
{kind=link}
Deliver this mission to life
Deci AI’s YOLO-NAS has marked the development within the subject of object detection with its cutting-edge foundational mannequin. This mannequin stands out on account of subtle Neural Structure Search know-how, YOLO-NAS overcomes the gaps present in earlier YOLO fashions. The mannequin efficiently brings notable enhancements in areas corresponding to quantization assist and discovering the precise stability between accuracy and latency. This marks a big development within the subject of object detection.
YOLO-NAS contains quantization blocks which entails changing the weights, biases, and activations of a neural community from floating-point values to integer values (INT8), leading to enhanced mannequin effectivity. The transition to its INT8 quantized model leads to a minimal precision discount. This has marked as a serious enchancment when in comparison with different YOLO fashions.
These small enhancements resulted in an distinctive structure, delivering distinctive object detection capabilities and excellent efficiency.

Concerning the Article
This text offers an outline of YOLO-NAS, an modern mannequin for object detection. The article begins with a concise exploration of the mannequin’s structure, adopted by an in-depth clarification of the Auto NAC idea. Moreover, the article gives a comparative evaluation of YOLO-NAS inside the broader YOLO sequence. In direction of the conclusion, readers can discover a demonstration utilizing the Paperspace platform, together with key highlights of YOLO-NAS.
YOLO-NAS – A New Object Detection Basis Mannequin
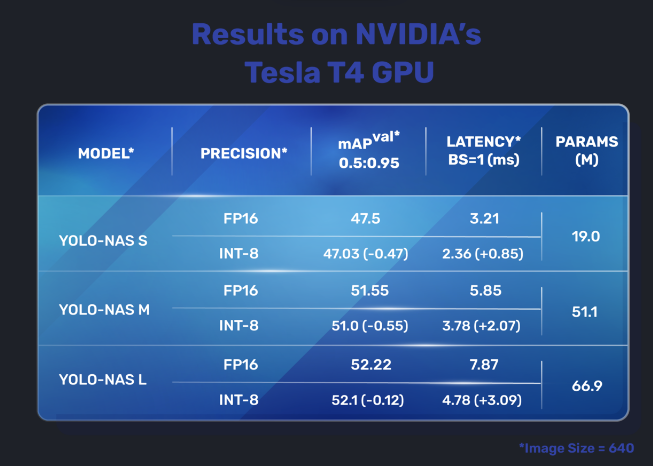
YOLO-NAS outshines its predecessors with a 20.5% efficiency increase over YOLOv7, barely surpassing YOLOv5 by over 11%, and displaying a 1.75% enchancment in comparison with YOLOv8. Developed by Deci, YOLO-NAS stands as the newest addition to the YOLO mannequin sequence, boasting its quickest mannequin with a latency of simply 2.36 milliseconds and a MAP (imply common precision) of 47.
Deci designed YOLO-NAS to beat key limitations seen in present YOLO fashions, addressing points like inadequate quantization assist and accuracy-latency trade-offs. This effort has considerably expanded the capabilities of real-time object detection, pushing the boundaries of what is doable within the subject.
NAS fashions undergoes pre-training on the Object 365 dataset, consisting of 365 classes with an unlimited assortment of two million photos and 30 million bounding containers. Subsequently, they endure coaching on 118,000 pseudo-labeled photos extracted from Coco unlabeled photos. The coaching course of is additional enriched by means of the mixing of data distillation and Distribution Focal Loss (DFL). Throughout pre-training, data distillation is employed to boost efficiency. A instructor mannequin generates predictions, serving as tender targets for the coed mannequin, which strives to match them whereas adjusting for the unique labeled knowledge. This method mitigates overfitting and enhances accuracy, notably helpful in eventualities the place labeled knowledge is proscribed. Moreover, the mixing of distribution focal loss (DFL) additional refines the coaching course of, addressing class imbalance and boosting detection accuracy for underrepresented courses.
YOLO-NAS has three fashions. The small mannequin, medium and huge mannequin. These fashions are additionally quantized into INT8. The quantized fashions have a really small drop in accuracy.
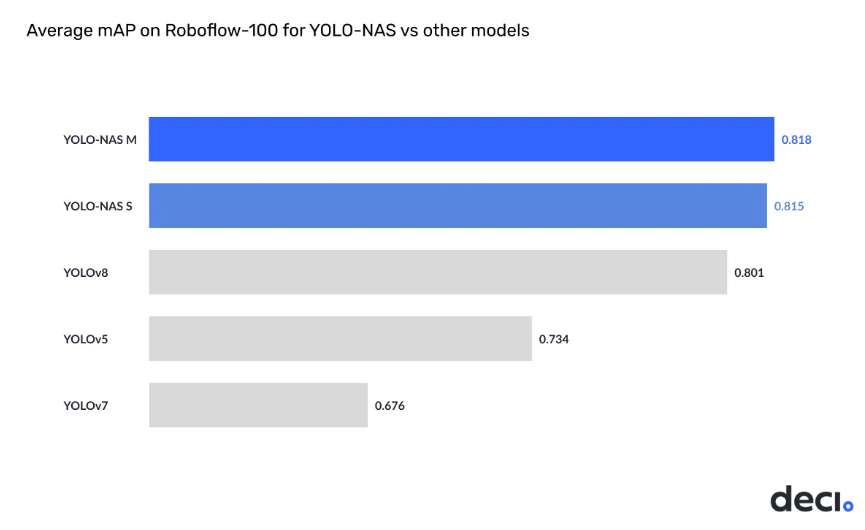
Neural Structure Search
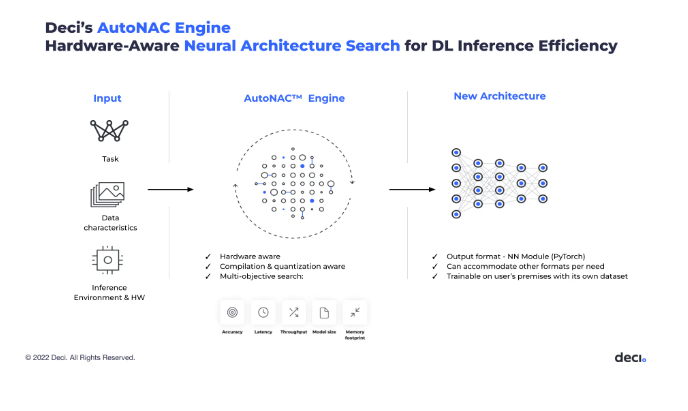
YOLO-NAS employs optimization algorithms like Automated Neural Structure Development or AutoNAC. The Automated Neural Structure Development (AutoNAC) know-how is sort of a good software that makes essentially the most out of any pc {hardware}. It has an element referred to as Neural Structure Search (NAS), which may enhance, how rapidly a pc understands and processes info (throughput), how briskly it responds (latency), and the way effectively it makes use of reminiscence. This NAS part redesigns an already skilled pc mannequin to work even higher on particular varieties of {hardware}, all whereas preserving its fundamental accuracy.
AutoNAC is a particular know-how developed by Deci, and it is what makes their Deep Studying Acceleration Platform work properly. This know-how will increase the inference efficiency of a skilled mannequin on a particular {hardware}, optimizing throughput, latency, and reminiscence utilization whereas sustaining baseline accuracy. AutoNAC is a proprietary know-how powering Deci’s Deep Studying Acceleration Platform.
A number of quantization-aware RepVGG blocks combines to kind quantization-aware QSP and QCI blocks, creating YOLO-NAS fashions by means of permutations as depicted within the video. These blocks are based mostly on a technique proposed by Chu et al., making certain minimal accuracy loss in post-training quantization.
AutoNAC Structure
Efficiency of YOLO-NAC
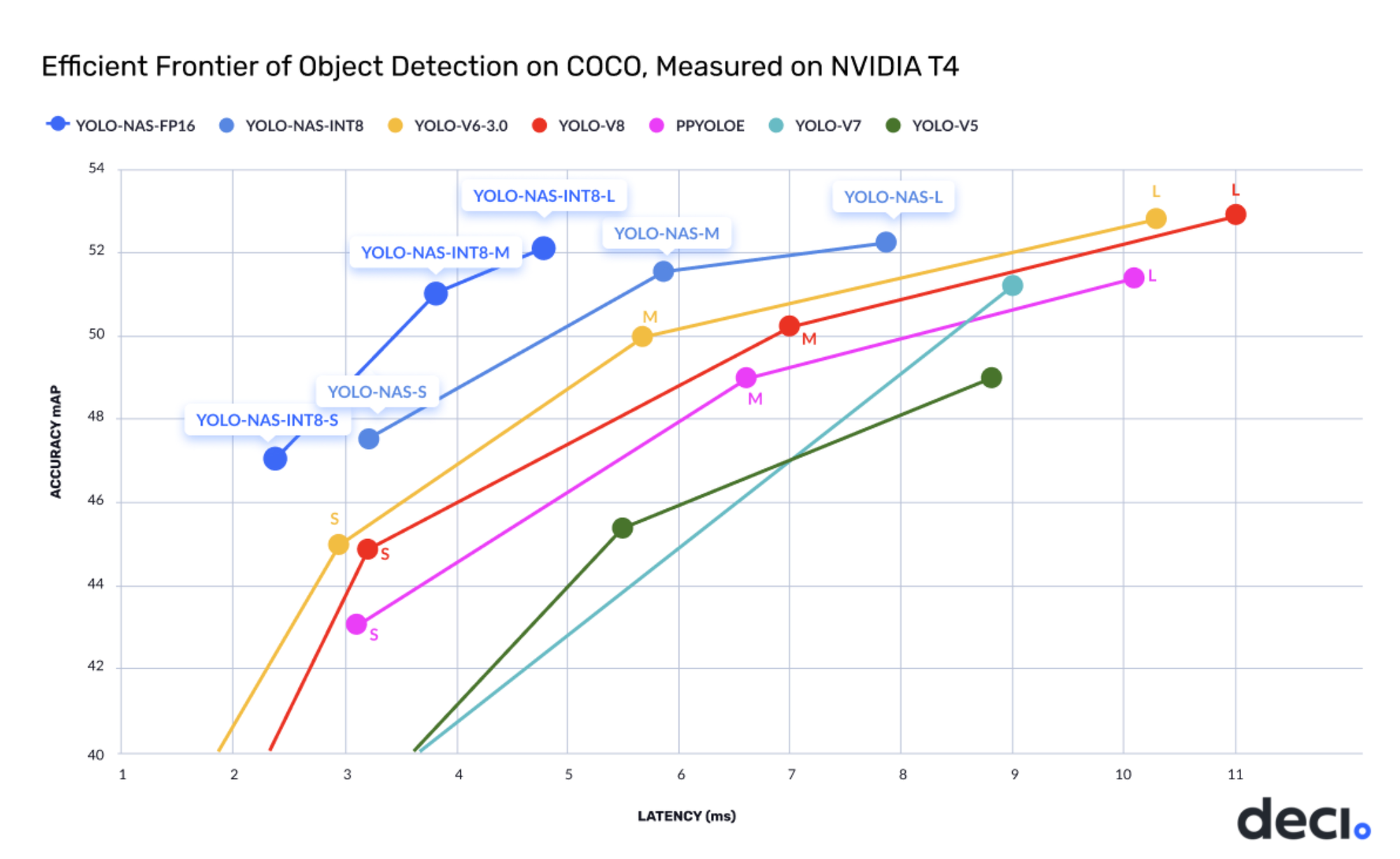
The YOLO-NAS showcases State-of-the-Artwork efficiency, outperforming different fashions corresponding to YOLOv5, YOLOv6, YOLOv7, and YOLOv8, with an unparalleled mixture of accuracy and pace. Inspecting the beneath graph reveals that each one iterations of YOLO-NAS—small, medium, and huge, each with and with out quantization—achieves spectacular accuracy. Moreover, the Imply Common Precision (MAP) worth has notably elevated in comparison with the earlier State-of-the-Artwork mode.
Within the subject of AI analysis, the rising complexity of deep studying fashions has spurred a surge in various purposes. Nonetheless, deploying these fashions on cloud platforms requires a big computational assets, translating to substantial prices for builders. Paperspace, providing entry to exceptionally quick GPUs and an excellent developer expertise, enabling the development of fashions at minimal expense and trouble.
Implementation of YOLO-NAS utilizing Paperspace
Deliver this mission to life
Let’s examine how YOLO NAS performs. On this pocket book, we’ll:
- Set up YOLO NAS and all its dependencies,
- Obtain the fashions and examine the architectures,
- Run inference on photos in addition to movies.
Earlier than we begin, allow us to discover out what sort of GPU we’re working on our platform.
!nvidia-smi
As proven within the screenshot we’re utilizing the NVIDIA RTX A6000 GPU.
The A6000, geared up with 336 Tensor Cores, contributes to sooner and extra environment friendly processing, rendering the A6000 notably well-suited for deep studying purposes. The GPU has a Reminiscence bandwidth of 768 GB/s and has a excessive system interface of PCI Categorical 4.0 x16 making it the third strongest GPU of Paperspace platform. To entry the pocket book click on the hyperlink supplied within the article.
- Set up the mandatory packages utilizing pip, YOLO-NAS mannequin reside inside super-gradients bundle.
!pip set up super-gradients- Import the packages. The SuperGradients mannequin operate features a operate referred to as GET, designed to facilitate the downloading of fashions. Customers have the pliability to pick their most well-liked mannequin together with the corresponding pre-trained weights. Subsequently, load the chosen mannequin onto the GPU for additional use.
import super_gradients
yolo_nas = super_gradients.coaching.fashions.get("yolo_nas_l", pretrained_weights="coco").cuda()
#yolo_nas_m
#yolo_nas_s
- To view the abstract of the mannequin we want ‘torch’
!pip set up torchinfoWith the ‘abstract’ operate, when any mannequin is handed, given an enter measurement, the operate returns the mannequin structure. Let’s examine what YOLO-NAS mannequin structure is.
from torchinfo import abstract
abstract(mannequin=yolo_nas_l,
input_size=(16, 3, 640, 640),
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)
Within the display shot of Mannequin abstract we are able to see the entire variety of parameters of a big mannequin.
- Subsequent, allow us to strive the working inference on this huge YOLO-NAS mannequin. A handy operate named “predict,” the place the picture together with a confidence threshold is handed. This may present us with the inference output.
url = "https://previews.123rf.com/photos/freeograph/freeograph2011/freeograph201100150/158301822-group-of-friends-gathering-around-table-at-home.jpg"
yolo_nas_l.predict(url, conf=0.25).present()present() will show the inference output. That is what it appears to be like like.

Now to run inference on movies, we use the identical operate predict and go the video path together with the output path to save lots of the video.
input_video_path = "/notebooks/input_video/visitors.mp4"
output_video_path = "/notebooks/output_video/detections.mp4"
gadget=0
yolo_nas_l.to(gadget).predict(input_video_path).save(output_video_path)We extremely advocate to take a look at our earlier articles on YOLO fashions for an intuitive understanding of YOLO fashions like PP-YOLO, YOLOv5, YOLOv8, and extra
Key Options of YOLO-NAS
- YOLO-NAS is totally different from different object detection fashions available in the market by offering the optimum stability between accuracy and latency.
- Three variations of YOLO-NAS have been launched by Deci i.e., small, medium, and huge with and with out quantization.
- YOLO-NAS, have efficiently integrated quantization-aware blocks and selective quantization to make sure optimized efficiency.
- Using AutoNAC optimization, YOLO-NAS undergoes pre-training on well-known datasets like COCO, Objects365, and Roboflow 100. This pre-training enhances its suitability for object detection duties in manufacturing environments, making it extremely efficient for downstream purposes.
- Ultralytics has simplified the mixing of YOLO-NAS fashions into Python purposes by means of the ultralytics Python bundle. This bundle gives a user-friendly Python API, streamlining the mixing course of.
- Submit releasing YOLO-NAS, Deci has efficiently launched YOLO-NAS Pose Estimation-A brand new SOTA pose estimation basis mannequin. YOLO-NAS pose structure relies on the YOLO-NAS structure which incorporates comparable spine and neck designs.
- What distinguishes YOLO-NAS Pose is its modern head design tailor-made for a multi-task goal, enabling simultaneous single-class object detection (particularly, detecting an individual) and pose estimation for that particular person.
Very quickly we’ll deliver an in depth article on YOLO-NAS pose so keep tuned for extra articles on YOLO sequence!!
Conclusions
On this article we launched YOLO-NAS, a singular SOTA mannequin for object detection by Deci. The mannequin’s superior structure incorporates state-of-the-art strategies, together with consideration mechanisms, quantization-aware blocks, and reparametrization throughout inference, enhancing its object detection capabilities. These components collectively contribute to YOLO-NAS’s excellent efficiency in detecting objects with various sizes and complexities, establishing a brand new benchmark for varied business use instances.
This groundbreaking development in object detection has the potential to encourage novel analysis and rework the sphere, empowering machines to intelligently and autonomously understand and work together with the world.
We hope you loved the article with the Paperspace demo.
Thanks for studying!!