace our {hardware} from single node A100-80G×8 to multinode H100×8.
H100s on DigitalOcean
Following their launch on January 18th, Paperspace by DigitalOcean (PS by DO) now provides entry to Nvidia H100 GPUs, in both H100×1 or H100×8 configurations.
This gives quite a few advantageous options for the consumer:
- Skill to make use of this state-of-the-art Nvidia GPU
- Easy accessibility to GPUs, because it was on Paperspace
- Simplicity of use by way of DigitalOcean’s cloud
- Excessive reliability and availability
- Prepared-to-go AI/ML software program stack by way of ML-in-a-Field
- Complete and responsive buyer assist
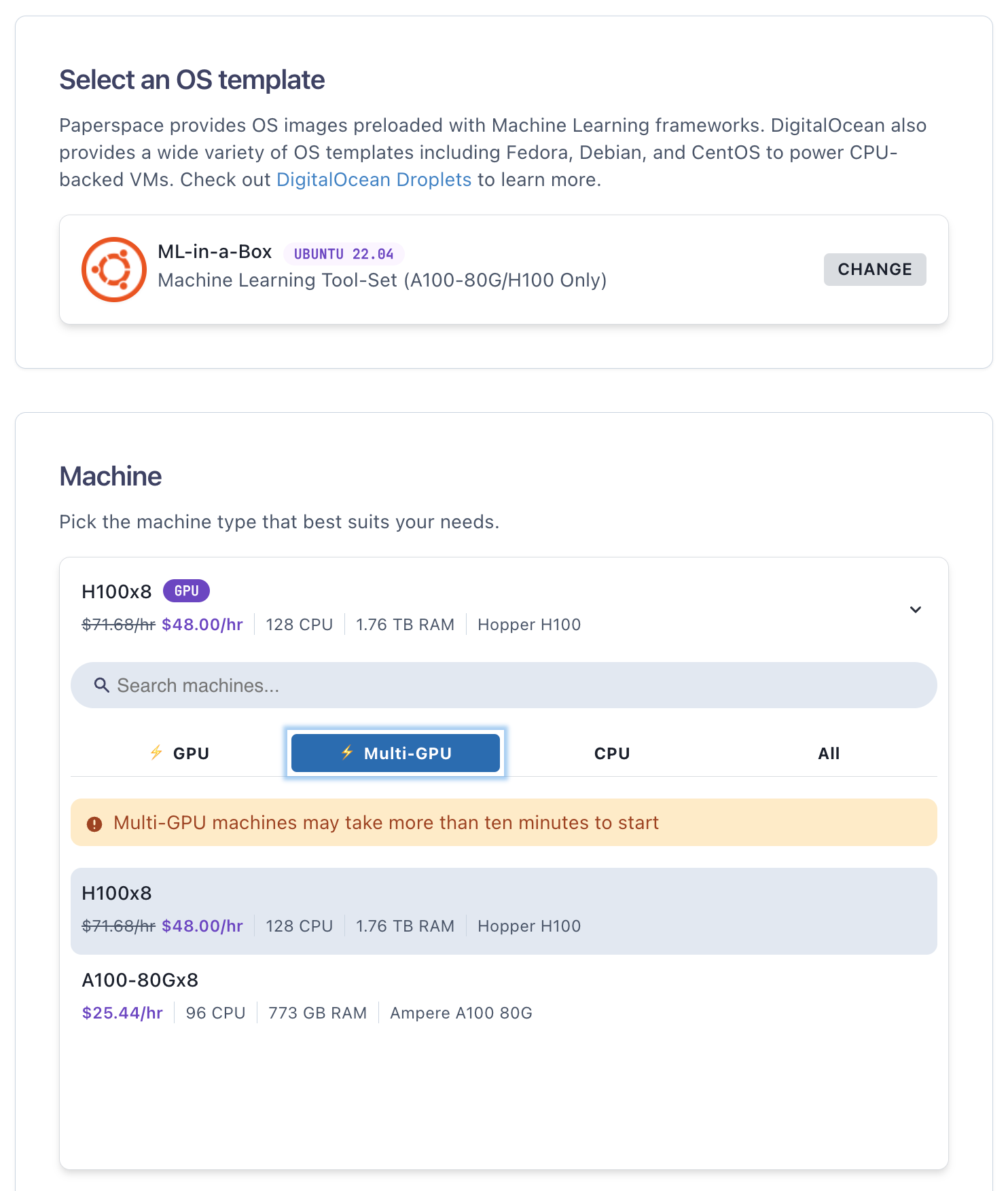
H100s might be accessed in the identical approach as our different GPUs, by way of the Paperspace GUI. Use the ML-in-a-Field template and select H100×8:
💡
Be aware – Presently, entry to H100s requires approval from Paperspace by DigitalOcean first. This can be a simple course of, and is in place to make sure finest availability for everybody.
MosaicML MPT Fashions

MosaicML maintains their LLM Foundry GitHub repository, the place the MPT collection of fashions is obtainable. It continues to offer these open supply LLMs in an up-to-date method in a setup that works in follow end-to-end.
We described these fashions a bit extra within the earlier publish, and listed here are specializing in two specifically:
- MPT-760m for pretraining: The MPT collection accommodates fashions in a spread of sizes, named by the variety of parameters they’ve (m = thousands and thousands, b = billions):
125m, 350m, 760m, 1b, 3b, 7b, 13b, 30b, 70b. We select the 760m possibility for pretraining to offer a run of a superb dimension, however with out having to attend days or even weeks for it to undergo. (The bigger fashions usually are not solely larger dimension, but in addition want coaching for extra batches. 7B’s unique pretraining by MosaicML took 9.5 days on 440 A100-40G GPUs, at a price of $200k.) - MPT-30B for finetuning: typically generic LLMs can reply to questions like they’re persevering with a chat relatively than answering the query. This isn’t helpful when the questioner is particularly on the lookout for the reply. The MPT-30B mannequin is tuned to raised reply questions than the bottom mannequin. We selected the 30 billion parameter mannequin as a result of (a) it represents the total dimension of mannequin than most companies will wish to tune to unravel their actual issues, and (b) an optimized YAML is out there on LLM Foundry for the 30B. The ensuing mannequin ought to be just like the MPT-30B-Instruct mannequin that’s out there from MosaicML on Hugging Face.
Importantly, whereas being open supply, these fashions are licensed for business use, which means that you should use them on DigitalOcean to assist with your small business.
The Finish-to-Finish Course of
So are we actually doing end-to-end? Properly, we’re not placing these fashions into money-making manufacturing, however we’re doing a lot of the steps.
A contemporary end-to-end AI/ML course of for LLMs might be regarded as a collection of steps that get iterated between. We spotlight those that we’re demonstrating right here, with some temporary feedback.
- Enterprise downside
- Origination of knowledge
- Knowledge assortment
- Knowledge storage
- Knowledge preparation
- Mannequin coaching
- Mannequin conversion to inference
- Inference/deployment
- Deployment to manufacturing
- Monitoring
- Interface to get enterprise worth
Crucial remark is that whereas we aren’t doing all 11 of those steps on this blogpost, they’ll all be executed on Paperspace by DigitalOcean. Steps 1 and a couple of are considerably exterior to the cloud, however with our platform the infrastructure is in place to permit every thing within the checklist to be executed.
Step one, the enterprise downside, is that we wish to pretrain an LLM from scratch on our information in order that we’ve full management, after which finetune one other one to raised reply questions for our clients. Step 2 shouldn’t be executed right here as a result of the info exist already on-line. For steps 3-5, we’re downloading the info, which is sort of giant, storing it in order that it’s accessible in a way performant sufficient to not bottleneck the H100 GPUs, and working preparation akin to tokenization. Step 6 is the mannequin pretraining or finetuning, which we’re working in full by way of the GitHub repository’s code and YAML settings. Equally, step 7 converts the mannequin from the checkpoint ensuing from coaching to a extra compact format appropriate for deployment. (A mannequin working inference does not want all the data from coaching such because the optimizer states, so it may be smaller.) Step 8 is then our passing of consumer prompts to the mannequin and seeing its responses.
Steps 9/11, which might be executed however we aren’t trying right here, entail first placing the mannequin utilized in step 8 on an endpoint, e.g., by way of Paperspace Deployments. Then monitoring software program akin to Arize might be built-in to see the mannequin’s state whereas on-line, and whether or not it’s behaving appropriately. Lastly, step 11 can be exemplified by a webapp pointing to the mannequin that permits nontechnical customers to work together with it. Many shoppers already use DigitalOcean for his or her webapps.
Setup
Now that we’ve previewed the end-to-end course of, let’s examine the right way to obtain it.
First, we element the right way to set the mannequin up for coaching on Paperspace by DigitalOcean. We then observe this by the specifics of pretraining and finetuning, and eventually inference + deployment.
These sections are fairly lengthy, however they realistically mirror the variety of steps that must be taken to run LLMs at scale, and that you just would possibly take when working your personal.
Let’s go!
Join the platform
Entry to the H100 GPUs for working these fashions as proven right here requires platform signup. As a part of the method, you may be guided to request approval to start out up H100 machines.
Begin H100 machine(s)
When beginning up within the GUI (Paperspace Core), it would inform you {that a} personal community is required. This will seem to be an inconvenience to must manually add it when all machines want it, however it’s fast and simple right here: simply click on Add Non-public Community, select a reputation, then choose it from the Choose community dropdown.
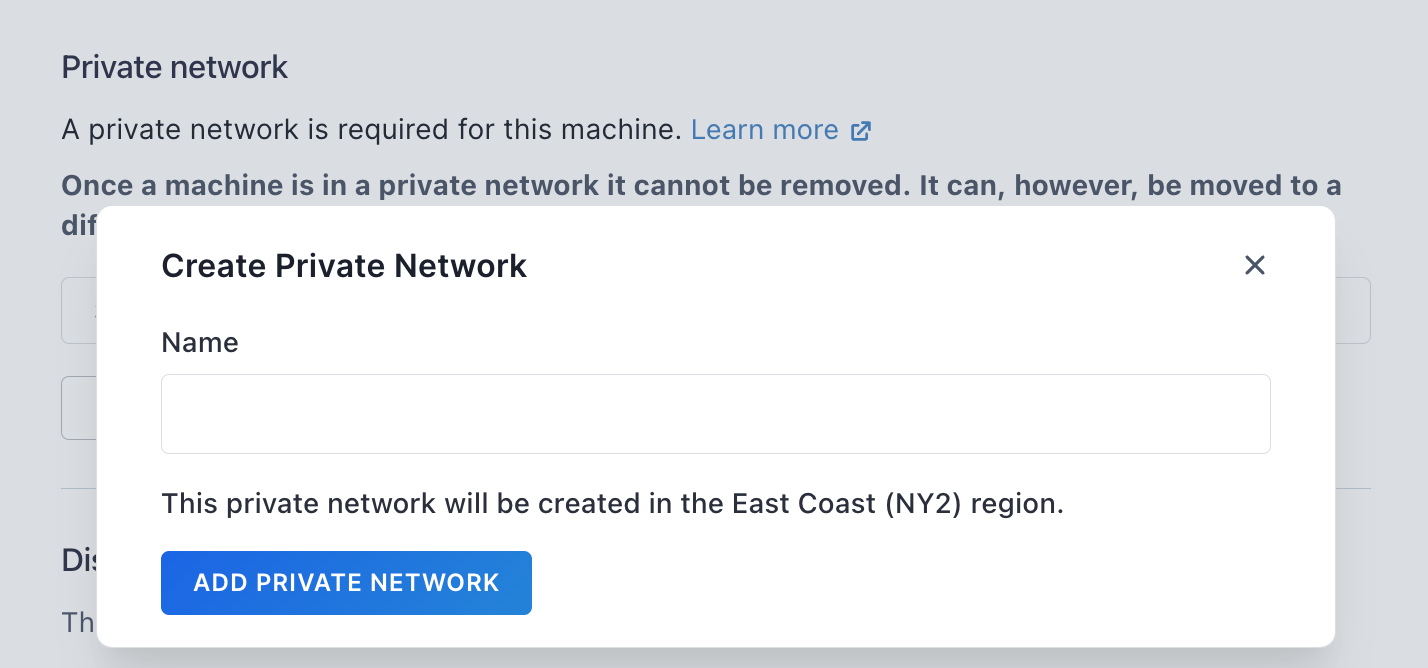
For multinode work, a personal community is required anyway for the machines to see one another. We’ll use it under for this goal, and for entry to a typical shared drive to retailer our information and fashions.
Machine entry additionally requires an SSH key, which is commonplace. The disk dimension ought to be elevated from the default 100 GB, and we suggest 1-2 TB.
Different choices akin to dynamic IP might be left on their default settings. NVLink is enabled by default.
Entry the machine out of your native machine’s terminal utilizing SSH to the machine’s dynamic IP, i.e., like
ssh paperspace@123.456.789.012You’ll be able to see you machine’s IP from its particulars web page within the GUI. On a Mac, iTerm2 works properly, however any terminal that has SSH ought to work. As soon as accessed, it is best to see the machine’s command line.
For those who plan to do multinode work, repeat the above steps to create the variety of machines (nodes) that you just want to use.
Shared drives
Paperspace’s shared drives present performant entry to giant information akin to information and fashions that the consumer doesn’t wish to retailer on their machine straight, or that must be seen throughout a number of machines.
Shared drives can maintain as much as 16 TB of knowledge relatively restrict of as much as 2 TB on the machine’s personal drive.
Setting one up requires some guide steps, however they’re simple.
(1) Within the Paperspace Core GUI, go to the Drives tab, click on Create, and a modal seems with the drive particulars. Select a reputation, dimension, area, and personal community. The title is unfair, for dimension we suggest 2 TB or extra, for area use the one beneath which you created your machine(s) above, and likewise for personal community.
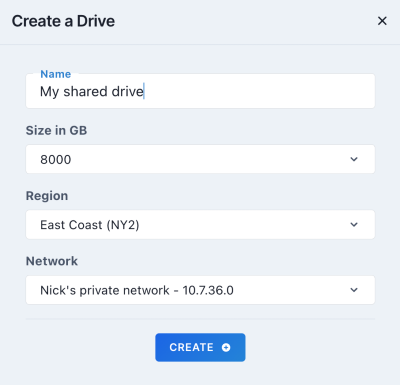
(2) Out of your machine’s terminal, edit the /and so on/fstab file so as to add the drive’s data, so, for instance
sudo vi /and so on/fstabthen the credentials appear to be
//10.1.2.3/stu1vwx2yz /mnt/my_shared_drive cifs
consumer=aBcDEfghIjKL,password=<copy from GUI>,rw,uid=1000,gid=1000,customers 0 0which may all be seen to your drive within the GUI Drives tab.
💡
Be aware – Within the GUI, the community tackle is given with backslashes , however in /and so on/fstab it is advisable write them as ahead slashes /.
(3) Mount the shared drive utilizing
sudo mkdir -p /mnt/my_shared_drive
sudo chown paperspace:paperspace /mnt/my_shared_drive
mount /mnt/my_shared_driveYou’ll be able to examine the drive is seen utilizing df -h, the place it ought to present up in one of many rows of output.
The method of modifying /and so on/fstab and mounting the shared drive must be repeated on all machines in case you are utilizing multinode.
Be aware that in precept, the shared drive is also in a distant location akin to an object retailer, however we did not discover that setup for this blogpost.
MosaicML’s Docker containers
Now that we’re arrange with our machine(s) and shared drive, we have to arrange the MosaicML LLM Foundry .
To make sure an atmosphere that’s secure and reproducible with respect to our mannequin runs, we observe their advice and make the most of their supplied Docker photos.
A selection of photos is offered, and we use the one with the most recent model 2 Flash Consideration:
docker pull mosaicml/llm-foundry:2.1.0_cu121_flash2-latestTo run the container, we have to bind-mount the shared drive to it in order that it may be seen from the container, and for multinode cross varied arguments in order that the total H100 GPU cloth is used:
docker run -it
--gpus all
--ipc host
--name <container title>
--network host
--mount kind=bind,supply=/mnt/my_shared_drive,
goal=/mnt/my_shared_drive
--shm-size=4g
--ulimit memlock=-1
--ulimit stack=67108864
--device /dev/infiniband/:/dev/infiniband/
--volume /dev/infiniband/:/dev/infiniband/
--volume /sys/class/infiniband/:/sys/class/infiniband/
--volume /and so on/nccl/:/and so on/nccl/
--volume /and so on/nccl.conf:/and so on/nccl.conf:ro
<container picture ID>On this command, -it is the same old container setting to get interactivity, --gpus is as a result of we’re utilizing Nvidia Docker (provided with our machine’s ML-in-a-Field template), --ipc and --network assist the community operate appropriately, --mount is the bind-mount to see the shared drive as /mnt/my_shared_drive throughout the container, --shm-size and --ulimit guarantee we’ve sufficient reminiscence to run the fashions, and --device & --volume arrange the GPU cloth.
You’ll be able to see your container’s picture ID from the host machine by working docker photos, and your container’s title is unfair. We used a reputation containing a date, like
export CONTAINER_NAME=
`echo mpt_pretraining_node_${NODE_RANK}_`date +%Y-%m-%d_percentHpercentM-%S``for versioning functions, NODE_RANK being 0, 1, 2, and so on., for our totally different nodes on the community.
In case you are restarting an current container as an alternative of making a brand new one, you should use docker begin -ai <container ID>, the place the container ID might be seen from docker ps -a. This could put you again within the container on the command line, the identical as above when a brand new container was created.
A last be aware for the container setup is that our ML-in-a-Field template accommodates a configuration file for the Nvidia Collective Communications Library (NCCL) that helps every thing run higher with H100s and our 3.2 Tb/s node interconnect. This file is in /and so on/nccl.conf and accommodates:
NCCL_TOPO_FILE=/and so on/nccl/topo.xml
NCCL_IB_DISABLE=0
NCCL_IB_CUDA_SUPPORT=1
NCCL_IB_HCA=mlx5
NCCL_CROSS_NIC=0
NCCL_SOCKET_IFNAME=eth0
NCCL_IB_GID_INDEX=1The file is already provided and doesn’t must be modified by the consumer.
As with the shared drives, the method right here is repeated on every node in case you are working multinode.
💡
tmux -CC earlier than beginning up the container. This helps forestall a dropped community connection from terminating any coaching runs later. On a Mac, tmux is supported out-of-the-box in iTerm2. See right here for extra particulars.Arrange GitHub repository on the container
As soon as we’re within the container, the code might be arrange by cloning the GitHub repository after which putting in it as a package deal. Following LLM Foundry’s readme, that is:
git clone https://github.com/mosaicml/llm-foundry.git
cd llm-foundry
pip set up -e ".[gpu]"On our machines, we additionally first put in an editor (apt replace; apt set up -y vim), up to date pip (pip set up --upgrade pip), and recorded the model of the repository that we had been utilizing (cd llm-foundry; git rev-parse primary).
There are additionally a few non-compulsory steps of putting in XFormers and FP8 (8-bit datatype) assist for H100s: pip set up xformers and pip set up flash-attn==1.0.7 --no-build-isolation together with pip set up git+https://github.com/NVIDIA/TransformerEngine.git@v0.10. We truly generated our outcomes with out these, however they’re out there as a possible optimization.
Bookkeeping
The repository works by offering Python scripts that in flip name the code to arrange the info, practice the fashions, and run inference. In precept it’s subsequently easy to run, however we do want just a few extra steps to run issues at scale in a minimally organized trend:
- Create some directories: information, mannequin checkpoints, fashions for inference, YAML information, logs, subdirectories for every node, the pretraining or finetuning duties, varied runs, and any others akin to a information with immediate textual content
- Allow Weights & Biases logging: not strictly required, or one may combine different libraries like TensorBoard, however this auto-plots a pattern of helpful metrics that give data on our runs. These embrace GPU utilization and mannequin efficiency whereas coaching. This requires a Weights & Biases account.
- Atmosphere variables: Additionally not strictly required, however helpful.
NCCL_DEBUG=INFOwas wanted much less as the brand new infrastructure turn out to be extra dependable pre-launch, however we nonetheless set it. If utilizing Weights and Biases logging,WANDB_API_KEYis required to be set to the worth of your API key from there to allow logging with out a guide interactive step. We set some others as properly to simplify instructions referring to assorted directories on multinode, and they are often seen under.
For a multinode run to do the pretraining and finetuning that we present right here, a minimal set of directories is
/llm-own/logs/pretrain/single_node/
/llm-own/logs/finetune/multinode/
/llm-own/logs/convert_dataset/c4/
$SD/information/c4/
$SD/yamls/pretrain/
$SD/yamls/finetune/
$SD/pretrain/single_node/node0/mpt-760m/checkpoints/
$SD/pretrain/single_node/node0/mpt-760m/hf_for_inference/
$SD/finetune/multinode/mpt-30b-instruct/checkpoints/
$SD/finetune/multinode/mpt-30b-instruct/hf_for_inference/the place SD is the situation of our shared drive, NODE_RANK is 0, 1, 2, and so on., for our totally different H100×8 nodes. /llm-own is unfair, being only a place on the container to put the directories.
A few of these would possibly look fairly lengthy, however in follow we ran extra fashions and variations than proven on this blogpost. You should utilize mkdir -p to create subdirectories concurrently the dad or mum ones.
We’ll see how the directories are used under.
Able to go!
Now the setup is full, we’re prepared to maneuver on to information preparation → mannequin coaching → inference + deployment.
Pretraining MPT-760m
Now that we’re set as much as go by following the steps within the earlier part, our first run is mannequin pretraining. That is for MPT-760m.
We ran this on each single node and multinode. Right here we present the only node, and we are going to present multinode for finetuning MPT-30B under.
Get the info

For LLM pretraining, the info are giant: the C4 dataset on Hugging Face relies on the Frequent Crawl dataset for LLM pretraining, and accommodates over two million rows.
A typical row of the info seems like
{
'url': 'https://klyq.com/beginners-bbq-class-taking-place-in-missoula/',
'textual content': 'Rookies BBQ Class Taking Place in Missoula!nDo you wish to get higher at making scrumptious BBQ? You'll have the chance, put this in your calendar now. Thursday, September twenty second be part of World Class BBQ Champion, Tony Balay from Lonestar Smoke Rangers. He will probably be educating a newbie degree class for everybody who desires to get higher with their culinary expertise.nHe will train you every thing it is advisable know to compete in a KCBS BBQ competitors, together with strategies, recipes, timelines, meat choice and trimming, plus smoker and fireplace data.nThe value to be within the class is $35 per particular person, and for spectators it's free. Included in the fee will probably be both a t-shirt or apron and you may be tasting samples of every meat that's ready.',
'timestamp': '2019-04-25T12:57:54Z'
}LLM Foundry gives a script to obtain and put together the info. We name it utilizing
time python
/llm-foundry/scripts/data_prep/convert_dataset_hf.py
--dataset c4
--data_subset en
--out_root $SD/information/c4
--splits practice val
--concat_tokens 2048
--tokenizer EleutherAI/gpt-neox-20b
--eos_text '<|endoftext|>'
2>&1 | tee /llm-own/logs/convert_dataset/c4/convert_dataset_hf.logthe place the command is wrapped by time ... 2>&1 tee <logfile> so we are able to seize the terminal stdout and stderr output to a logfile, and the wallclock time taken to run. We use this easy time ... tee wrapper all through our work right here, however it’s non-compulsory.
The preprocessing does not use multinode or GPU, however with a superb community velocity for obtain it runs in about 2-3 hours as a one-off step, so optimizing this step onto GPU with one thing like DALI or GPUDirect shouldn’t be necessary.
The script converts the downloaded information into the MosaicML StreamingDataset format, which is designed to run higher when used with distributed fashions at scale. The ensuing set of information is 20850 shards in /mnt/my_shared_drive/information/c4/practice/shard.{00000…20849}.mds, plus a JSON index, and 21 shards as a validation set in val/. The full dimension on disk is about 1.3 TB.
YAML information
With the info out there, we have to set the entire parameters describing the mannequin and its coaching to the proper values. Luckily (once more), the repository has a spread of those already set for each pretraining and finetuning. They’re provided as YAML information.
For the MPT-760m mannequin, we use the values in this YAML, and depart them on the defaults apart from:
data_local: /mnt/my_shared_drive/information/c4
loggers:
wandb: {}
save_folder: /llm-own/nick_mpt_8t/pretrain/single_node/node0/
mpt-760m/checkpoints/{run_name}We level to the info on the shared drive, uncomment the Weights & Biases logging, and save the mannequin to a listing containing the run title. The title is about by the atmosphere variable RUN_NAME, which the YAML picks up by default. We give this a date in an identical method to the container title above for versioning functions.
Working on a single node permits us to depart the default saving of checkpoints to save_folder each 1000 batches as-is, since they don’t seem to be significantly giant for the 760m mannequin. We save them to the machine’s drive to keep away from a problem with symbolic linking on the shared drive — see the finetuning MPT-30B part under. They might be moved to the shared drive after the run if wanted.
We talked a bit extra about what most of the different YAML parameters for these fashions imply within the earlier MPT blogpost, in its High quality-tuning run part for MPT-7B.
Run pretraining
With the info and mannequin parameters arrange, we’re prepared for the total pretraining run:
time composer
/llm-foundry/scripts/practice/practice.py
/llm-own/yamls/pretrain/mpt-760m_single_node.yaml
2>&1 | tee /llm-own/logs/pretrain/single_node/
{$RUN_NAME}_run_pretraining.logThis command makes use of MosaicML’s composer wrapper to PyTorch, which in flip makes use of all 8 H100 GPUs on this node. Arguments might be handed to the command, however we’ve encapsulated all of them within the mpt-760m_single_node.yaml YAML file.
As above, the time ... tee wrapper is ours, and is non-compulsory, so the command has in precept decreased to the quite simple composer practice.py <YAML file>.
Outcomes from working pretraining
Utilizing one H100×8 node, full MPT-760m pretraining completes in about 10.5 hours. (And on 2 nodes multinode, it completes in beneath 6 hours.)
We will see some facets of the coaching by viewing Weights & Biases’s auto-generated plots.
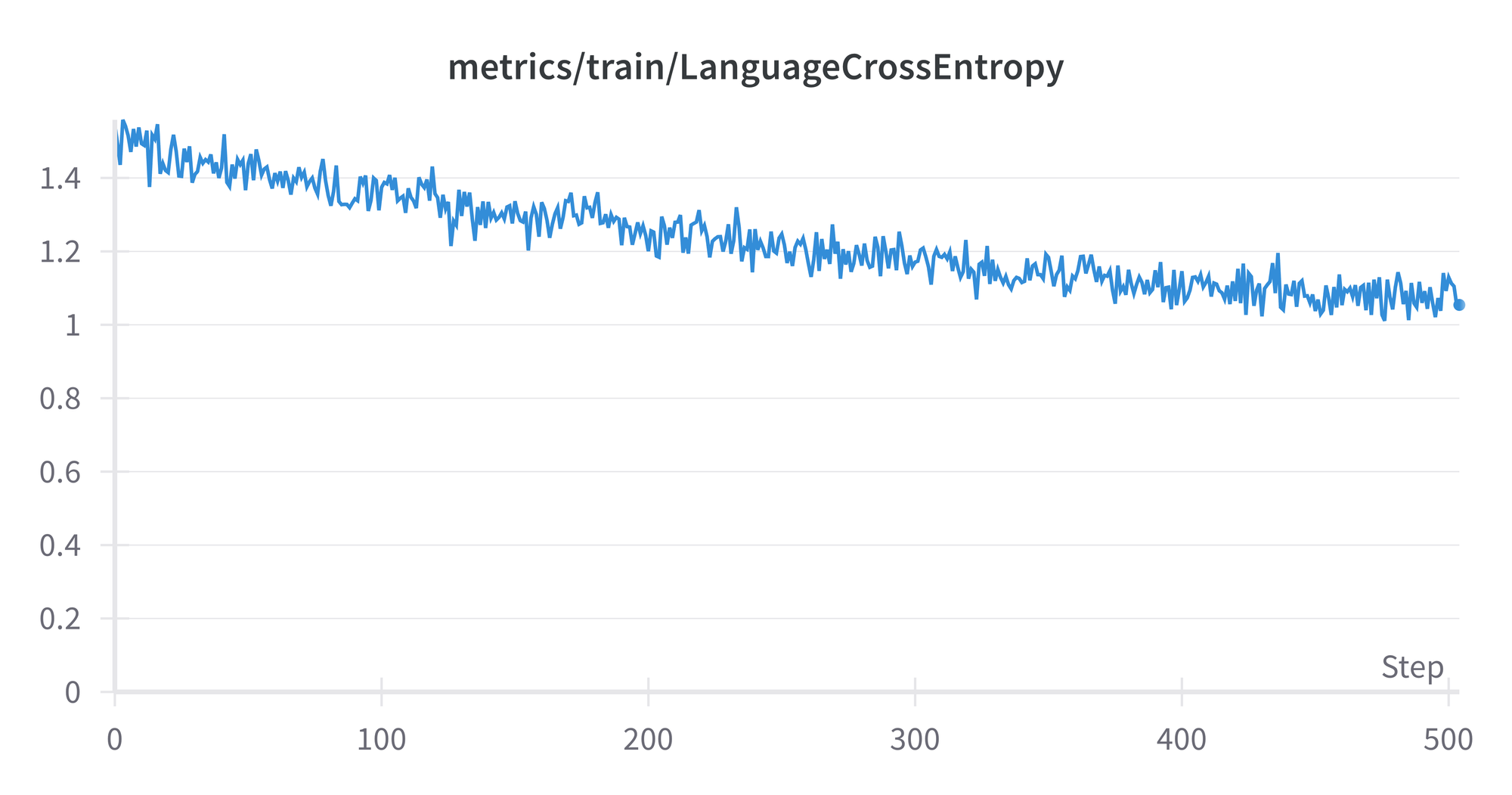
The enhancing mannequin efficiency whereas coaching might be measured in varied methods, right here by default they’re loss, cross-entropy, and perplexity. For cross-entropy, we see its worth versus the variety of batches reached in coaching, from 0-29000:
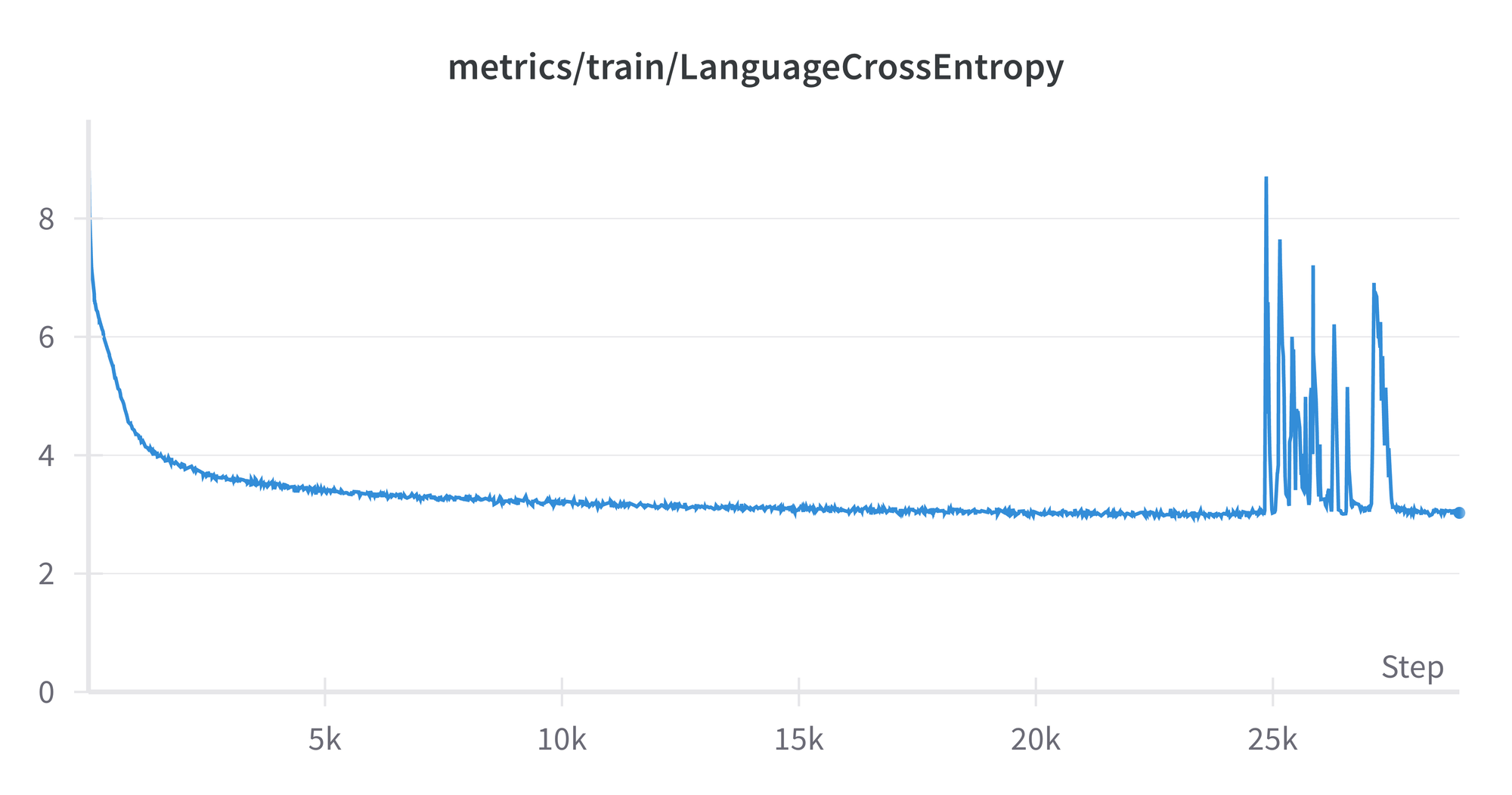
The spikes from round 25k-28k are curious, however don’t seem to have an effect on the ultimate outcome, which displays the overall flattening out of the curve round a price of three. The plots for loss and perplexity are related in form, as are those from the mannequin run on the analysis set.
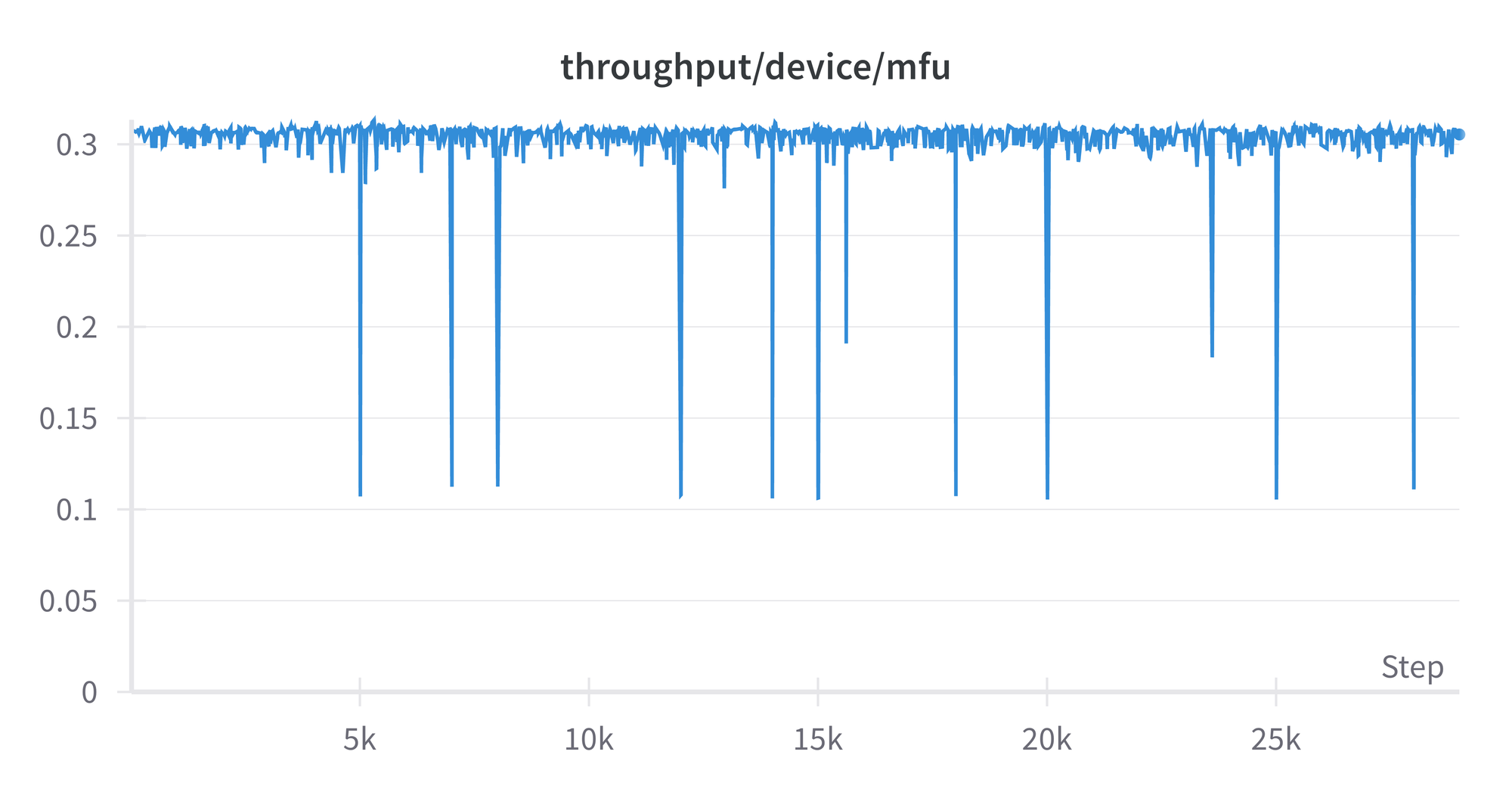
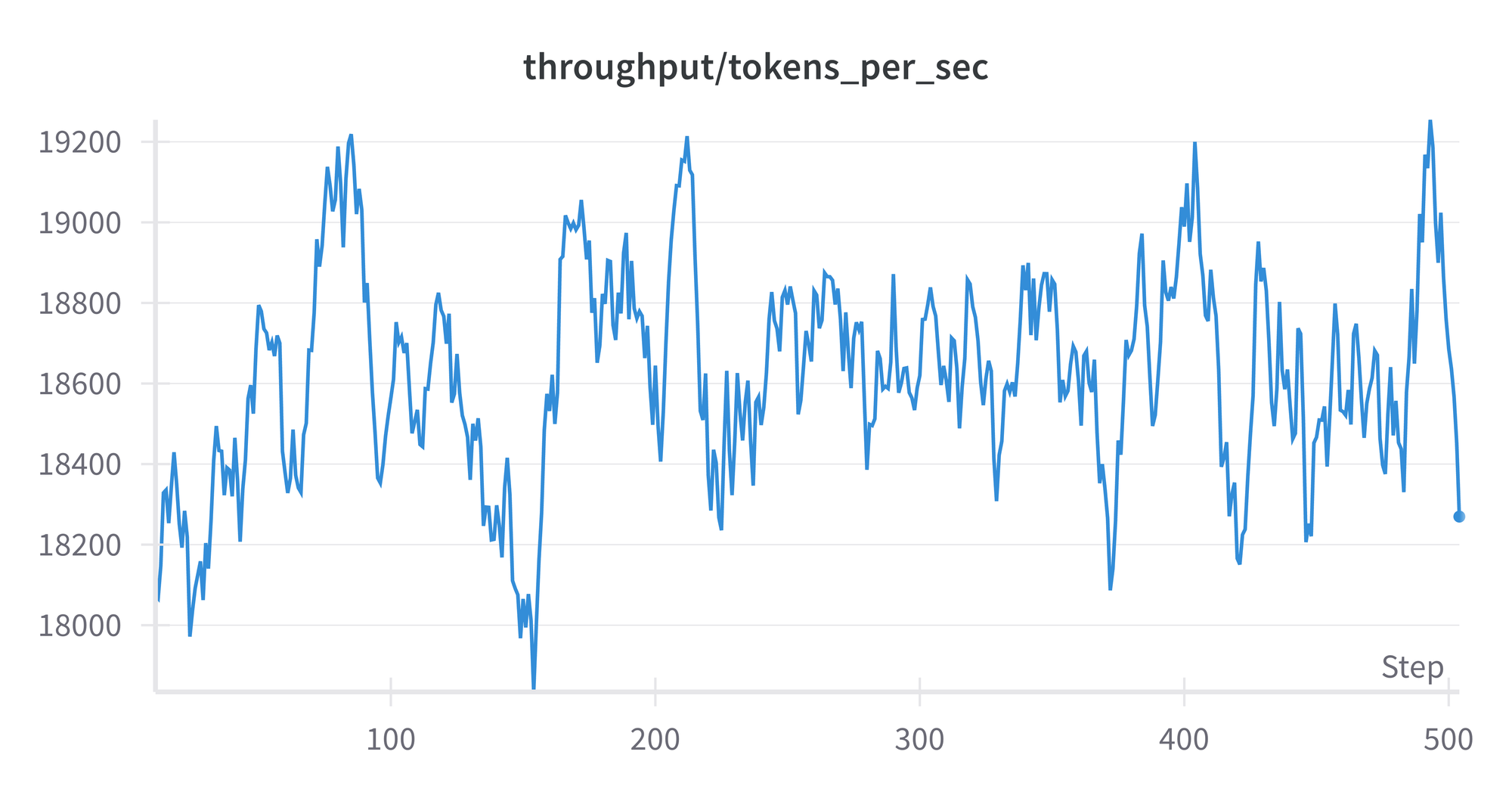
The mannequin FLOPS utilization (MFU) reveals how effectively the GPU is getting used. We see that it’s secure all through, other than some occasional dips, and is simply over 0.3. The theoretical good worth is 1, and in follow extremely optimized runs can get round 0.5. So there could also be some room for enchancment in our mannequin’s detailed settings, however it isn’t orders of magnitude off. A plot of throughput in tokens per second seems related, round 4.5e+5.
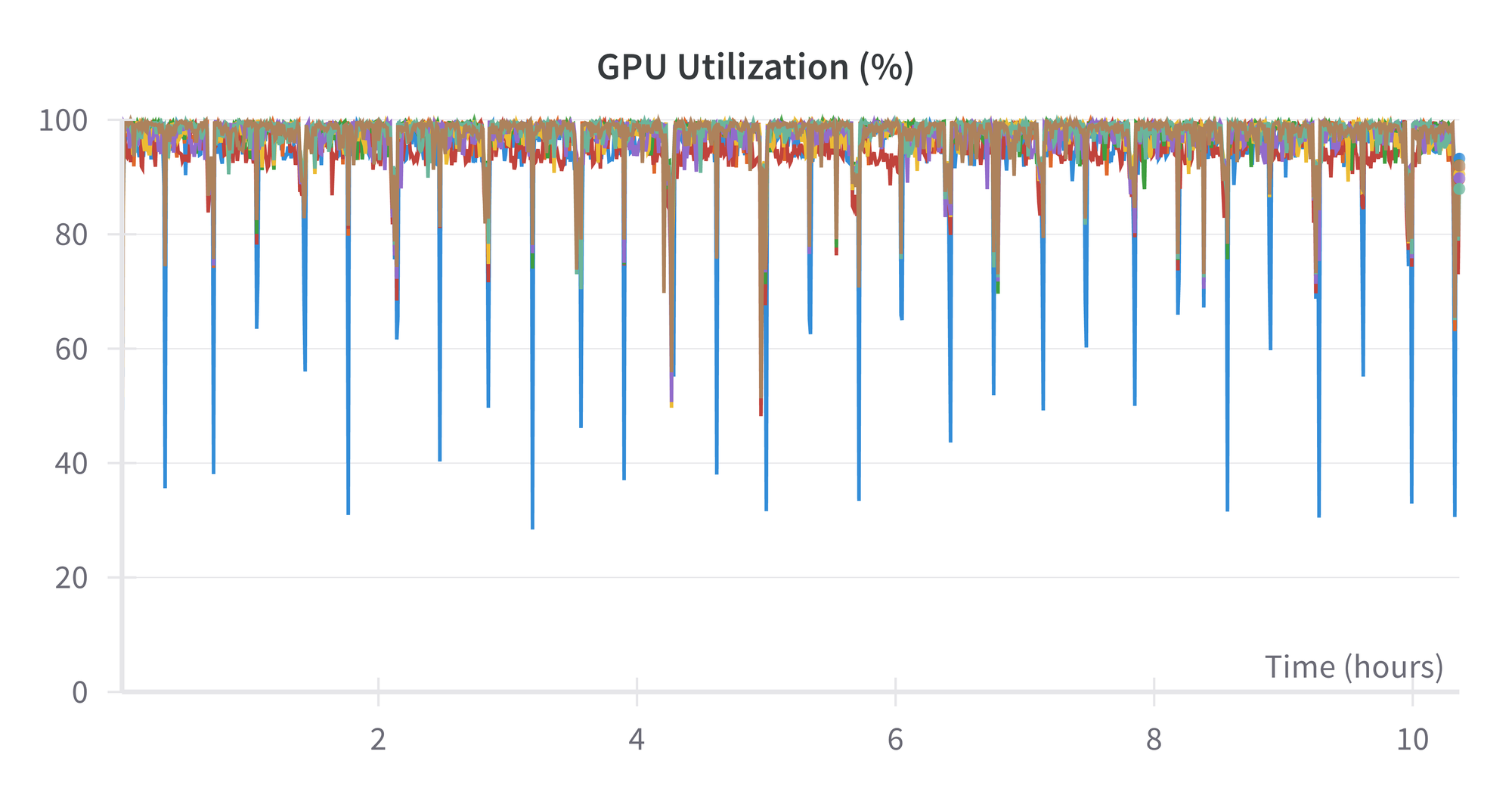
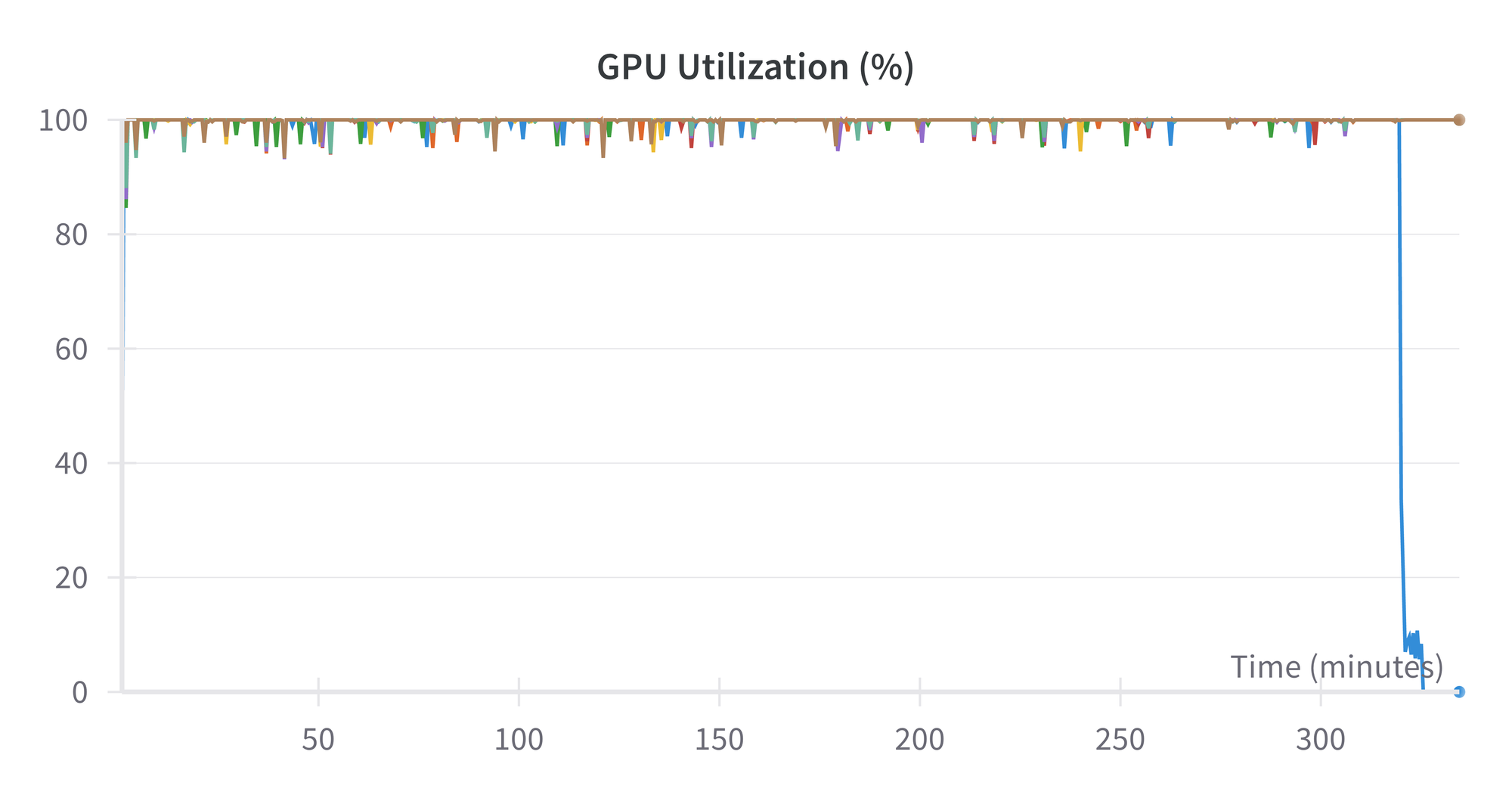
Utilization of the GPU is near 100% all through. The biggest (blue) spikes downward are the primary GPU of the 8.
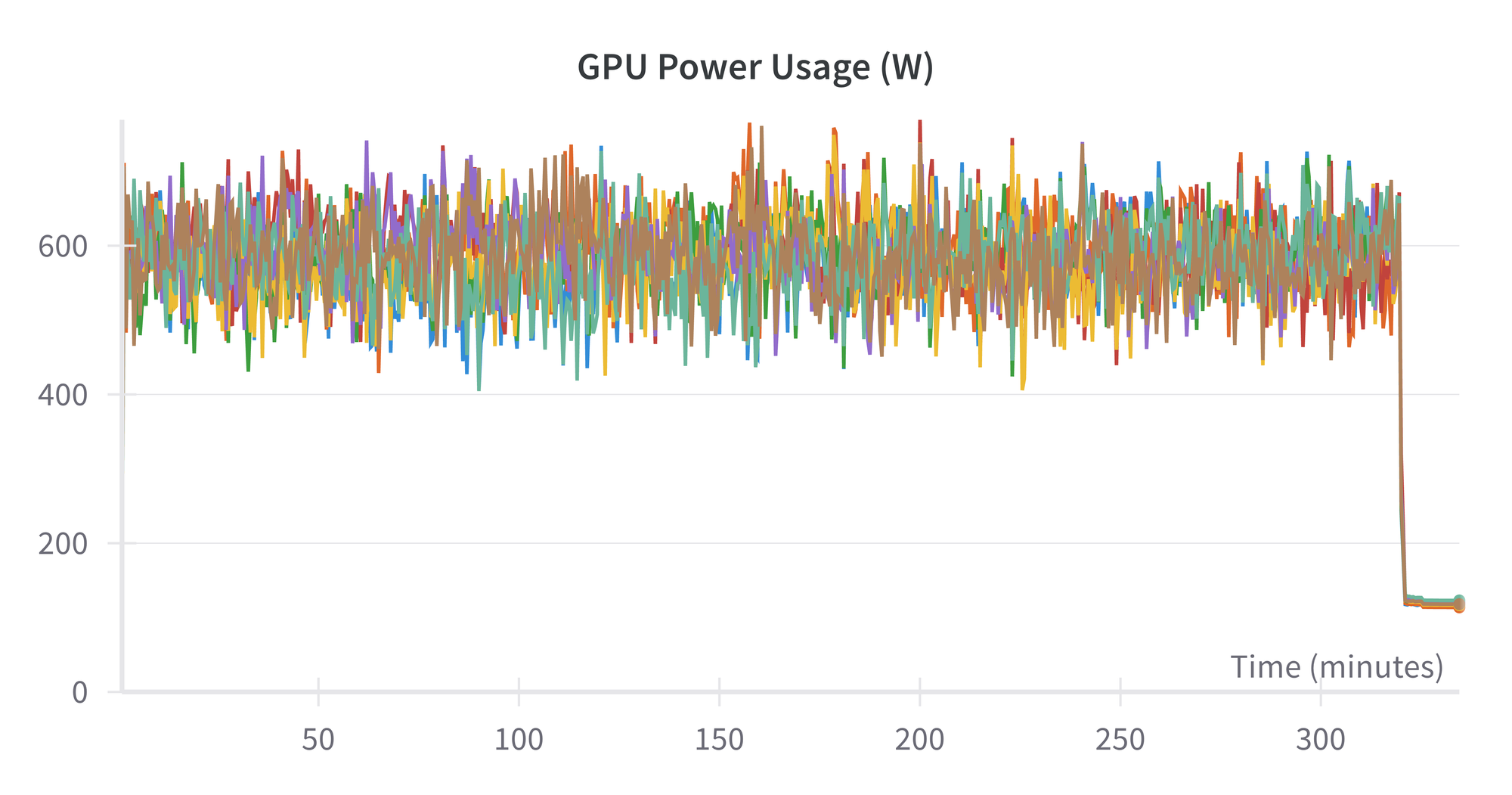
Lastly, the facility utilization of the H100s is about 625 watts:
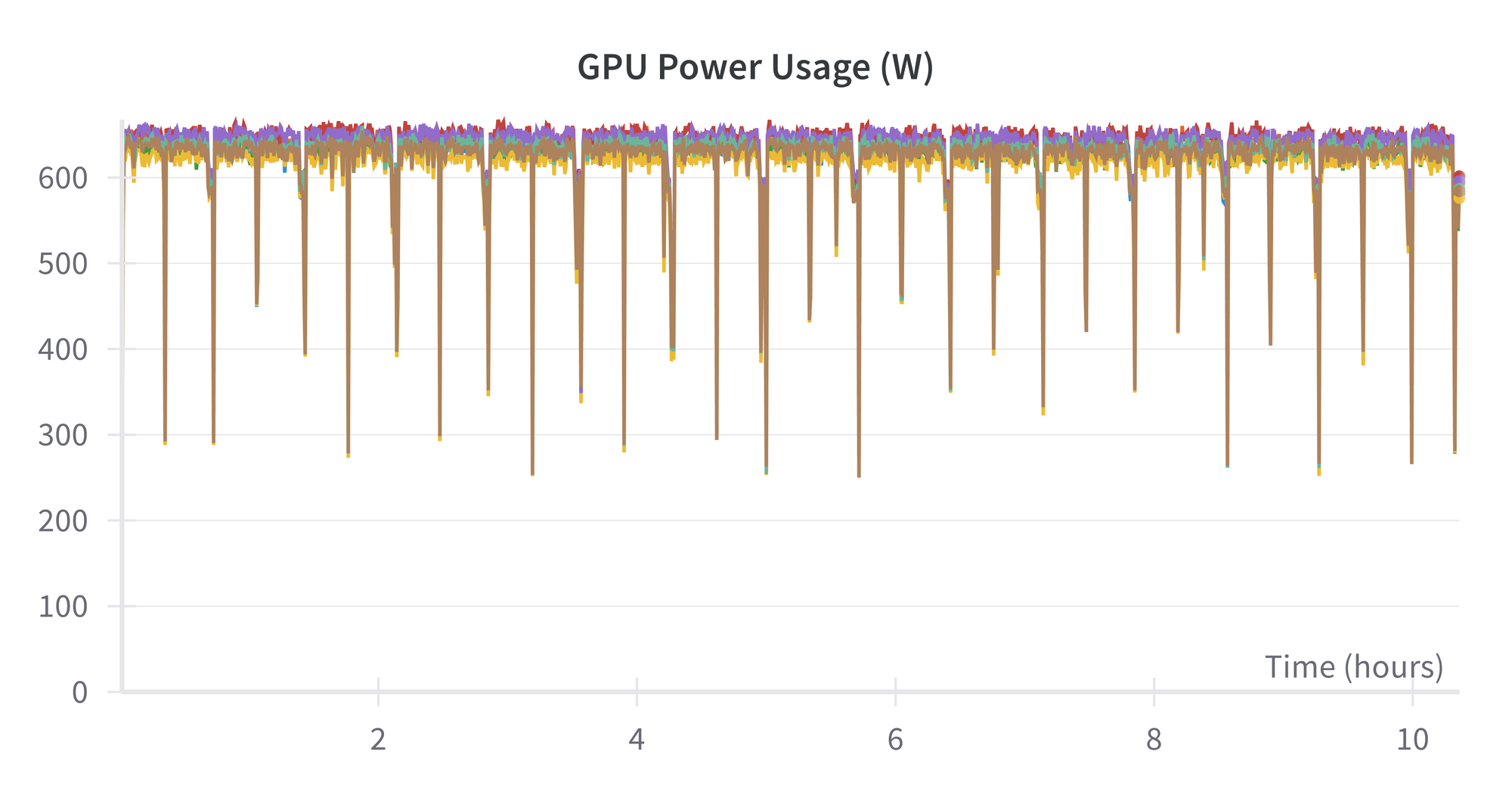
Which means that the full energy used for this run is about 625 watts × 10.5 hours × 8 GPUs × 1 node ~ 50 kWh
When the coaching is full, the checkpoint dimension of the absolutely educated mannequin is 8.6 GB, and it’s prepared for use for inference and deployment (see under).
Finetuning MPT-30B
Above, we pretrained MPT-760m on a single H100×8 node. Right here, we finetune the MPT-30B mannequin, and present the outcomes from utilizing 2 nodes, i.e., multinode. (It additionally labored on 4 nodes.)
Get the mannequin
Whereas information for finetuning are usually a lot smaller than for pretraining, the mannequin for use might be a lot bigger. It is because the mannequin is already pretrained, which means comparatively much less compute is required.
We’re subsequently in a position to improve from MPT-760m in full pretraining above to finetuning the MPT-30B mannequin with its 30 billion parameters, whereas sustaining a runtime of some hours.
The preliminary dimension of MPT-30B is 56 GB, and that is routinely downloaded by the finetuning script under. After finetuing, the dimensions on disk of the ultimate checkpoint is 335 GB.
YAML information
The LLM Foundry is about up in order that finetuning works fairly equally to pretraining from the consumer perspective. As above, we largely use the default YAML values, this time from right here, however now make these adjustments:
run_name: <run title>
global_train_batch_size: 96
loggers:
wandb: {}
save_folder: /mnt/nick_mpt_8t/finetune/multinode/
mpt-30b-instruct/checkpoints/{run_name}
save_interval: 999epThe logging to Weights and Biases is just like pretraining. We give the run title within the YAML this time. The opposite required change is for the worldwide practice batch dimension to be divisible by the full variety of GPUs, right here 16 for two nodes. The worth used is pretty near the unique YAML’s default of 72.
As a result of every checkpoint now has a dimension of 335 GB, we now save them on to the shared drive relatively than the machine’s drive. This, nonetheless, brings up a problem with symbolic linking, mentioned extra within the be aware under, which implies that the save interval needs to be set to a big worth.
Lastly, we commented out the ICL mannequin analysis duties given within the unique YAML, as a result of they wanted additional setup. The values of loss, entropy, and perplexity on the analysis set are nonetheless calculated throughout coaching.
Run finetuning
Finetuning is now able to go, and is invoked by the multinode model of the composer command:
time composer
--world_size 16
--node_rank $NODE_RANK
--master_addr 10.1.2.3
--master_port 7501
/llm-foundry/scripts/practice/practice.py
$SD/yamls/finetune/mpt-30b-instruct_multinode.yaml
2>&1 | tee /llm-own/logs/finetune/multinode/
${RUN_NAME}_run_finetuning.logThat is handy, as it may be given on every node, enabling multinode coaching with out a workload supervisor akin to Slurm, as long as the nodes can see one another and the shared drive.
The composer command is in flip calling PyTorch Distributed. Within the arguments, the --world_size is the full variety of GPUs, --node_rank is 0, 1, 2, and so on., for every node, 0 being the grasp, --master_addr is the personal IP of the grasp node (seen on the GUI machine particulars web page), --master_port must be seen on every node, and we use varied atmosphere variables in order that the identical command might be given on every node. The YAML captures all the opposite settings, and is positioned on the shared drive so we solely must edit it as soon as.
The command on node 0 waits for the command to be issued on all nodes, then runs the coaching with the mannequin distributed throughout the nodes utilizing a completely sharded information parallel (FSDP) setup.
💡
Relating to the altering of the save interval of the checkpoints to 999ep (999 epochs), this can be a workaround: on our present infrastructure, the shared drives don’t assist symbolic hyperlinks. However the MosaicML repository makes use of them in its code to level to the most recent mannequin checkpoint. That is helpful normally when there are doubtlessly many checkpoints, however right here it causes the run to interrupt on the primary checkpoint save with an error saying symlink shouldn’t be supported. We may doubtlessly fork the repository and alter the code, or suggest a PR that makes using symlinks non-compulsory, however it may entail adjustments at many factors within the codebase. As an alternative, we set the save interval to a lot of epochs in order that the mannequin checkpoint solely will get saved on the finish of the run. Then when symlink fails, nothing is misplaced because of the failure besides the zero exit code from the method. It does depart our runs weak to being misplaced in the event that they fail earlier than the top, and removes the power to see intermediate checkpoints, however our runs usually are not in a production-critical setting. Encountering limitations like this from the mix of cloud infrastructure + AI/ML software program, and resolving or working round them, is typical when engaged on actual end-to-end issues at scale.
Outcomes from working finetuning
The finetuning run does not output the mannequin FLOPS utilization, however we are able to see varied different metrics just like pretraining:
On the finish of the run, we’ve our last 335 GB checkpoint on the shared drive.
With this in place, we’re able to proceed to inference and deployment for our pretrained and finetuned fashions.
Inference and Deployment
Fashions which have been pretrained or finetuned include additional data, such because the optimizer states, that’s not wanted for working inference on new unseen information.
The LLM Foundry repository subsequently accommodates a script to transform mannequin checkpoints from coaching into the smaller and extra optimized Hugging Face format appropriate for deployment.
Our instructions for the pretrained MPT-760m and finetuned MPT-30B are:
time python
/llm-foundry/scripts/inference/convert_composer_to_hf.py
--composer_path $SD/pretrain/single_node/node$NODE_RANK/
mpt-760m/checkpoints/$RUN_NAME/$CHECKPOINT_NAME
--hf_output_path $SD/pretrain/single_node/node$NODE_RANK/
mpt-760m/hf_for_inference/$RUN_NAME
--output_precision bf16
2>&1 | tee /llm-own/logs/pretrain/single_node/
${RUN_NAME}_convert_to_hf.log
time python
/llm-foundry/scripts/inference/convert_composer_to_hf.py
--composer_path $SD/finetune/multinode/
mpt-30b-instruct/checkpoints/$RUN_NAME/$CHECKPOINT_NAME
--hf_output_path $SD/finetune/multinode/
mpt-30b-instruct/hf_for_inference/$RUN_NAME
--output_precision bf16
2>&1 | tee /llm-own/logs/finetune/multinode/
${RUN_NAME}_convert_to_hf.logThese cut back the mannequin sizes on disk from the 8.6 GB and 335 GB of the checkpoints to 1.5 GB and 56 GB. For the case of finetuning, we see that the transformed MPT-30B is identical dimension as the unique mannequin downloaded at first of the method. It is because finetuning leaves the mannequin with the identical structure however up to date weights.
Whereas the disk area taken has been decreased, it’s nonetheless in reality double the above numbers, at 3 GB and 112 GB, as a result of the transformed fashions are output in each .bin and .safetensors format.
(We will additionally be aware in passing that the ratio of the sizes of the 2 fashions is about the identical because the ratio of their variety of parameters: 30 billion / 760 million ~ 40.)
After conversion, we are able to “deploy” the fashions to run inference, by passing in consumer enter and seeing their responses utilizing the repository’s generator script:
time python
/llm-foundry/scripts/inference/hf_generate.py
--name_or_path $SD/pretrain/single_node/node$NODE_RANK/
mpt-760m/hf_for_inference/$RUN_NAME
--max_new_tokens 256
--prompts
"The reply to life, the universe, and happiness is"
"This is a fast recipe for baking chocolate chip cookies: Begin by"
2>&1 | tee /llm-own/logs/pretrain/single_node/
${RUN_NAME}_hf_generate.log
time python
/llm-foundry/scripts/inference/hf_generate.py
--name_or_path $SD/finetune/multinode/mpt-30b-instruct/
hf_for_inference/$RUN_NAME
--max_new_tokens 256
--prompts
"The reply to life, the universe, and happiness is"
"This is a fast recipe for baking chocolate chip cookies: Begin by"
2>&1 | tee /llm-own/logs/finetune/multinode/
${RUN_NAME}_hf_generate.logThe responses appear OK.
These are those from MPT-760m, truncated to the character restrict:
#########################################################################
The reply to life, the universe, and happiness is: the one path which issues.
The ebook of the yr has a particular place in everybody's coronary heart.
It may be stated solely as a metaphor.
As we search for the which means of life and happiness, some issues that come from the center come from the thoughts too. Like on this case, that one thing which is born with the human physique begins to develop, and begins to really feel the way in which you do, your coronary heart develop and develop, with the assistance of the Holy Spirit. The world of the spirit and the universe of matter, and the everlasting actuality which exists in all of the universe and the human physique, start to develop and to develop, and on the identical time develop and to develop, to develop and to develop.
This is excellent information as a result of we are able to come to the center and may discover our place within the cosmos, and we turn out to be a soul.
We will come to know the true, and in reality, we are able to attain the reality about our existence. We will come to search out peace about our life, and we are able to discover our place within the universe, and we develop.
And we are able to discover our place within the different aspect, and all have the identical energy.
How far have the folks of Earth skilled transformation, however didn't know
#########################################################################
This is a fast recipe for baking chocolate chip cookies: Begin by pouring the nuts into the butter or buttermilk and water into the pan after which sprinkle with the sugars.
Put the oven rack within the decrease half of the oven and unfold out 2 sheets of aluminum foil about 1 cm above the pan, after which put every rectangle within the preheated oven for 10 minutes. As soon as executed, take away the foil.
Whereas the nuts are cooking, put 1 tsp of maple syrup in a small pan with the sliced zucchini and stir properly. Prepare dinner along with the juices, stirring sometimes. The juices are a wealthy syrup which you will add simply previous to baking.
As soon as the nuts are executed, add 2 tsp of melted butter, and mix simply earlier than including the flour combination. It's possible you'll want somewhat greater than half milk in the event you like yours candy.
Switch the batter to the baking dish and bake for 40 minutes, stirring solely as soon as each 10 minutes. It's possible you'll bake the cookies for about an hour after baking.
In case you are utilizing a pan with a steel rack, place the baking sheet on a excessive rack and pour the nuts/butter on prime of the pan. The nuts will rise like a sweet bar after taking a couple of minutes to cook dinner on a tray.
In one other bowl combine collectively the flour and baking powder
#########################################################################Methods to quantify precisely how good an LLM’s response is to a consumer immediate remains to be a analysis downside. So the truth that the responses “appear OK”, whereas showing to be a relatively cursory examine, is in reality a superb empirical verification that our end-to-end course of has labored appropriately.
We are actually executed working our fashions!
Refinements?
Our primary intention right here has been to show multinode LLMs working end-to-end in a approach that might be passable for our customers to see when utilizing Paperspace by DigitalOcean themselves. Numerous points, resolutions, inside suggestions, and iterative product enhancements additionally resulted from this, however usually are not proven right here.
There stay many refinements that might be made to future AI work at scale, each particular to this case, and extra usually:
- Use XFormers and FP8: These non-compulsory installs talked about within the setup part above could present some additional speedup.
- Element YAML optimization: The optimum batch dimension could also be barely totally different for H100s in comparison with the GitHub repository defaults.
- Fewer guide steps: Numerous steps right here might be automated, akin to passing working the identical container setup adopted by instructions on every node.
- Symlinks: Fixing the shared drive symlink challenge would make working with checkpoints extra handy.
- Extra prompts and responses: We solely briefly used the end-result fashions right here, checking that just a few responses made sense. Checking extra can be prudent for manufacturing work, for instance, empirical comparability to the outputs from the baseline fashions, and suitability + security of the fashions’ responses for customers.
Conclusions and subsequent steps
We now have proven that pretraining and finetuning of sensible giant language fashions (LLMs) might be run on Paperspace by DigitalOcean (PS by DO), utilizing single or a number of H100×8 GPU nodes.
The top-to-end examples proven are sensible and never idealized on the product as-is, and so can be utilized as a foundation to your personal work with AI and machine studying.
The mix of accessibility, simplicity of use, selection of GPUs, reliability & scale, and complete buyer assist make PS by DO an excellent selection for companies and different clients who wish to pursue AI, whether or not by pretraining, finetuning, or deploying current fashions.
In addition to the LLMs proven right here, fashions in different frequent AI fields, akin to laptop imaginative and prescient and recommender techniques, are equally possible end-to-end.
Some subsequent steps to take are:
- Use PS by DO H100s: Join PS by DO, and you should have entry to the kinds of {hardware}, machines, and software program used on this blogpost.
- Try the documentation: Deep Studying with ML in a Field and NVIDIA H100 Tensor Core GPU are helpful.
- Deploy fashions and webapps: Paperspace Deployments permits the educated fashions seen right here working inference to be deployed to an endpoint, that may in flip be accessed by a webapp or different interface. DigitalOcean has a variety of consumers already utilizing webapps, so it’s a pure match to make use of them for AI too.
- Finetune fashions: We now have seen that the computing energy, reliability & scale, software program stack, and tractability exist on PS by DO to allow customers who have to finetune their very own fashions to take action.
- Remedy your small business (or different) downside with AI: the infrastructure offered is generic, so whether or not it is advisable use LLMs, laptop imaginative and prescient, recommender techniques, or one other a part of AI/ML, PS by DO is prepared.
An fascinating last thought is that, even after finetuning, the unique mannequin web page for MPT-30B-Instruct states:
MPT-30B-Instruct can produce factually incorrect output, and shouldn’t be relied on to supply factually correct data. MPT-30B-Instruct was educated on varied public datasets. Whereas nice efforts have been taken to wash the pretraining information, it’s attainable that this mannequin may generate lewd, biased or in any other case offensive outputs.
So, returning to the unique enterprise downside, it nonetheless appears that it might be extra suited to leisure dialog than purposes the place accuracy or content material security are vital. Enhancing the reliability of LLMs is an lively space of analysis, however, by way of mechanisms akin to retrieval augmented era (RAG), there’s big scope for doing so. We want extra work to be executed on enhancing the fashions!
By enabling such work on Paperspace by DigitalOcean, we hope that our GPU-accelerated compute on H100s will probably be part of that enchancment.
Good luck, and thanks for studying!